Download as PDF, PPTX
























![API
30
B C
A D
F E
A DD
B C
D
E
AA
F
Transition
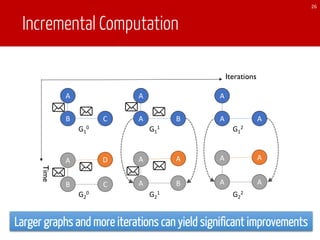
After 11 iteration on graph 2,
Both converge to 3-digit precision
1.224
0.8490.502
2.07
0.8490.502
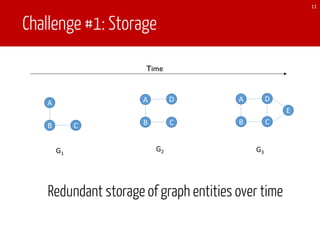
he benefit of PSR computation.
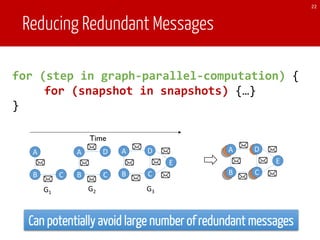
For each iteration of Pregel,
y of a new graph. When it
ations on the current graph,
he new graph after copying
The new computation will
w active set continue message
s a function of the old active
n the new graph and the old
lgorithms (e.g. incremental
ve set includes vertices from
w vertices and vertices with
class Graph[V, E] {
// Collection views
def vertices(sid: Int): Collection[(Id, V)]
def edges(sid: Int): Collection[(Id, Id, E)]
def triplets(sid: Int): Collection[Triplet]
// Graph-parallel computation
def mrTriplets(f: (Triplet) => M,
sum: (M, M) => M,
sids: Array[Int]): Collection[(Int, Id, M)]
// Convenience functions
def mapV(f: (Id, V) => V,
sids: Array[Int]): Graph[V, E]
def mapE(f: (Id, Id, E) => E
sids: Array[Int]): Graph[V, E]
def leftJoinV(v: Collection[(Id, V)],
f: (Id, V, V) => V,
sids: Array[Int]): Graph[V, E]
def leftJoinE(e: Collection[(Id, Id, E)],
f: (Id, Id, E, E) => E,
sids: Array[Int]): Graph[V, E]
def subgraph(vPred: (Id, V) => Boolean,
ePred: (Triplet) => Boolean,
sids: Array[Int]): Graph[V, E]
def reverse(sids: Array[Int]): Graph[V, E]
}
Listing 3: GraphX [24] operators modified to support Tegra’s](https://image.slidesharecdn.com/2312anandiyer-170214210636/85/Time-evolving-Graph-Processing-on-Commodity-Clusters-Spark-Summit-East-talk-by-Anand-Iyer-31-320.jpg)

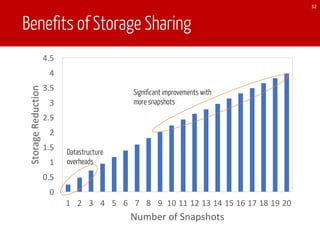
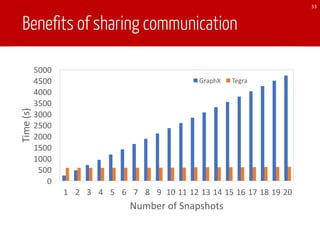
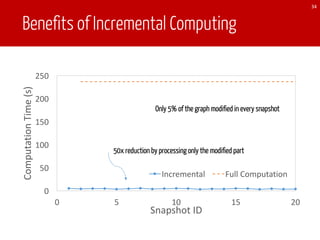



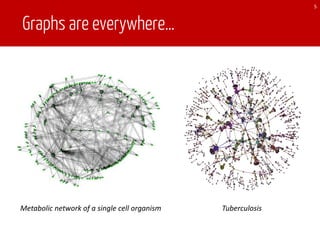
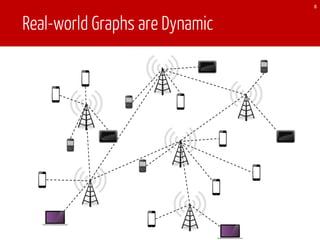
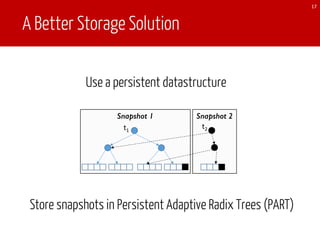
The document discusses TEgra, a framework designed for efficient processing of time-evolving graphs on commodity clusters, addressing challenges in storage, computation, and communication. It highlights the sharing of storage and computation as key strategies for optimizing performance, and presents enhancements to the GraphX API for handling dynamic graphs. The research indicates significant improvements in efficiency through incremental computation and storage sharing based on real-world graph evaluations.








































































































