Downloaded 10 times
















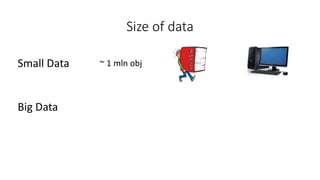
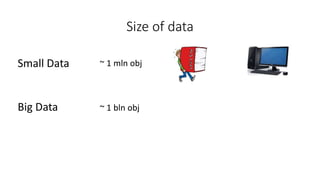
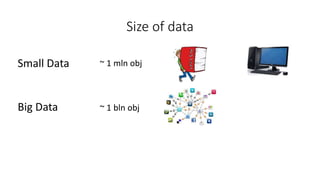



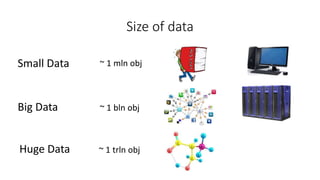
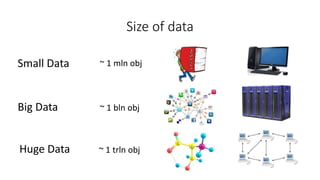
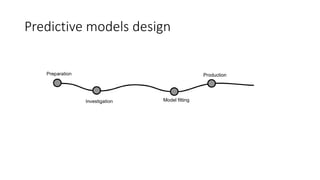
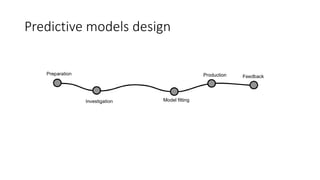
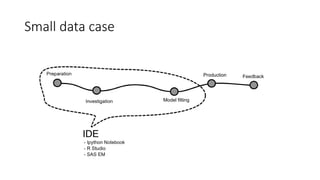
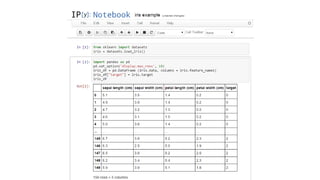
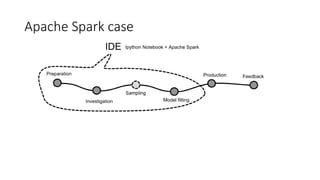
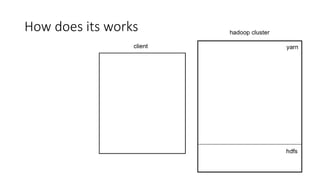

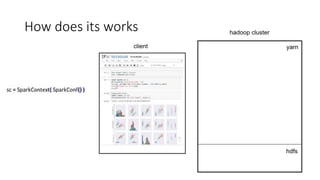

This document discusses using Apache Spark for large scale machine learning problems with big data. It describes how Spark can be used to parallelize training and prediction tasks across large datasets that do not fit in memory. Spark allows using scikit-learn algorithms for machine learning tasks on big data by running the algorithms in a distributed manner across a Spark cluster. It also discusses alternative approaches to large scale machine learning, such as online/partial learning with stochastic gradient descent.









































































