Download as PDF, PPTX

















![automatic joins by column name
{
"table": "dimension_campaigns",
"primary_key": ["campaign_id"]
"joins": [ {"fields": ["campaign_id"]} ]
}
@simeons #EUent1 34
join any table with a campaign_id column](https://image.slidesharecdn.com/w21simsimeonov-171102153045/75/Goal-Based-Data-Production-with-Sim-Simeonov-34-2048.jpg)
![automatic semantic joins
{
"table": "dimension_campaigns",
"primary_key": ["campaign_id"]
"joins": [ {"fields": ["ref:swoop.campaign.id"]} ]
}
join any table with a Swoop campaign ID
@simeons #EUent1 35](https://image.slidesharecdn.com/w21simsimeonov-171102153045/75/Goal-Based-Data-Production-with-Sim-Simeonov-35-2048.jpg)










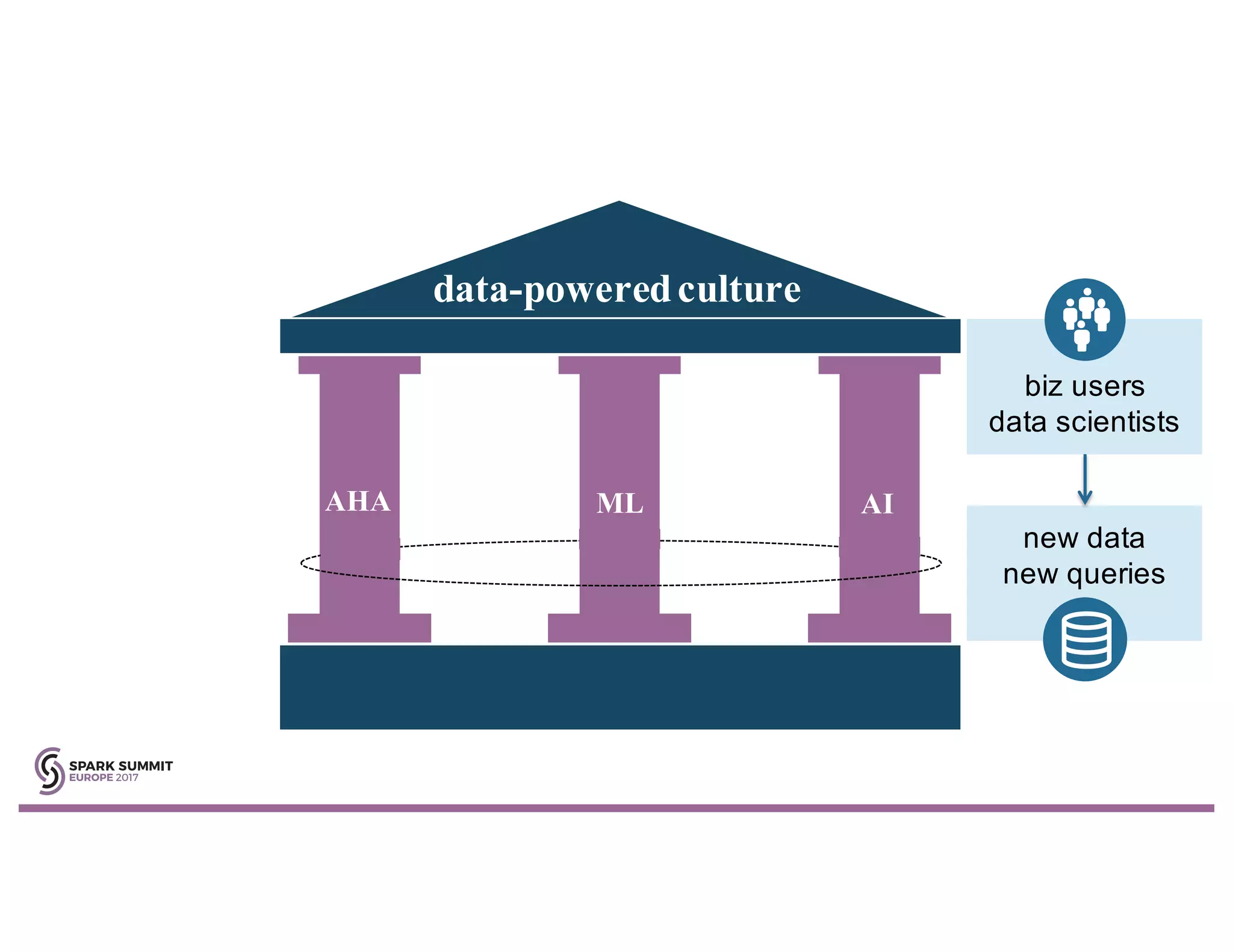
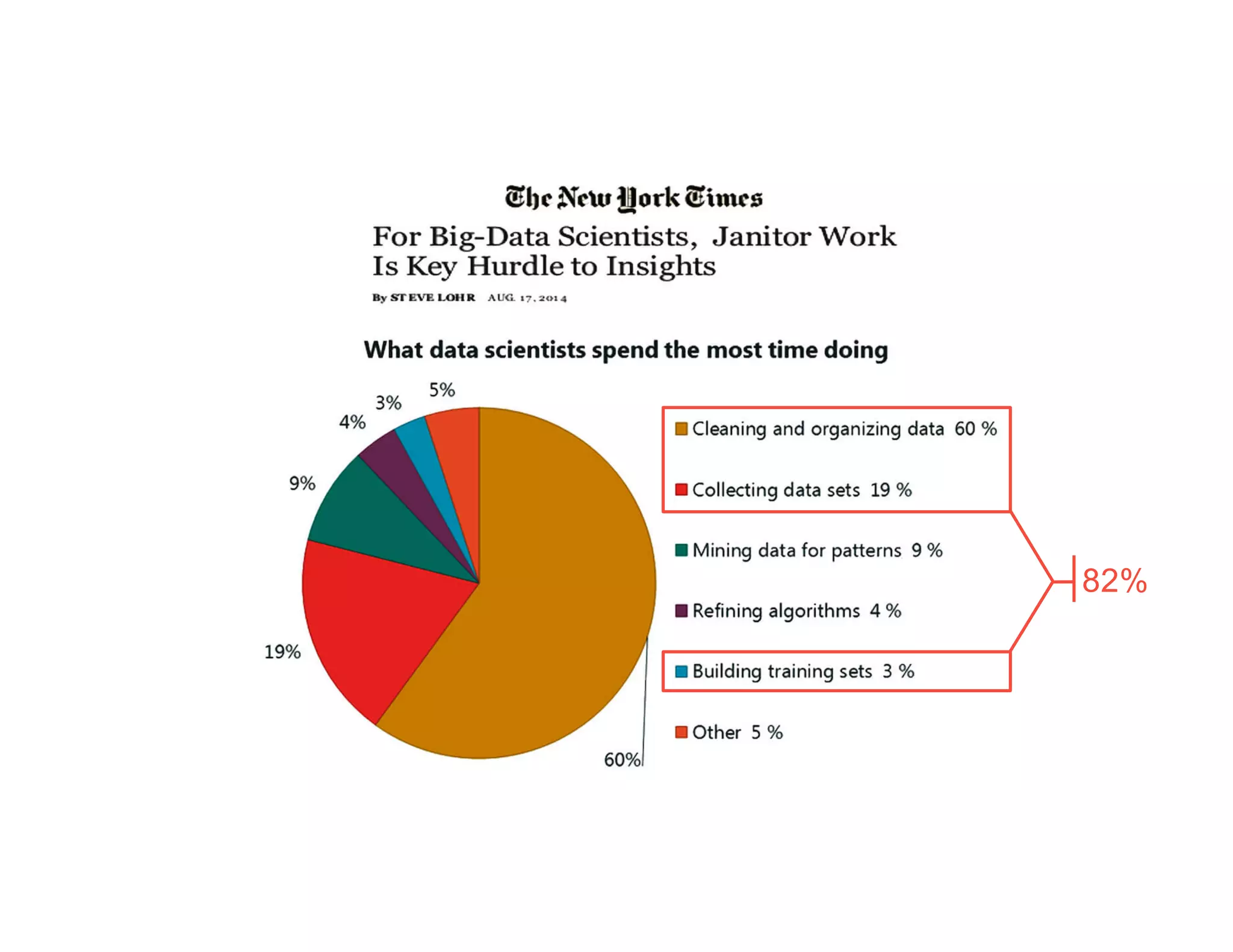
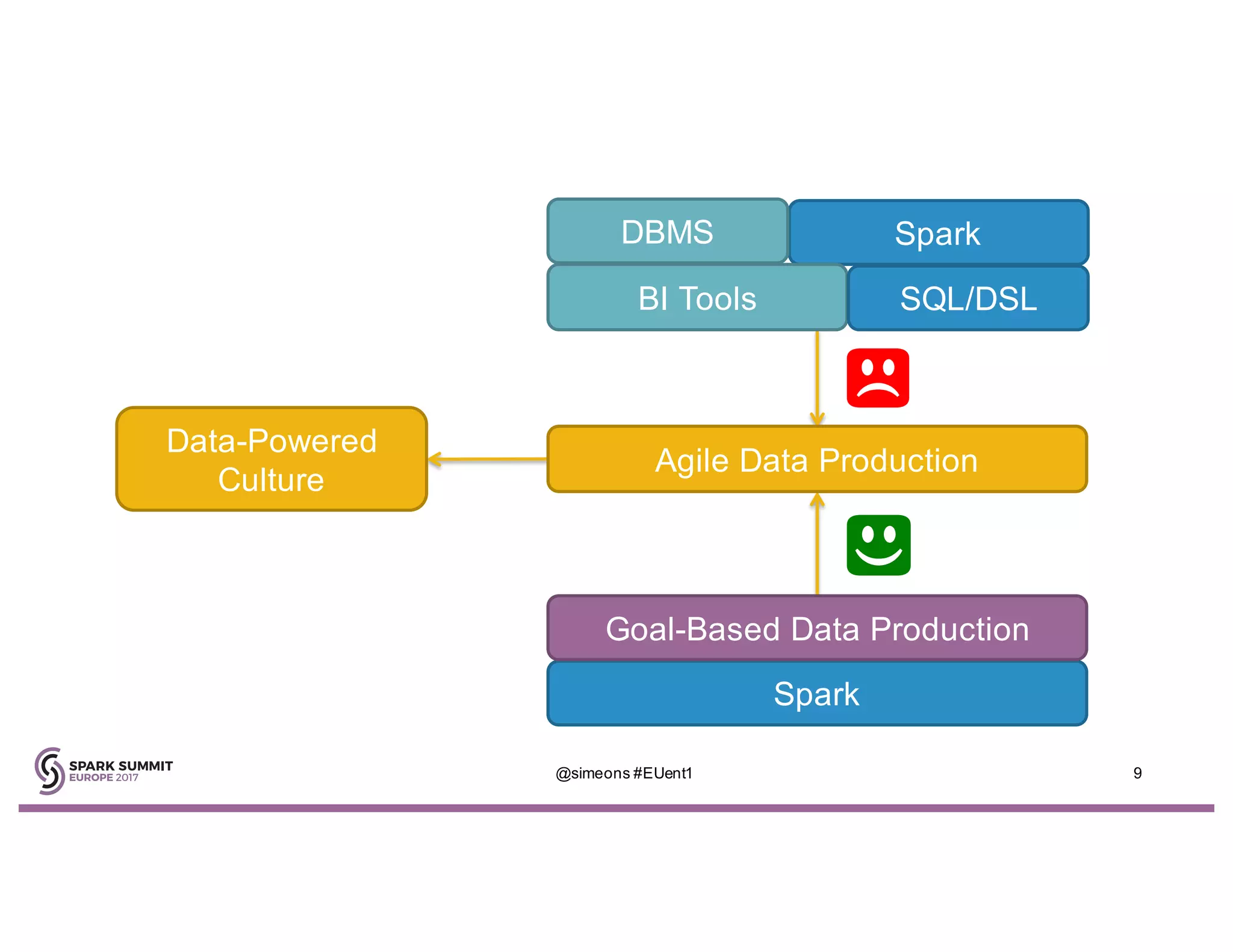
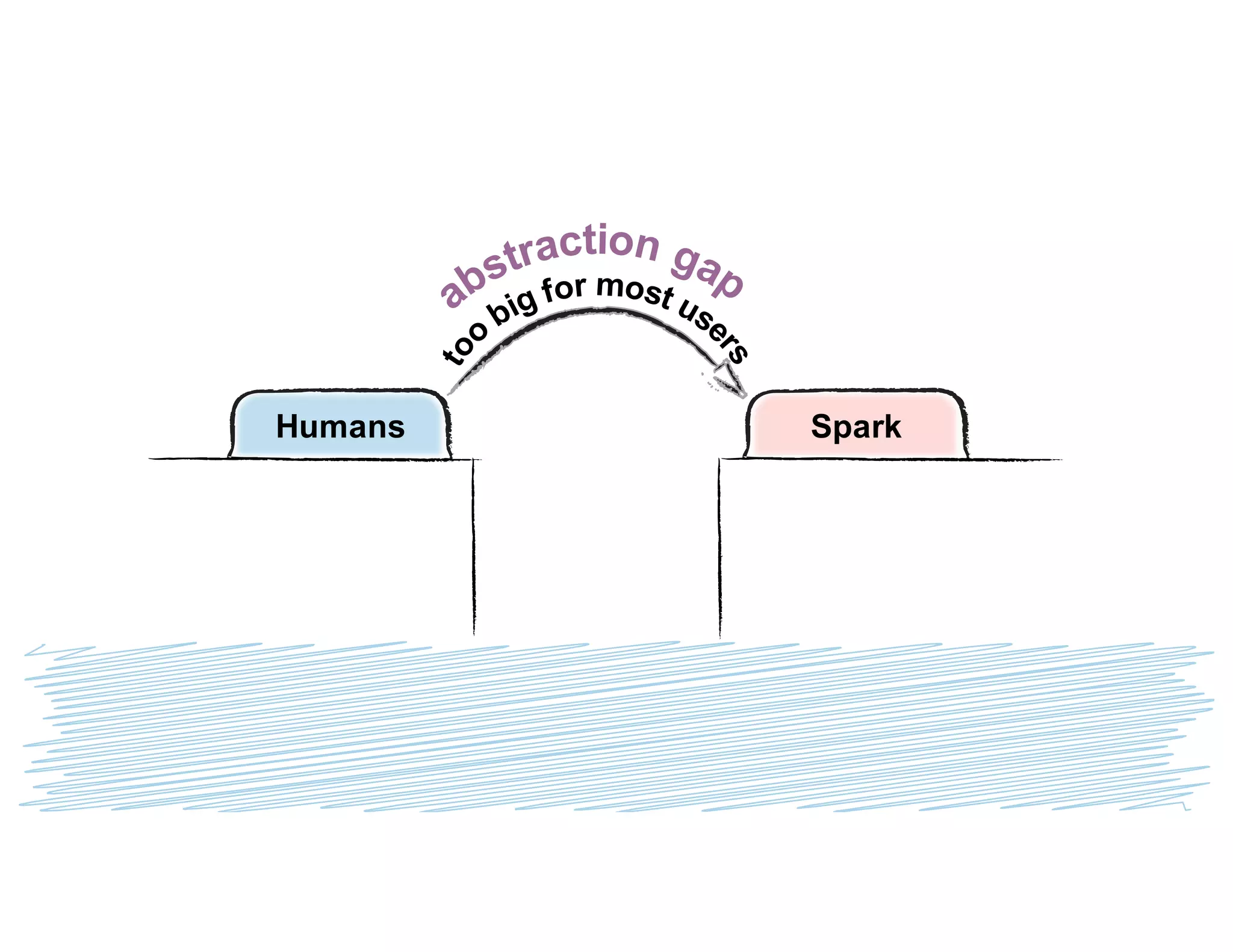
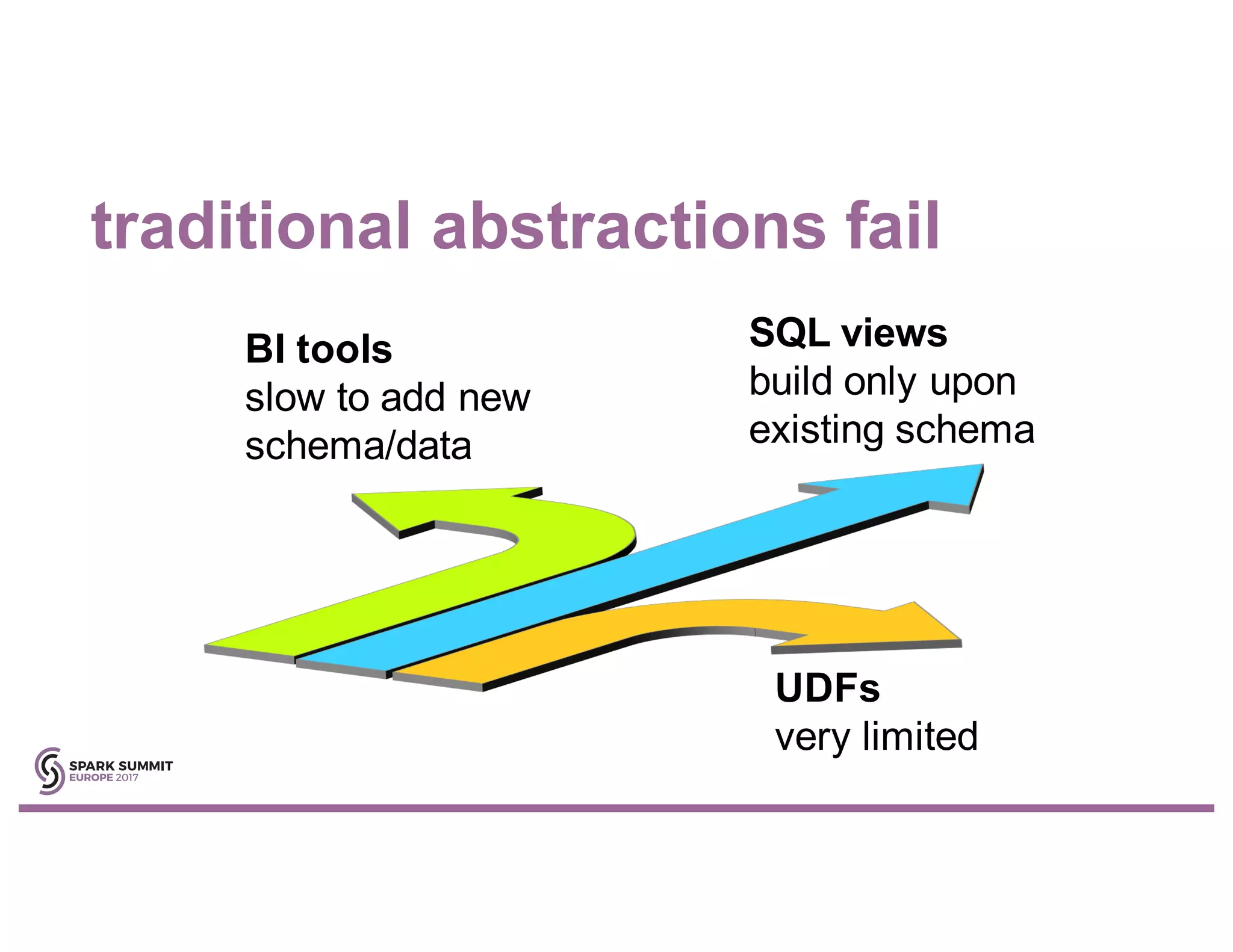
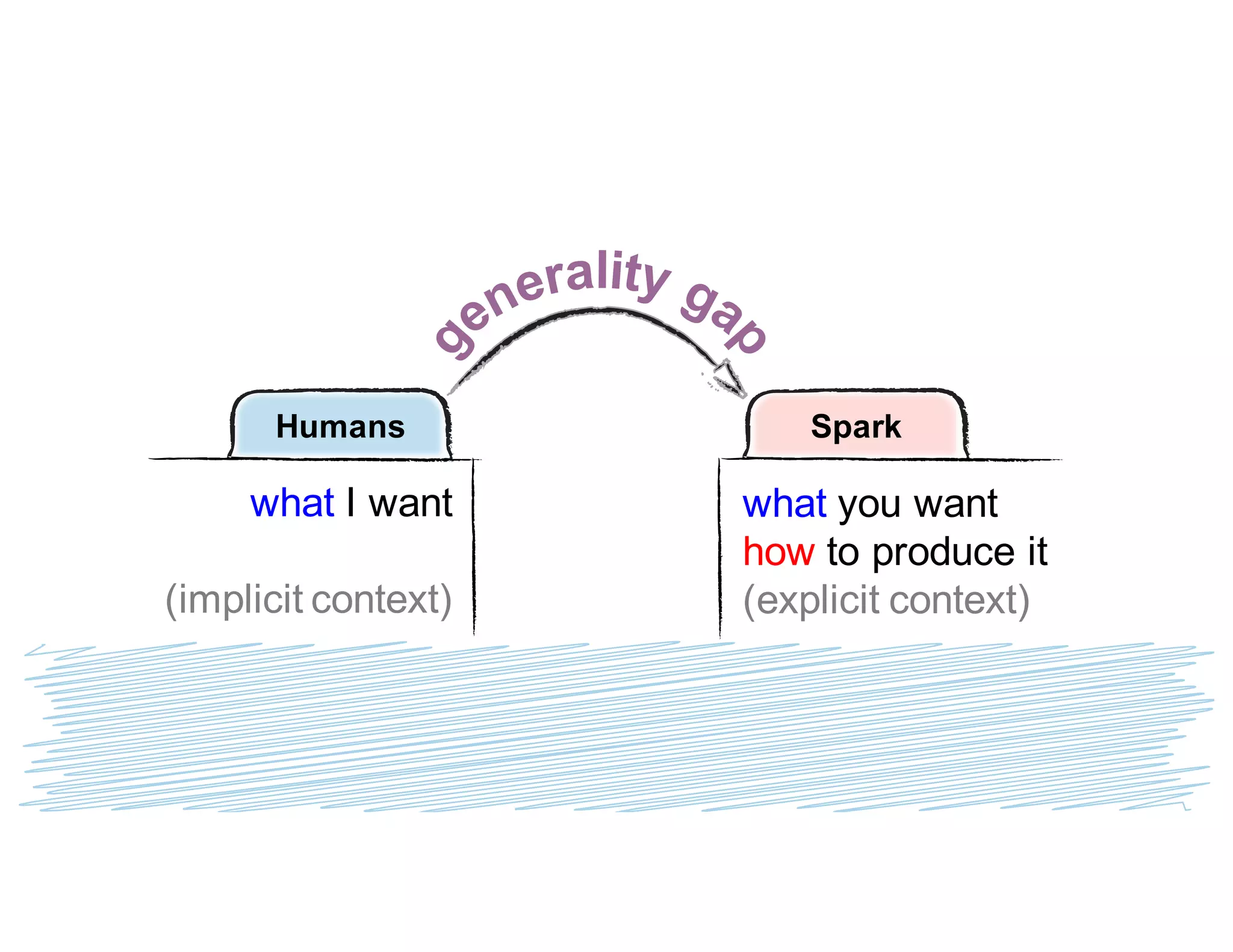
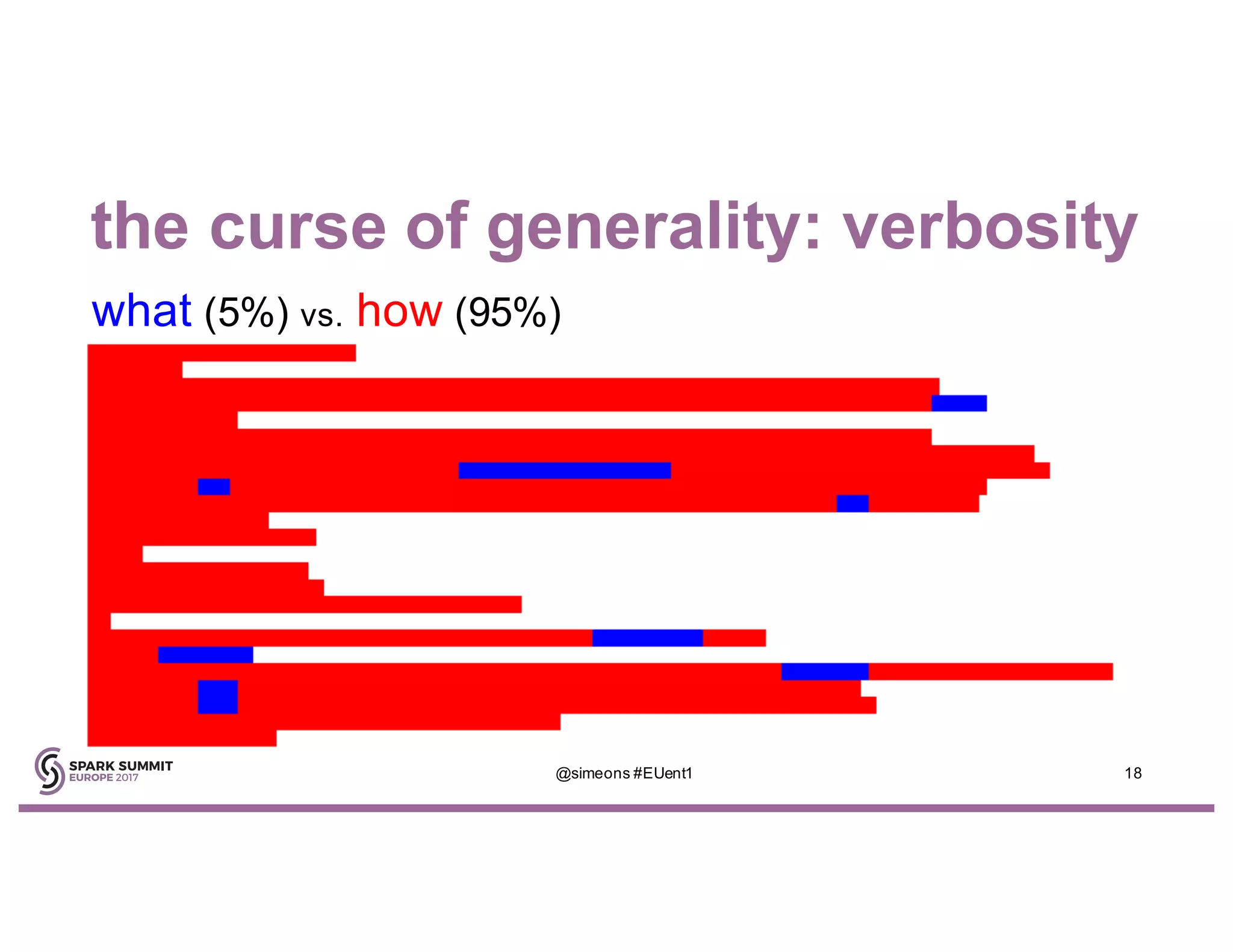
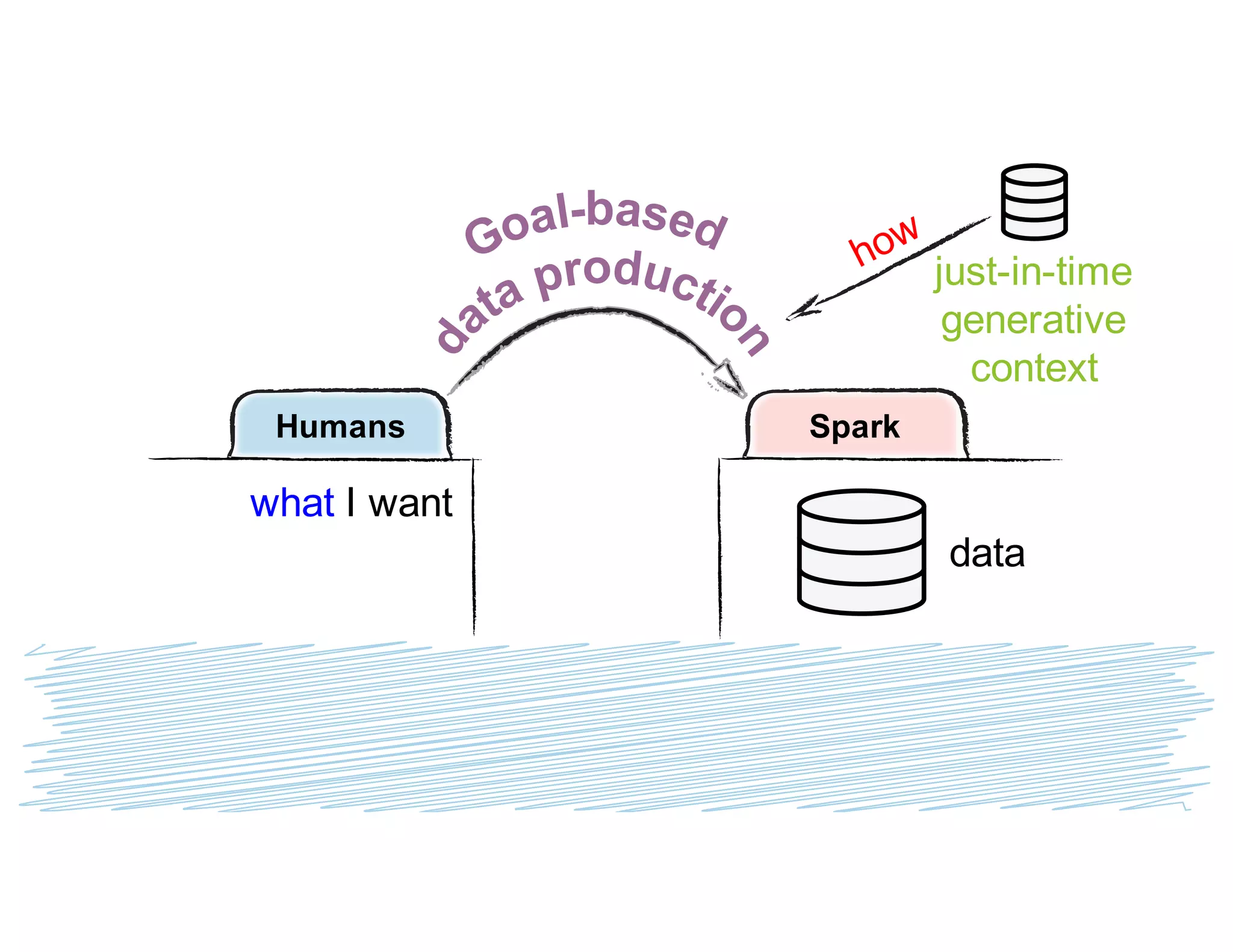
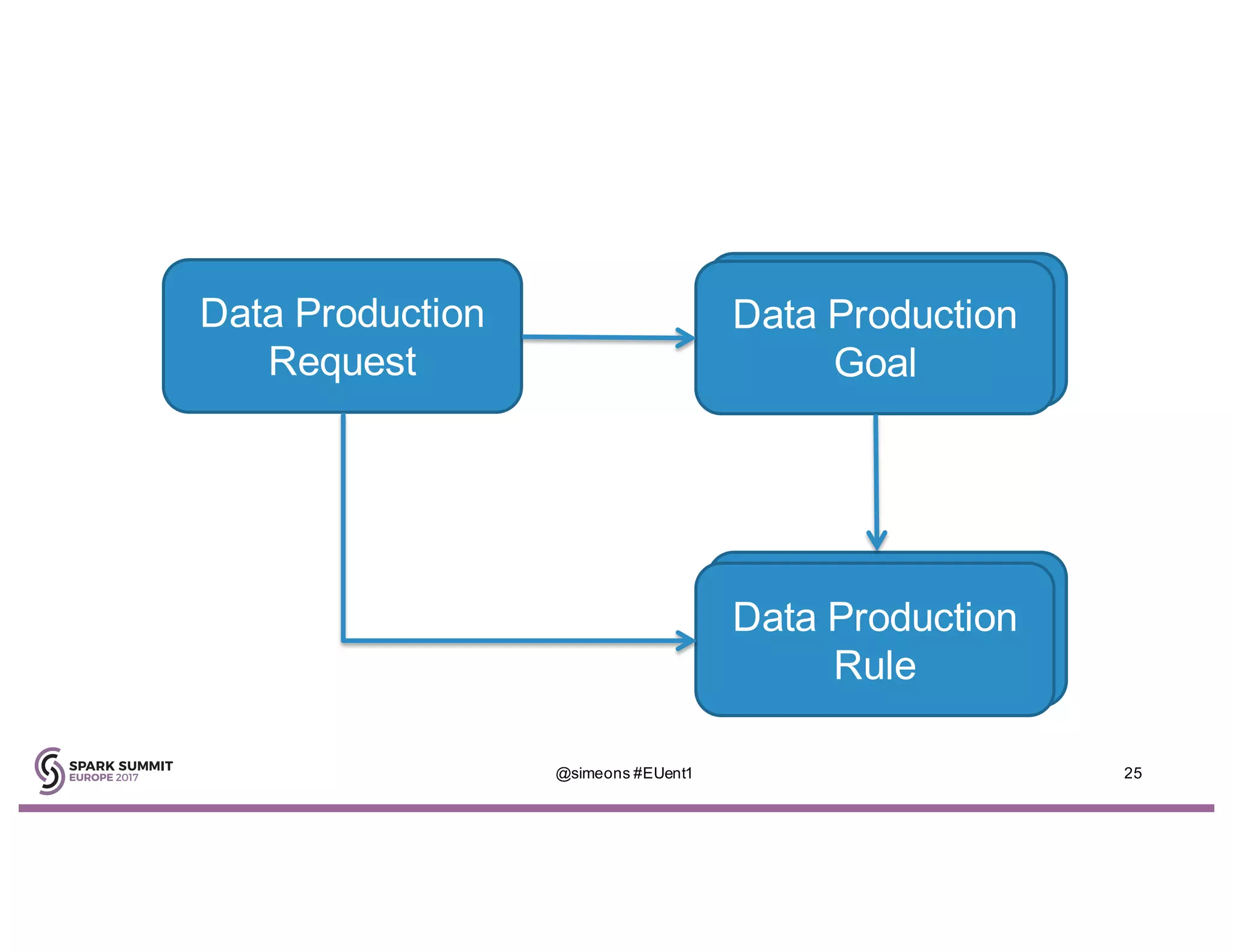
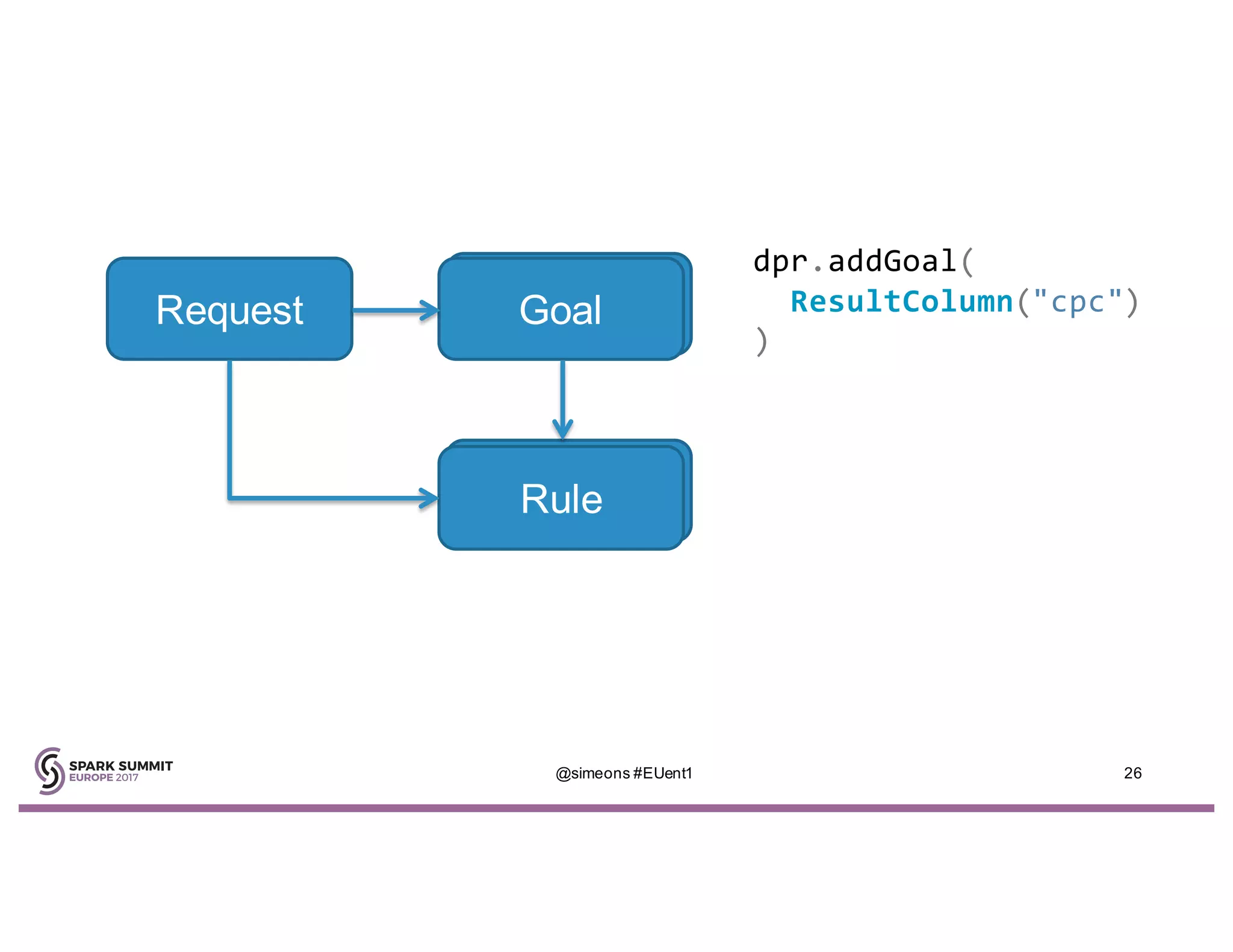
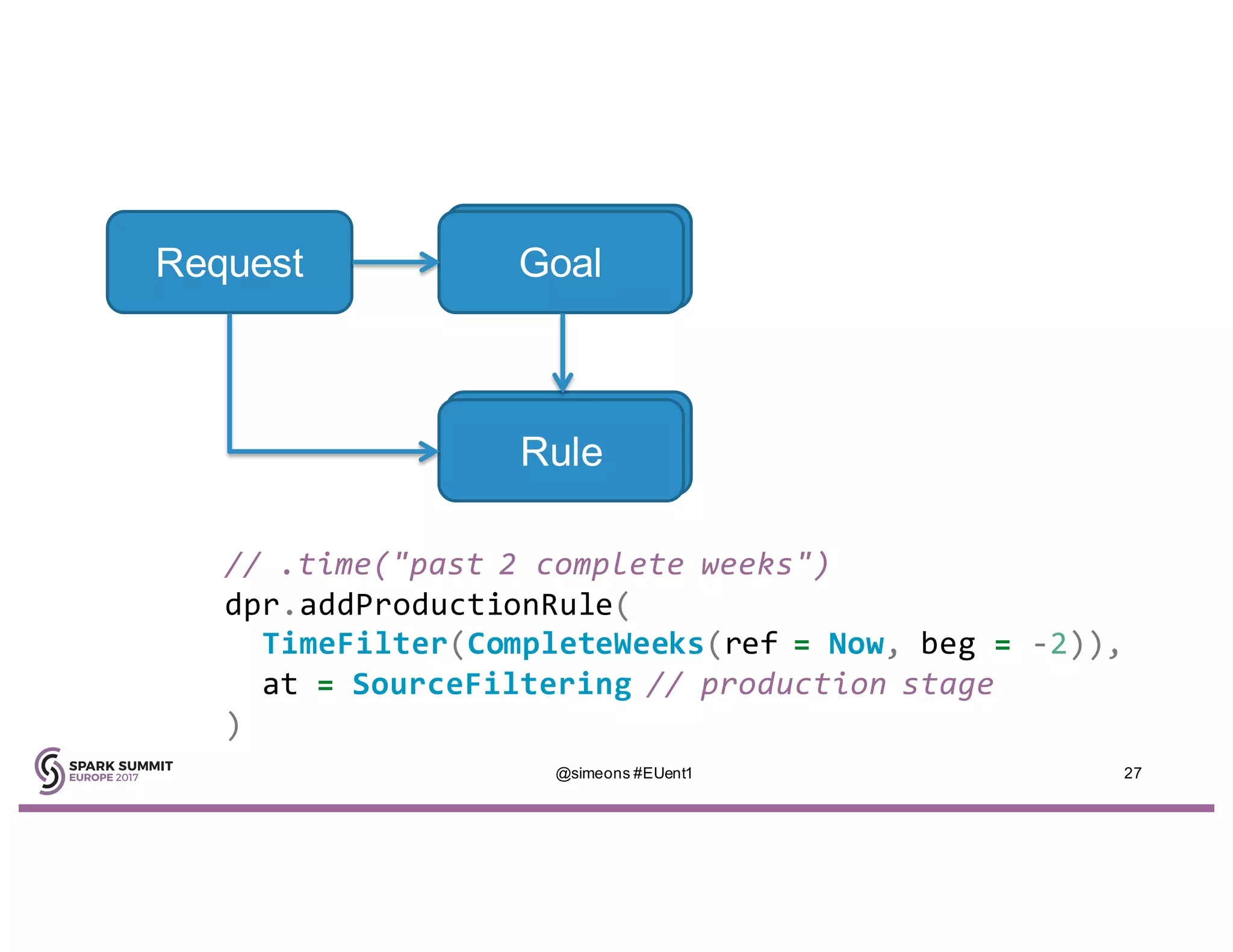
Simeon Simeonov discusses the concept of goal-based data production within the context of a data-powered culture, emphasizing the need for agile data production methods utilizing machine learning and AI. He highlights the complexity and inflexibility of traditional SQL abstractions and the advantages of a generative approach that enhances metadata queries and allows for real-time context resolution. The document advocates for a self-service model for data scientists and business users, aiming to improve productivity, flexibility, and collaboration through open-source solutions.





























![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)


