Downloaded 560 times












![Resilient Distributed Datasets (RDDs)
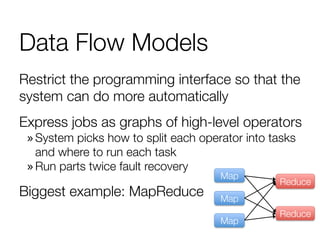
Main idea: Resilient Distributed Datasets
» Immutable collections of objects, spread across cluster
» Statically typed: RDD[T] has objects of type T
val sc = new SparkContext()!
val lines = sc.textFile("log.txt") // RDD[String]!
!
// Transform using standard collection operations!
val errors = lines.filter(_.startsWith("ERROR"))!
val messages = errors.map(_.split(‘t’)(2))!
!
messages.saveAsTextFile("errors.txt")!
lazily evaluated
kicks off a computation](https://image.slidesharecdn.com/qggqmvmqtow7a3c7xmes-signature-3cf9294a7bfebfdfcce57e9cc1bcdd5388b43a4e16ef2b29e8c2cab313ecbd3d-poli-150629181152-lva1-app6892/85/Advanced-Data-Science-on-Spark-Reza-Zadeh-Stanford-14-320.jpg)
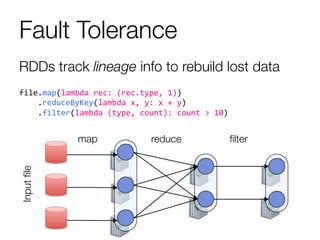
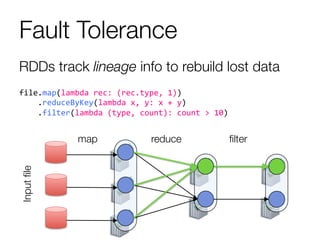











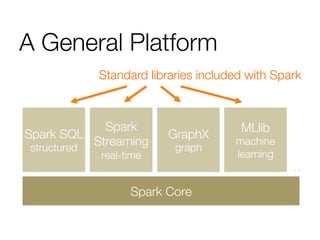
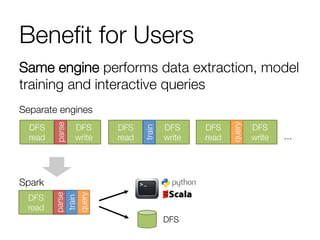


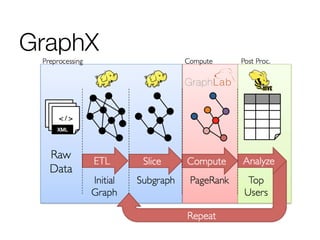

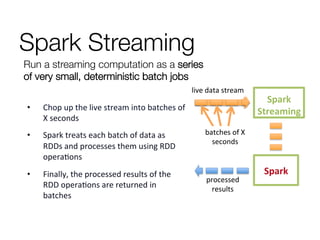


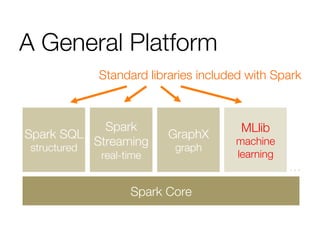






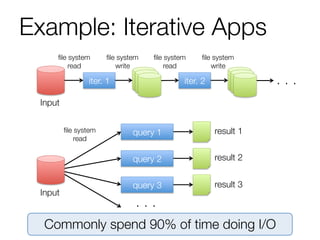
The document provides an overview of Spark and its machine learning library MLlib. It discusses how Spark uses resilient distributed datasets (RDDs) to perform distributed computing tasks across clusters in a fault-tolerant manner. It summarizes the key capabilities of MLlib, including its support for common machine learning algorithms and how MLlib can be used together with other Spark components like Spark Streaming, GraphX, and SQL. The document also briefly discusses future directions for MLlib, such as tighter integration with DataFrames and new optimization methods.























































































