Download as PDF, PPTX




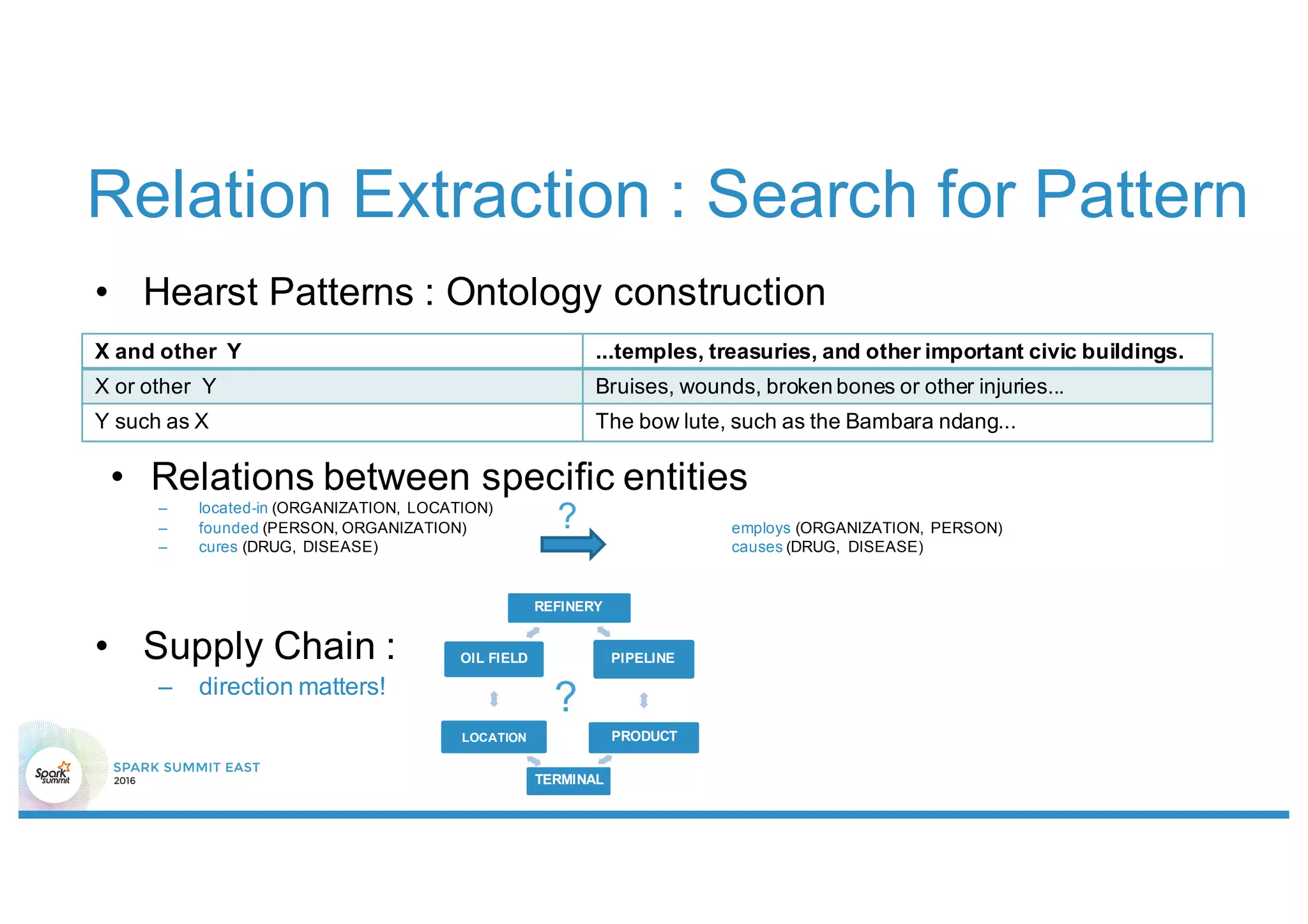
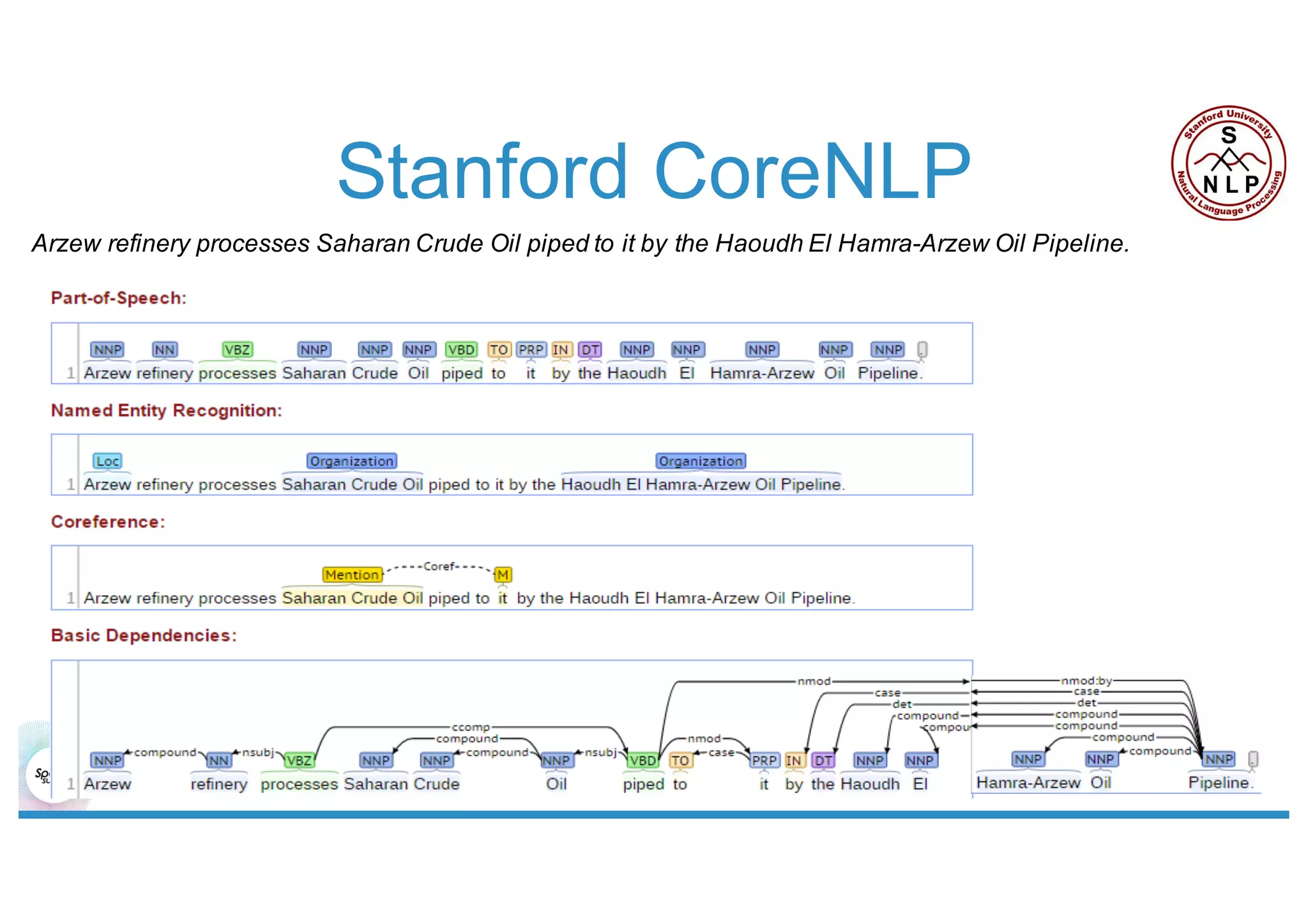
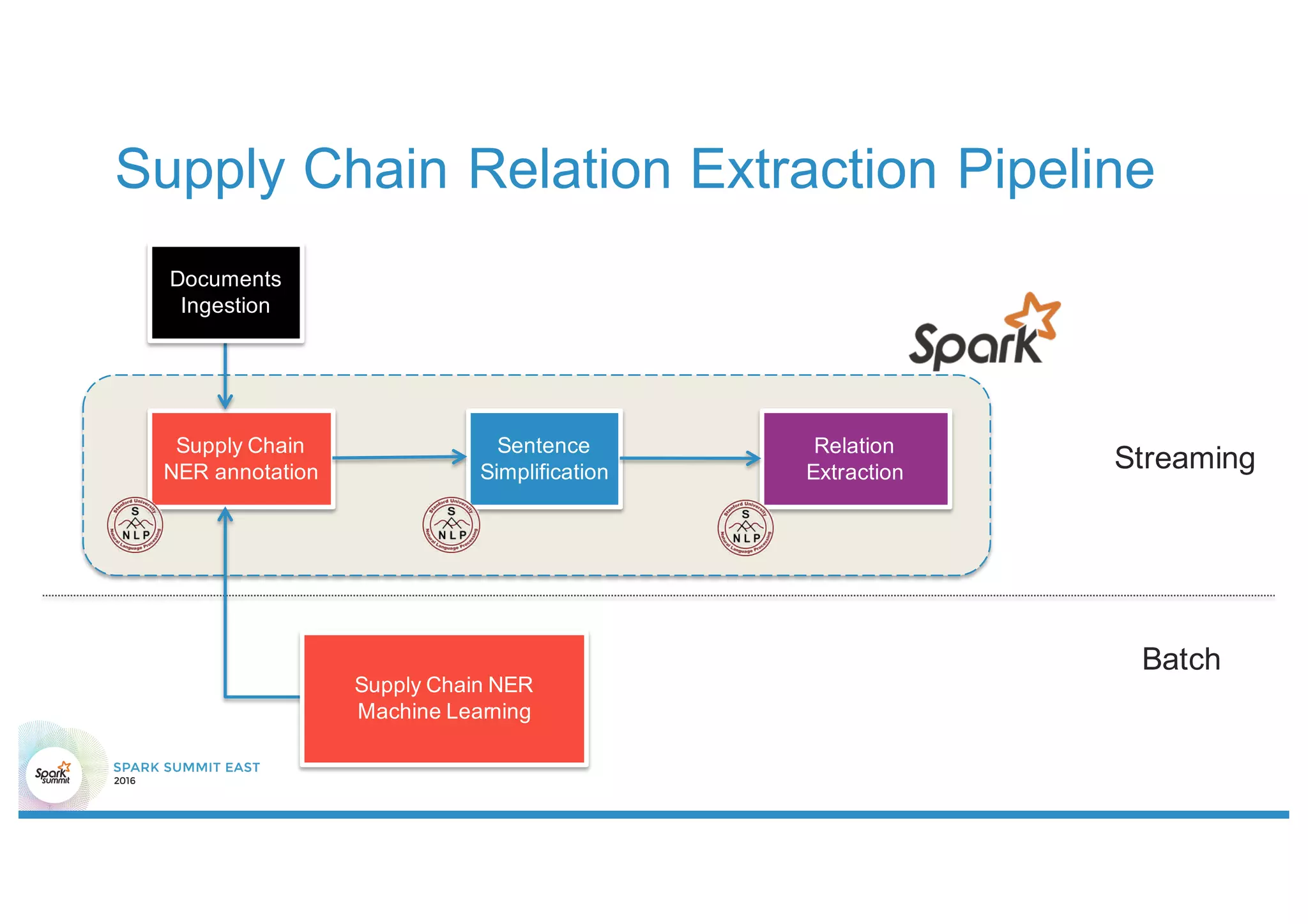


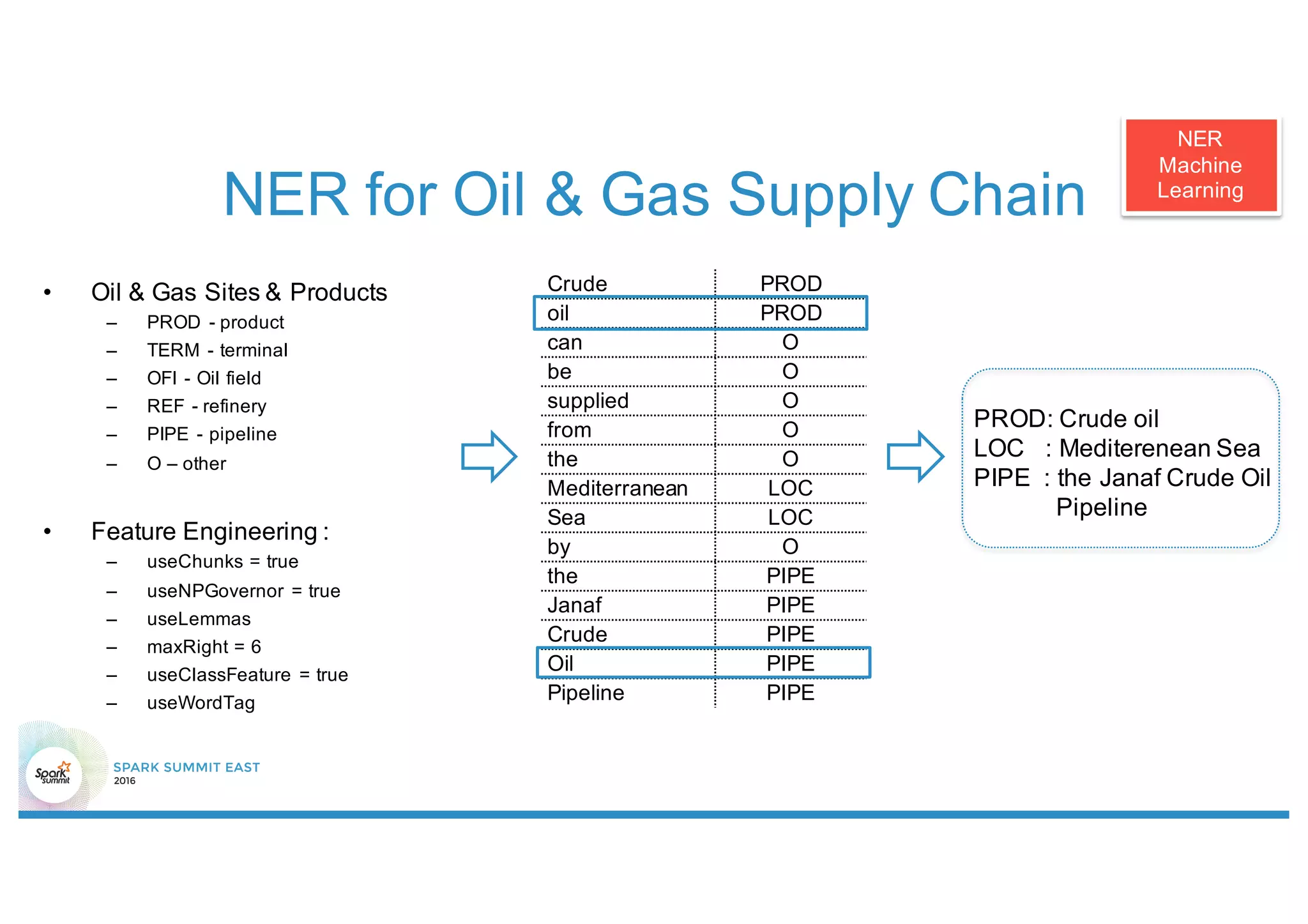
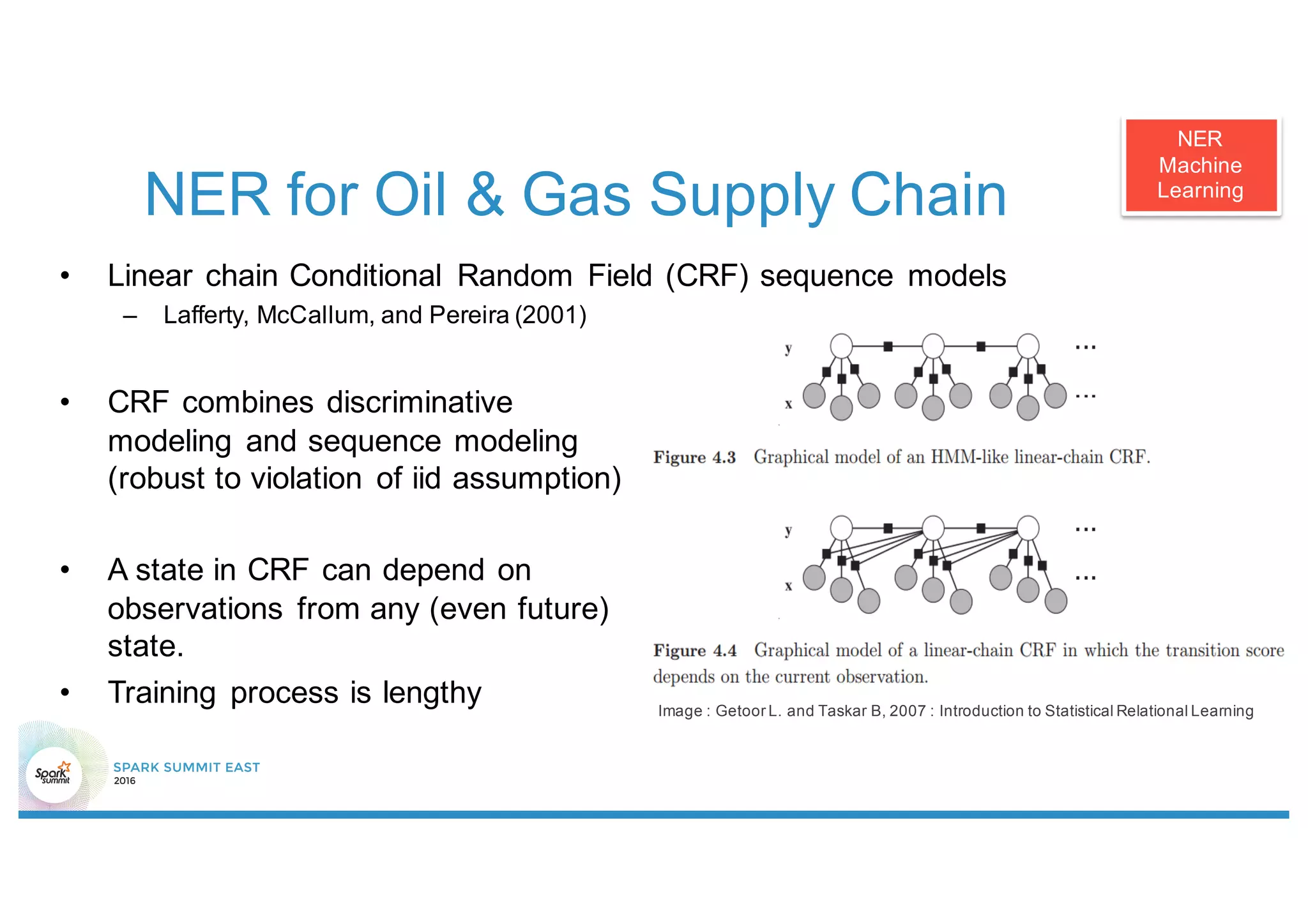
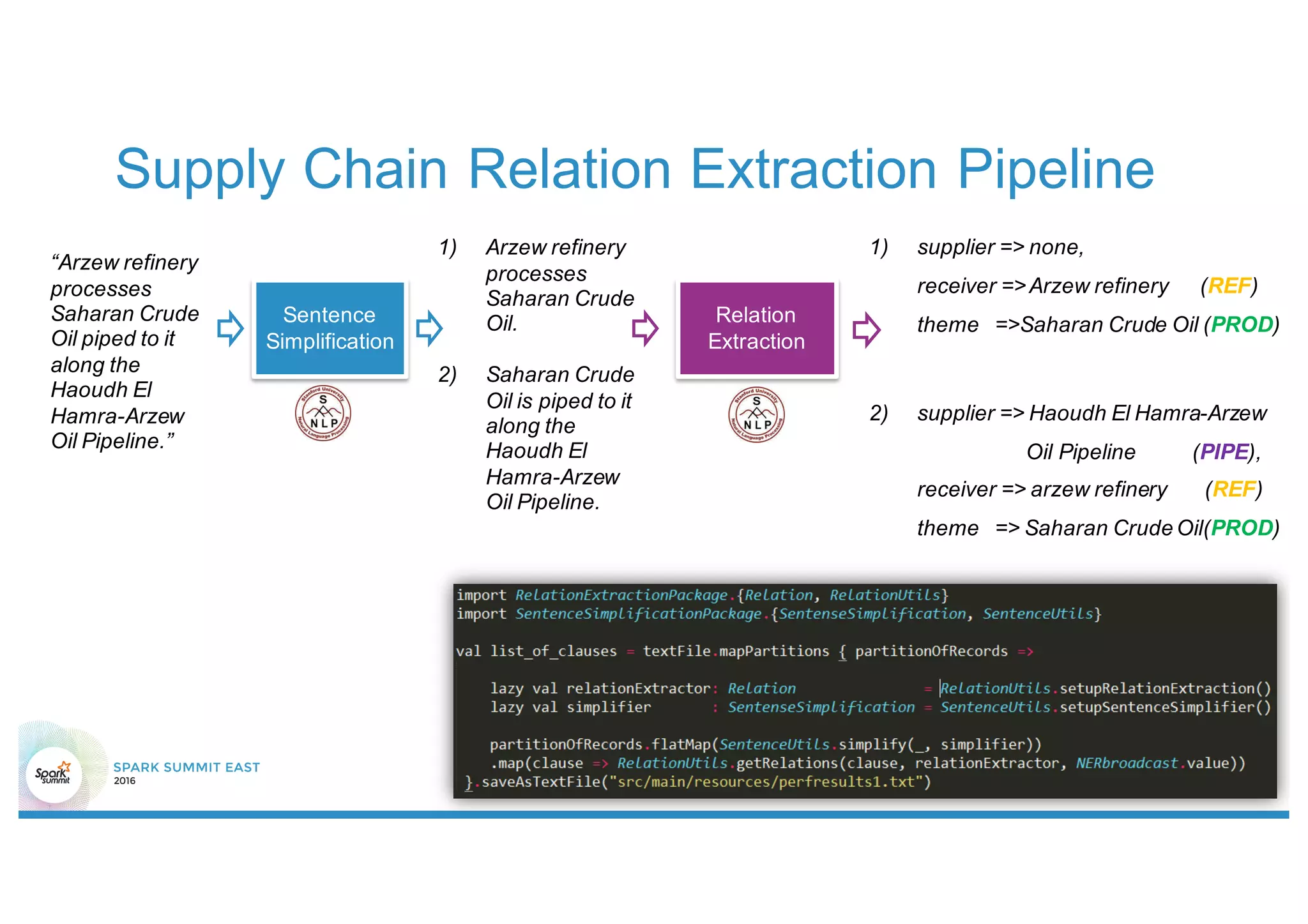
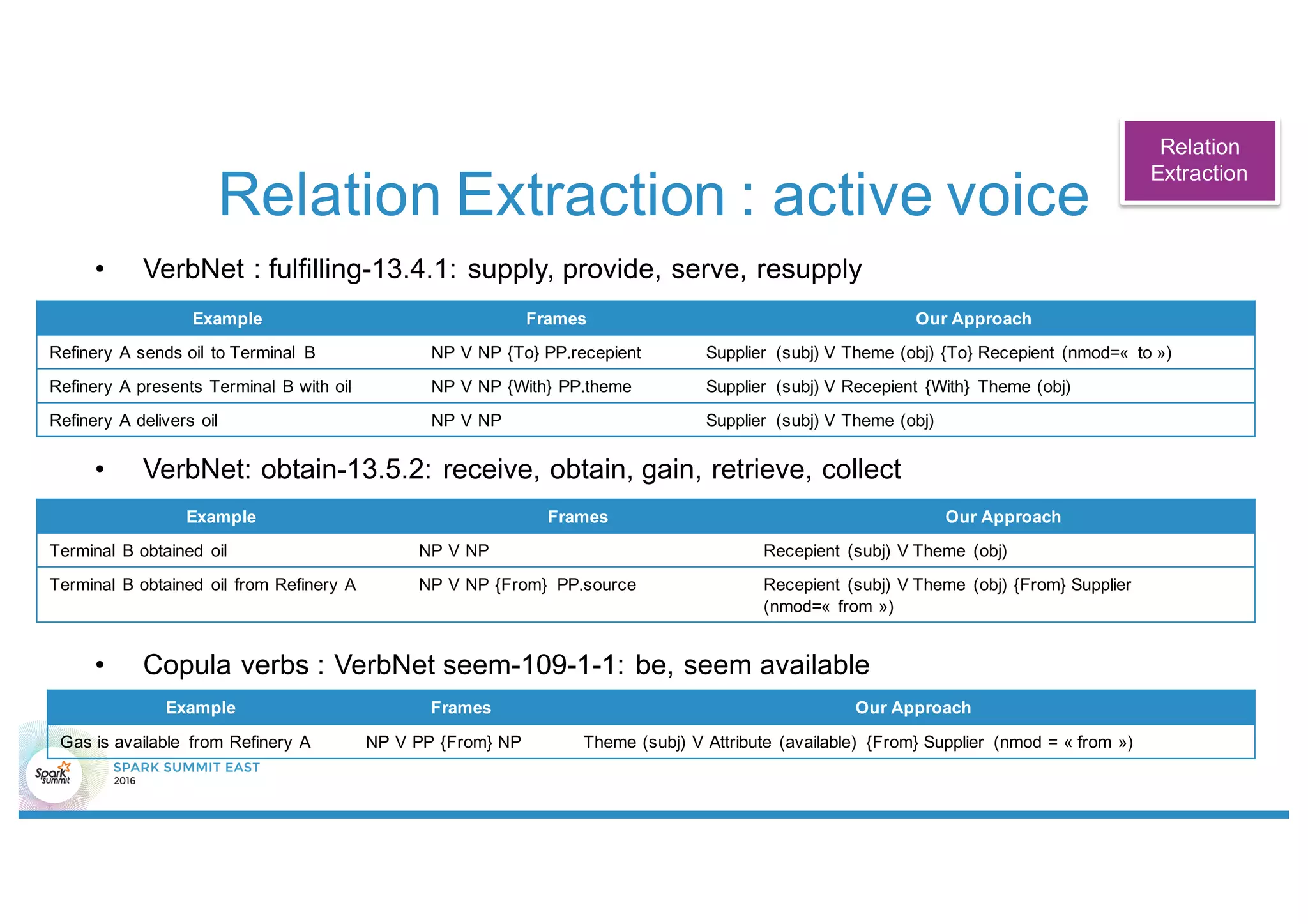

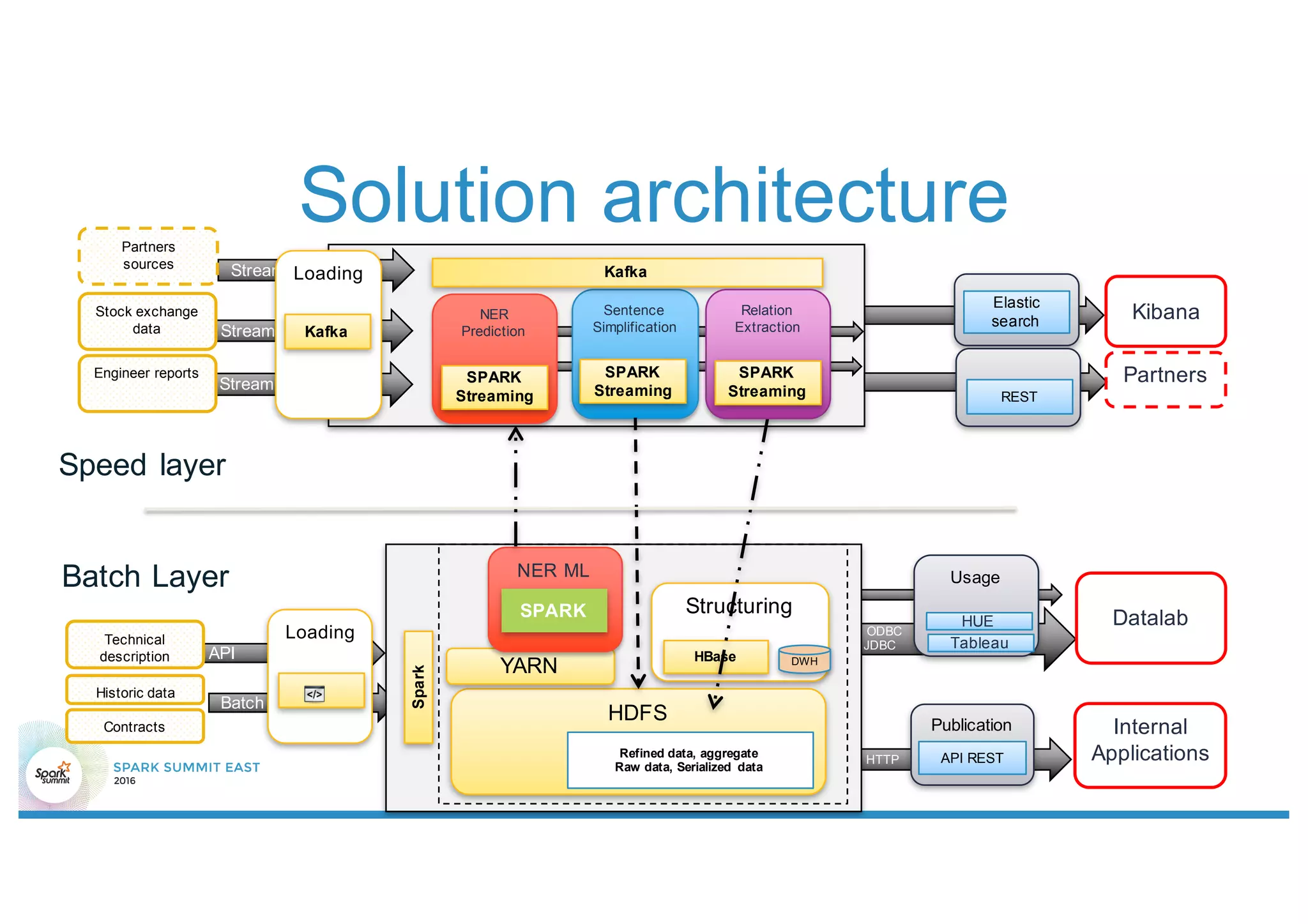

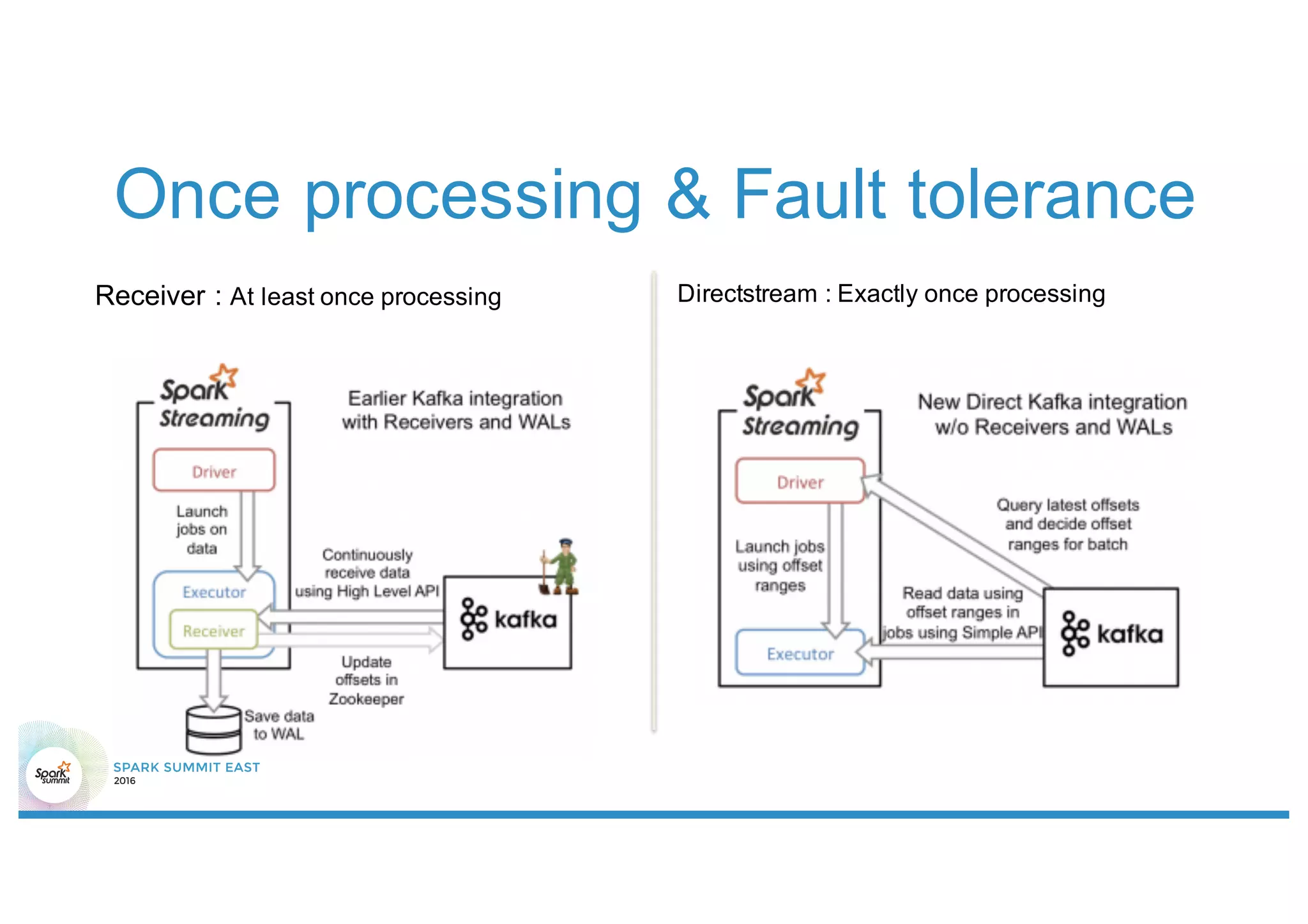
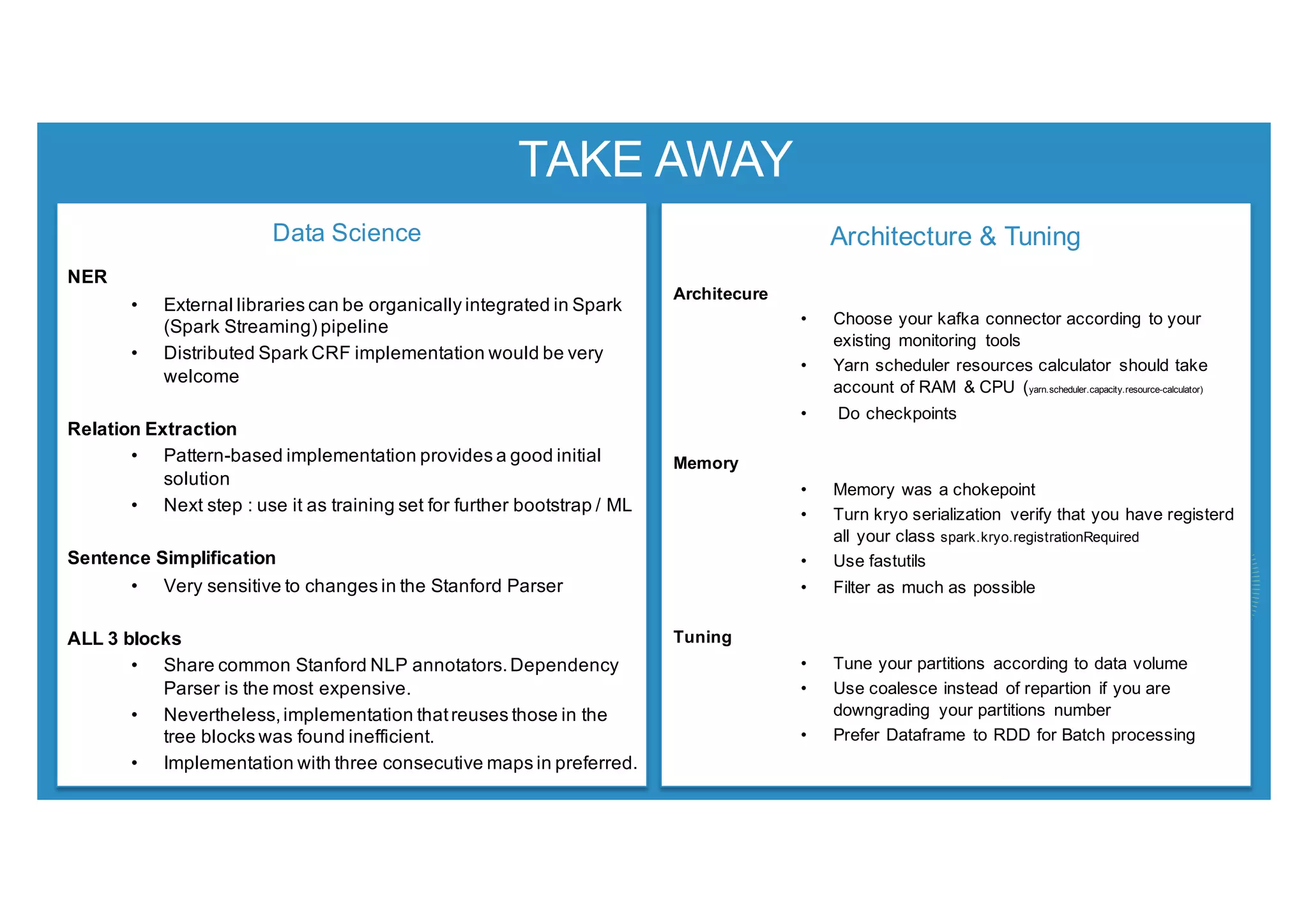


This document discusses using Stanford NLP and Spark to extract relationships from unstructured text. It presents a pipeline for annotating entities in oil and gas supply chain text using NER, extracting relationships using pattern matching, and simplifying sentences. The pipeline is implemented using Spark for scalability and fault tolerance. Benefits of the approach include code reuse between batch and streaming layers and easy distribution of NLP processing.














































































