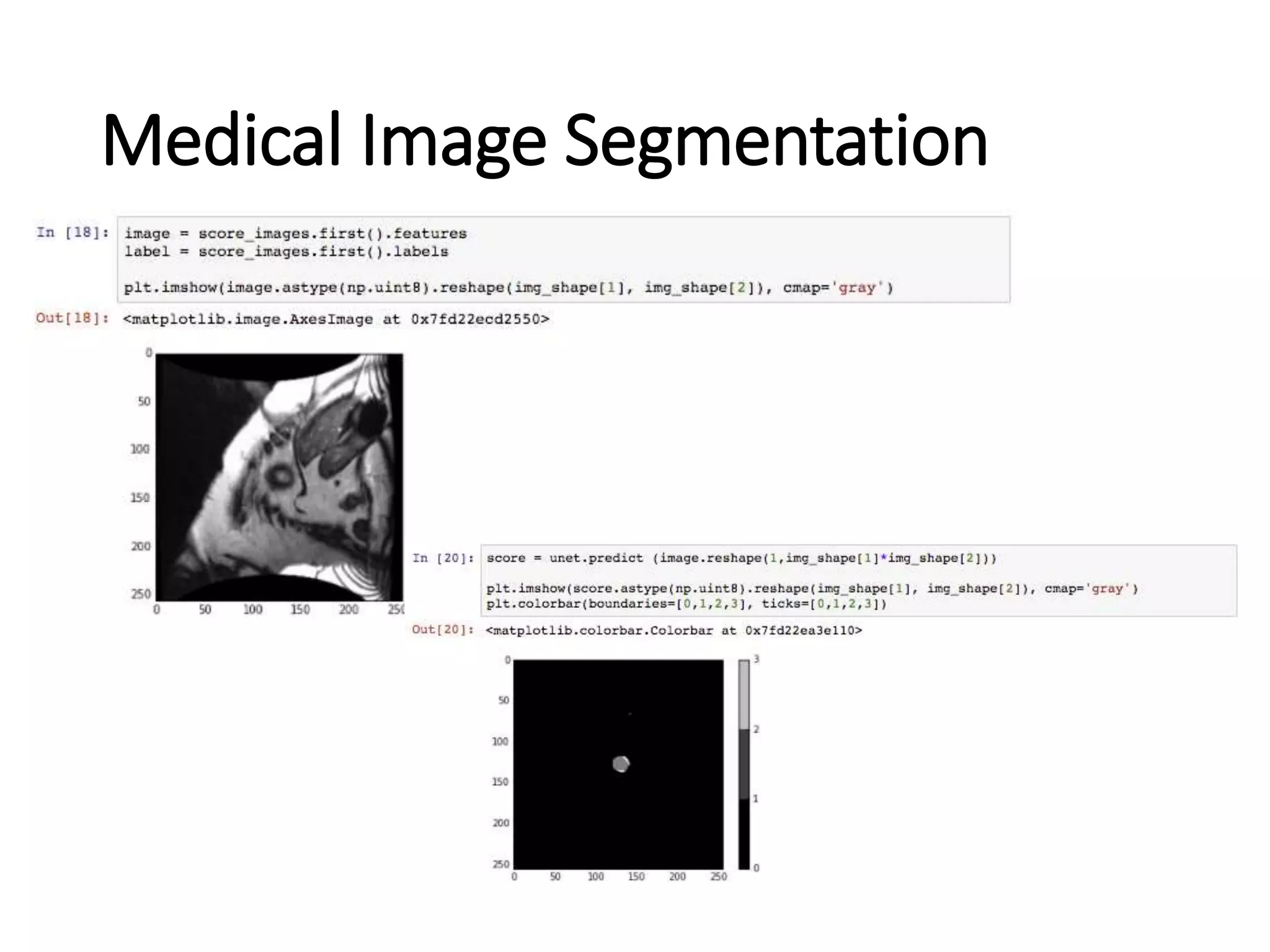
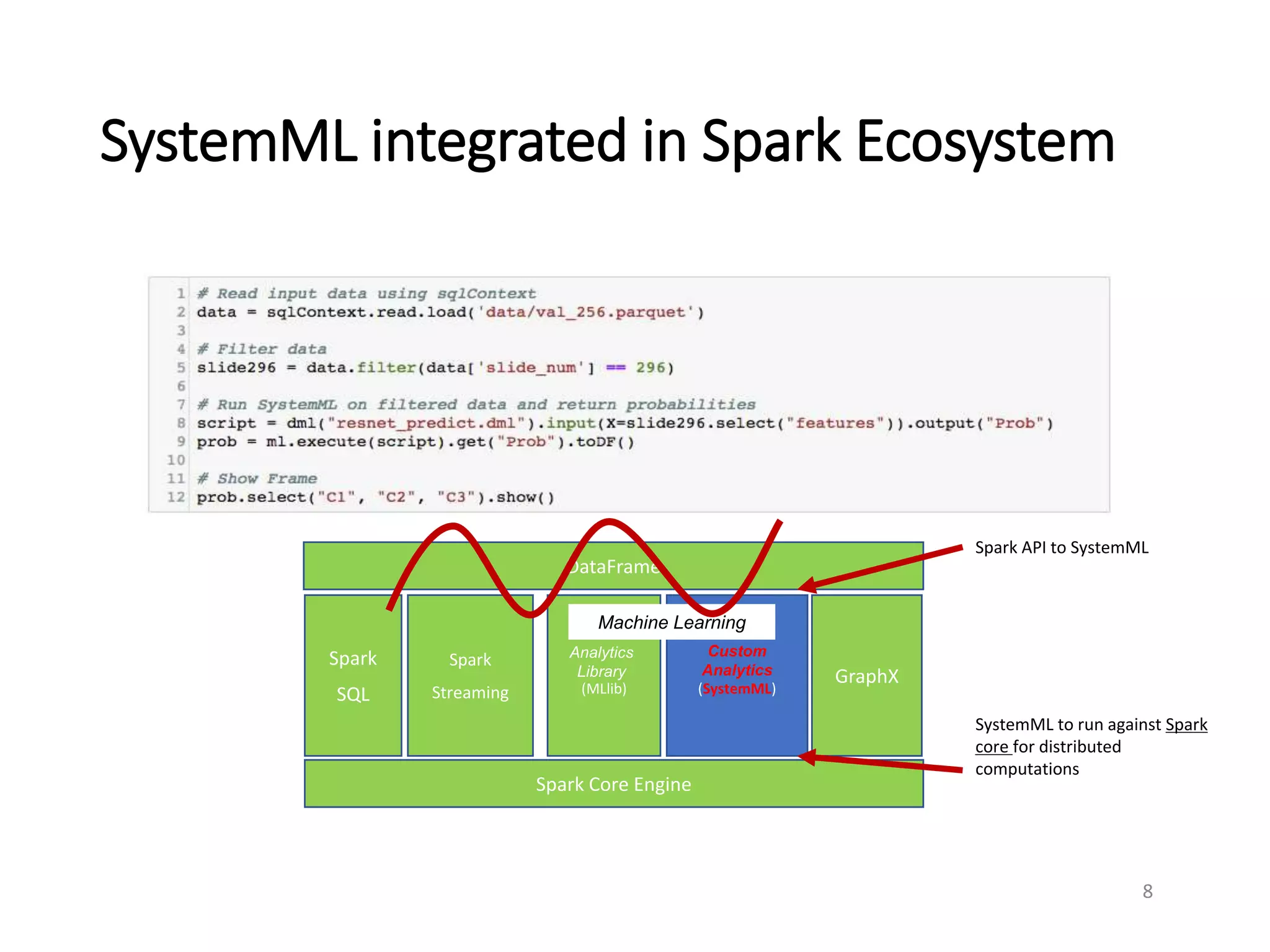
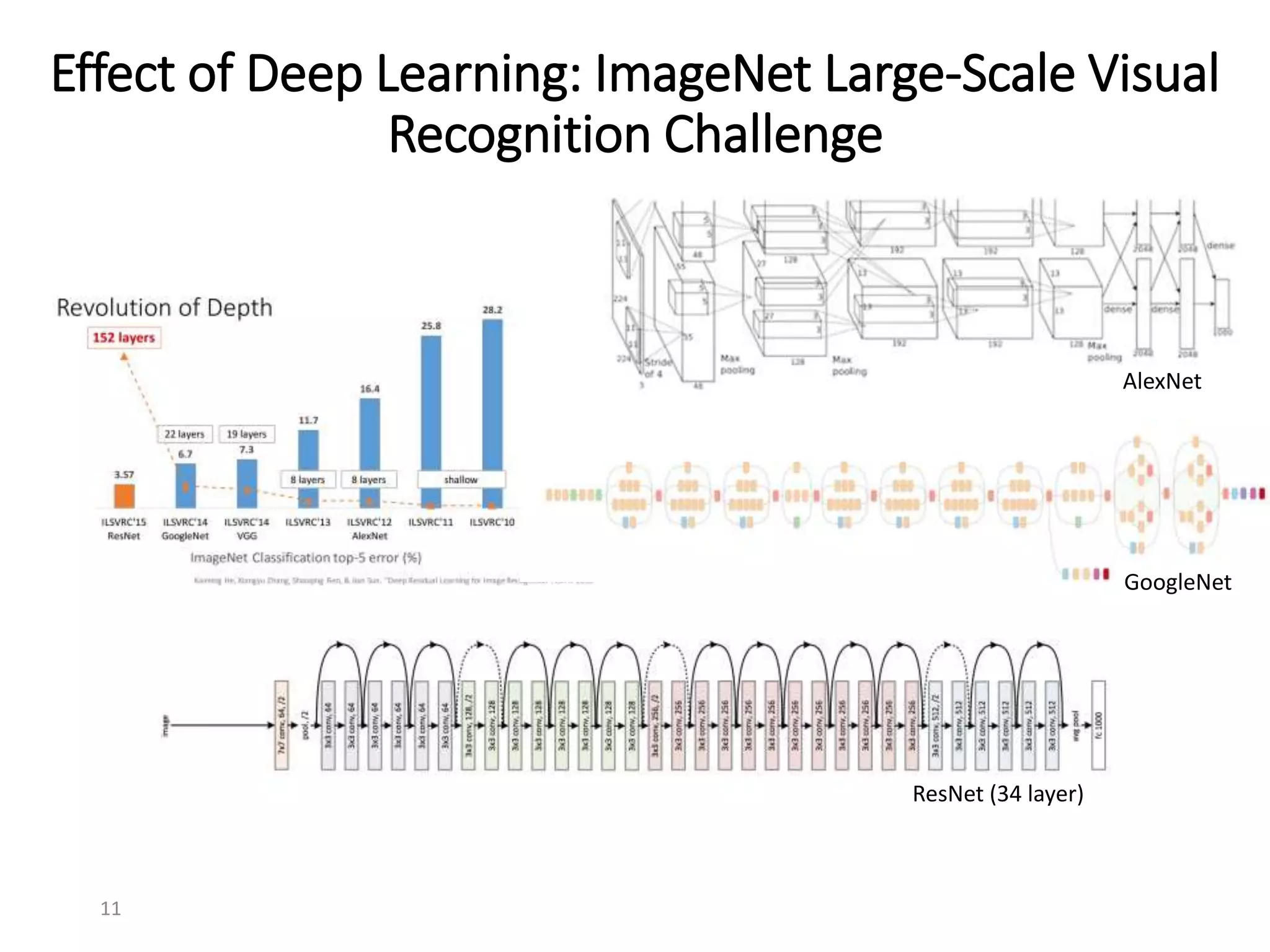
This document summarizes a presentation on Apache SystemML, an open source machine learning framework that provides scalable machine learning capabilities. It discusses SystemML's support for deep learning algorithms like convolutional neural networks and its ability to optimize machine learning workloads through techniques like operator fusion. It also demonstrates SystemML running image classification and medical image segmentation deep learning models on IBM Power systems and provides performance comparisons between Power and x86 architectures.













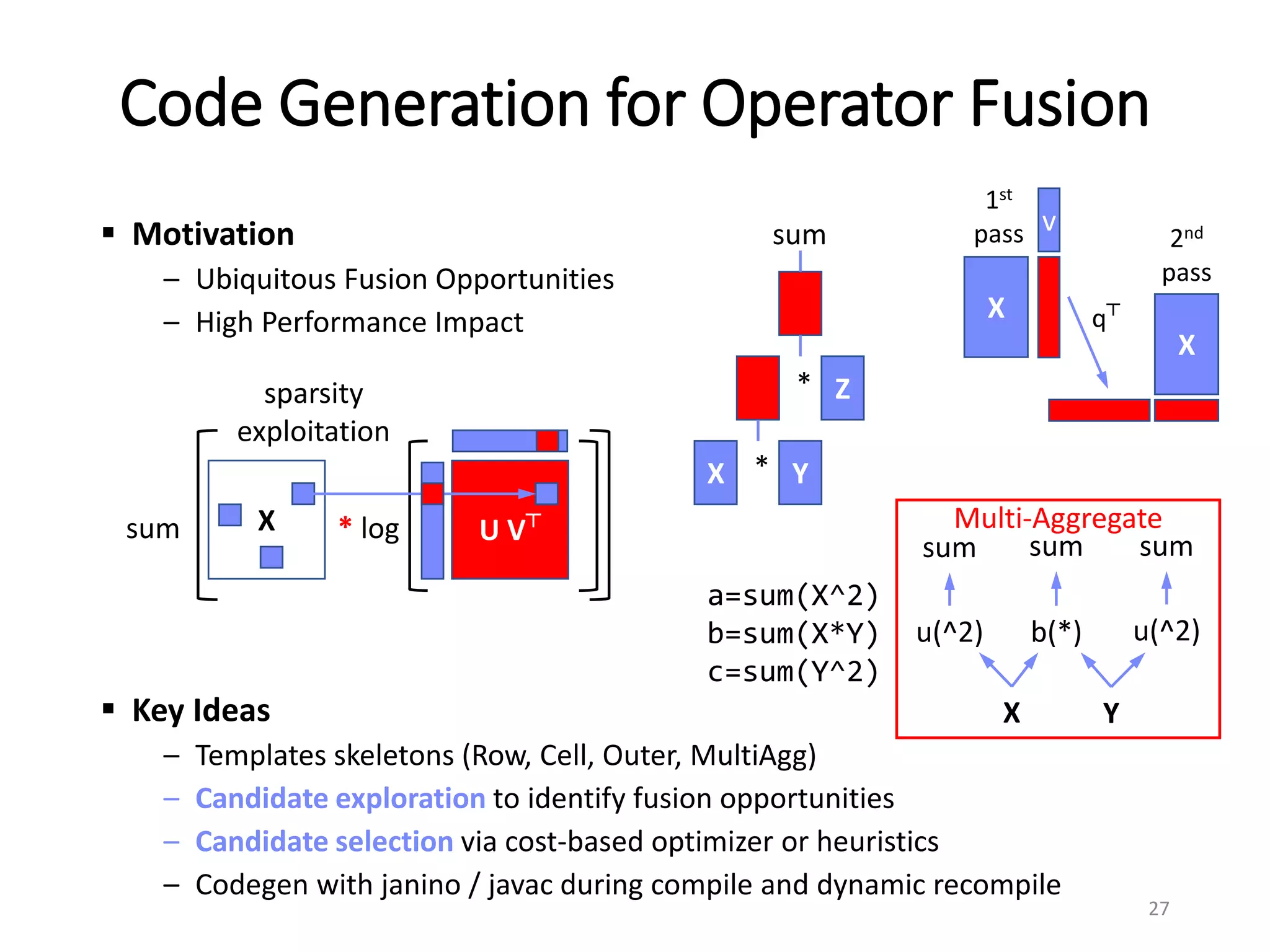
![Automatic Algebraic Simplification Rewrites lead to
Significant Performance Improvements
Simplify operations over mmult Eliminate unnecessary compute
– trace (X %*% Y) sum(X * t(Y))
Remove unnecessary operations Merging operations
– rand (…, min=-1, max=1) * 7
rand (…, min=-7, max=7)
Binary to unary operations Reduce amount of data touched
– X*X
X^2
Remove unnecessary Indexing Eliminate operations (conditional)
– X[a:b,c:d] = Y
X = Y iff dims(X)=dims(Y)
… 10’s more rewrite rules 23](https://image.slidesharecdn.com/systemmldlmeetup-171120145157/75/System-mldl-meetup-17-2048.jpg)

![Compressed Linear Algebra (CLA)
Motivation: Iterative ML algorithms with I/O-bound MV multiplications
Key Ideas: Use lightweight DB compression techniques and perform LA
operations on compressed matrices (w/o decompression)
Experiments
– LinregCG, 10 iterations, SystemML 0.14
– 1+6 node cluster, Spark 2.1
Dataset Gzip Snappy CLA
Higgs 1.93 1.38 2.17
Census 17.11 6.04 35.69
Covtype 10.40 6.13 18.19
ImageNet 5.54 3.35 7.34
Mnist8m 4.12 2.60 7.32
Airline78 7.07 4.28 7.44
Compression Ratios
89
3409
5663
135
765
2730
93
463
998
0
1000
2000
3000
4000
5000
6000
Mnist40m Mnist240m Mnist480m
Uncompressed
Snappy (RDD Compression)
CLA
End-to-End Performance [sec]
90GB 540GB 1.1TB
26](https://image.slidesharecdn.com/systemmldlmeetup-171120145157/75/System-mldl-meetup-19-2048.jpg)

![Linear Regression Conjugate Gradient
(preliminary 1/2)
31
0
2
4
6
8
10
12
14
64 128 256 512 1024 2048
TimeinSeconds
No. of Rows of input matrix (in Thousands)
PPC CPU Time
PPC GPU Time
x86 CPU Time
x86 GPU Time
Data: random with sparsity 0.95, 1000 features
Icpt: 0, maxi: 20, tol: 0.001, reg: 0.01
Driver-memory: 100G, local[*] master
M-V multiplication
chain is memory bound,
But more cores help
with parallelization.](https://image.slidesharecdn.com/systemmldlmeetup-171120145157/75/System-mldl-meetup-23-2048.jpg)
![Linear Regression Conjugate Gradient
(preliminary 2/2)
32
0
2
4
6
8
10
12
14
64 256 1024
TimeinSeconds
No. of Rows of input matrix (in Thousands)
PPC GPU Time
x86 GPU Time
Data: random with sparsity 0.95, 1000 features
Icpt: 0, maxi: 20, tol: 0.001, reg: 0.01
Driver-memory: 100G, local[*] master
0
1
2
3
4
5
6
7
64 256 1024
TimeinSeconds
No. of Rows of input matrix (in Thousands)
CPU-GPU Transfer Time
PPC toDev Time
x86 toDev Time
Most of the time is spent
in transferring data from
host to device
-> 2x performance benefit
due to CPU-GPU NVLink](https://image.slidesharecdn.com/systemmldlmeetup-171120145157/75/System-mldl-meetup-24-2048.jpg)







































































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)


