Downloaded 154 times



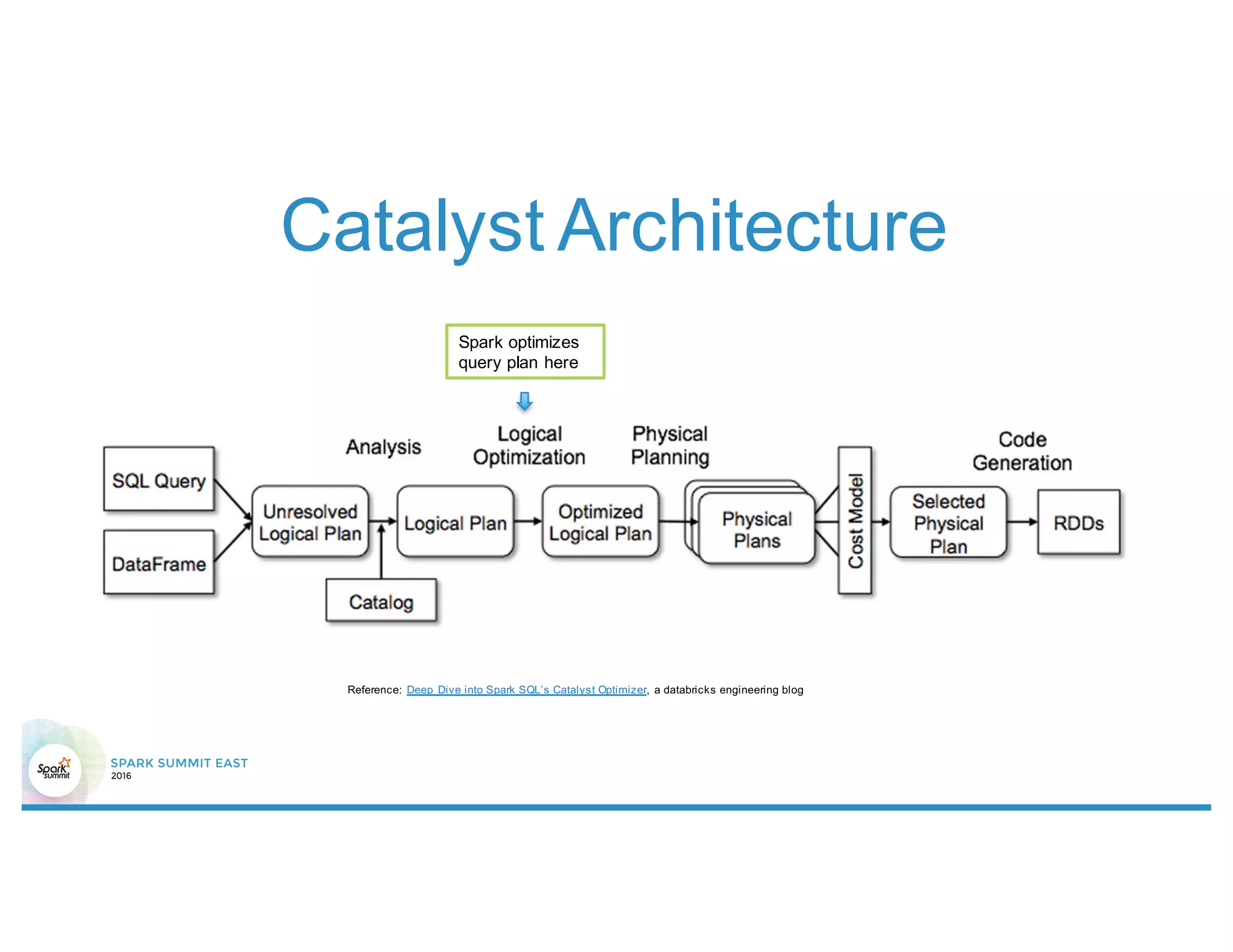



![Join-condition Push Down
• In case of push down failure
– No explicit equal-join condition recognized by EquiJoinSelection Strategy
– Expensive Join operator could be planned (i.e. CartesianProduct)
R1 R2
Join[predicate]
R2
Join
R1
Filter[predicate]
R1
Cartesian
Product
R2
Filter[predicate]
1. Predicate is empty
2. Predicate is notconjunctive
3. Predicate is conjunctive,butno split
componentmatches the attributes ofR1 and R2](https://image.slidesharecdn.com/8scminqiu-160224034229/75/Enhancements-on-Spark-SQL-optimizer-by-Min-Qiu-8-2048.jpg)

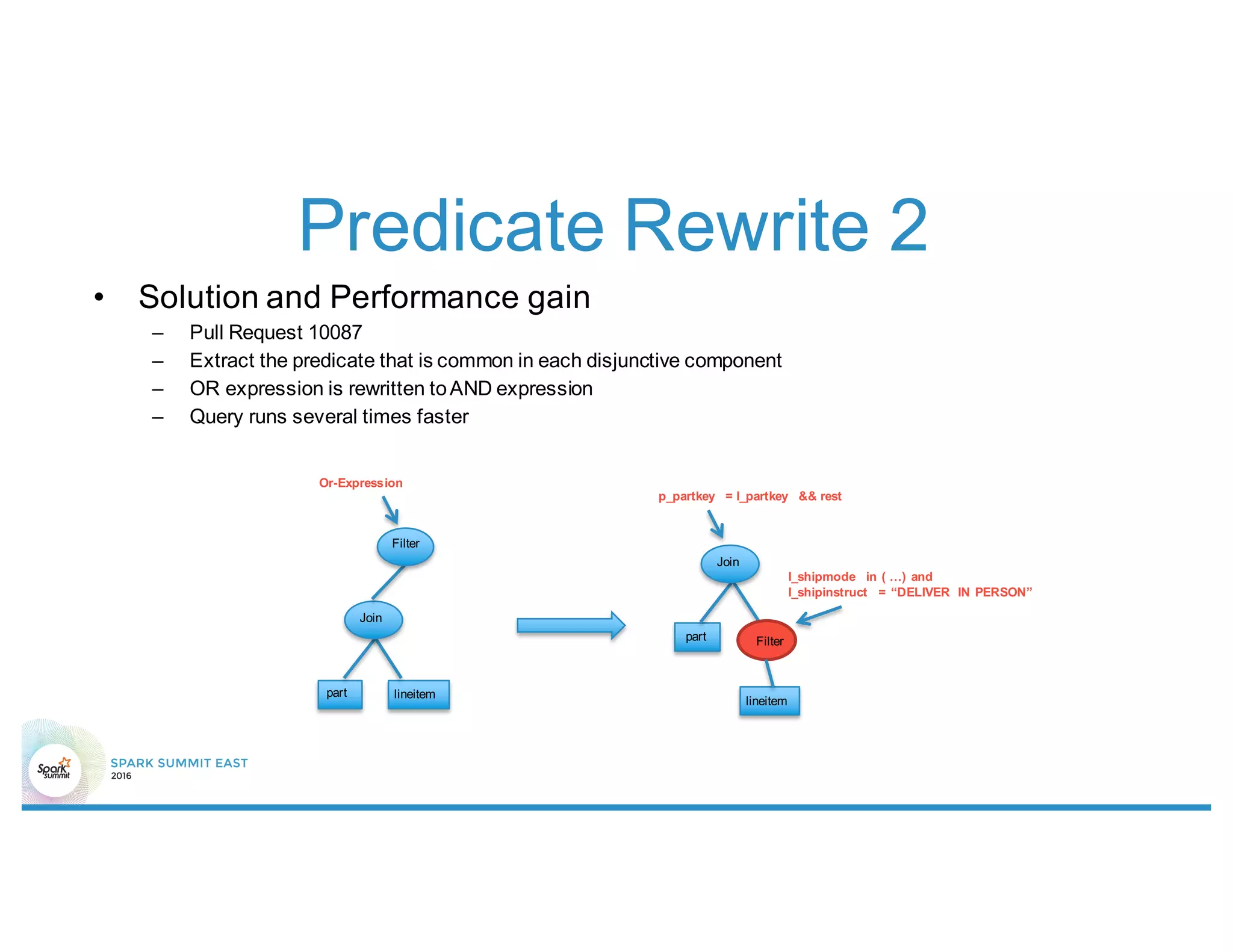

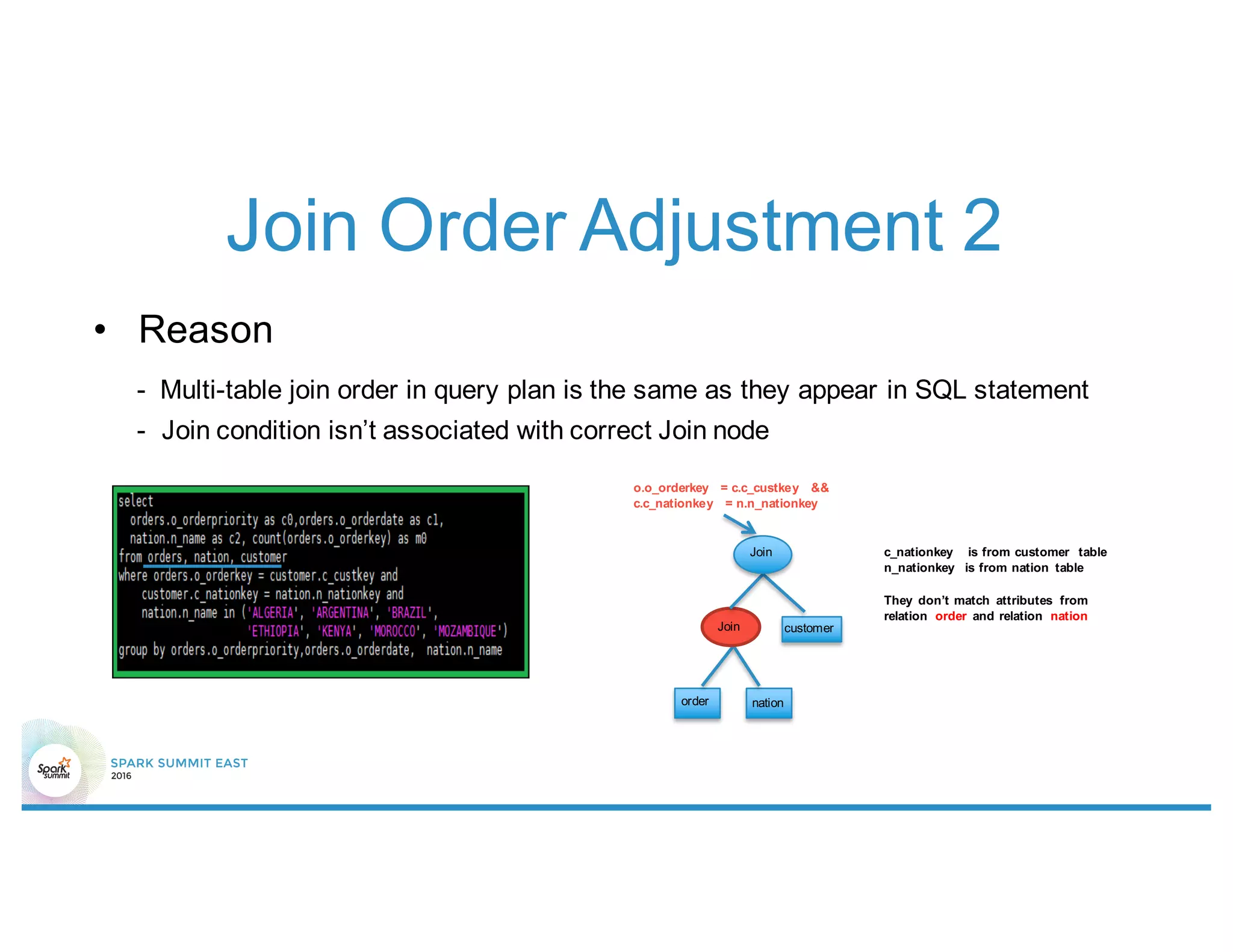
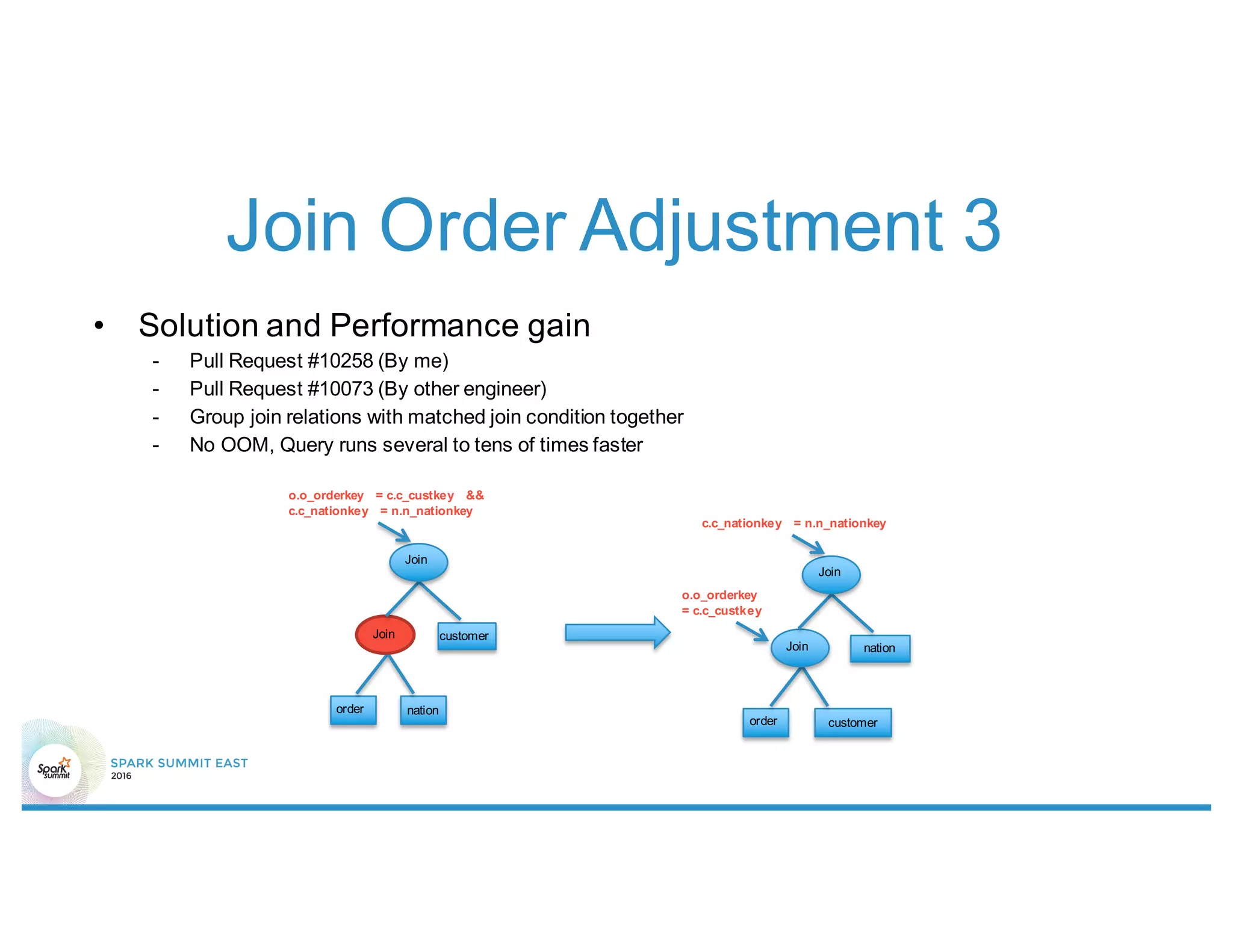


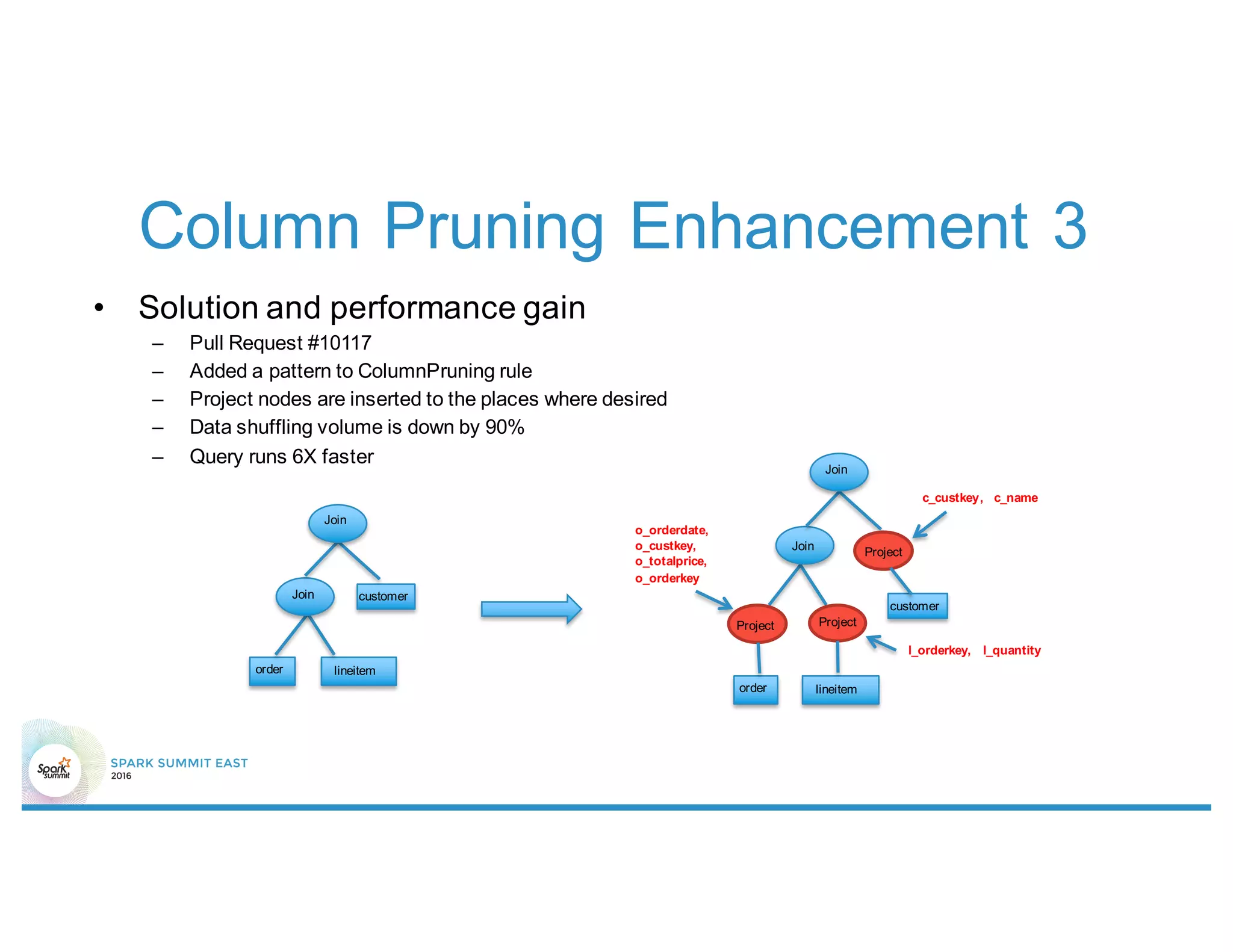








This document summarizes enhancements made to Spark SQL's optimizer including rule-based optimizations and cost-based optimizations. Rule-based optimizations included join condition push down through predicate rewrite and join order adjustment, as well as data volume reduction through column pruning enhancements. Cost-based optimizations leveraged statistics and histograms to select optimal join types, partitions, and join orders. Future work focuses on enumerating the full space of query plans and improving estimation accuracy.











































































































