Downloaded 55 times





![Bad statistics
Adaptive Query planning
RoPe [NSDI 12, VLDB 2013]
No upfront statistics
Pilot runs (samples)
DynO [SIGMOD 2014]
Cost-base Optimizer in DISC: State of the Art](https://image.slidesharecdn.com/022matteointerlandi-170613030754/85/Lazy-Join-Optimizations-Without-Upfront-Statistics-with-Matteo-Interlandi-7-320.jpg)
![Bad statistics
◦ Adaptive Query planning
◦ RoPe [NSDI 12, VLDB 2013]
No upfront statistics
Cost-base Optimizer in DISC: State of the Art](https://image.slidesharecdn.com/022matteointerlandi-170613030754/85/Lazy-Join-Optimizations-Without-Upfront-Statistics-with-Matteo-Interlandi-8-320.jpg)
![Bad statistics
◦ Adaptive Query planning
◦ RoPe [NSDI 12, VLDB 2013]
No upfront statistics
Cost-base Optimizer in DISC: State of the Art
Assumption is that some initial
statistics exist](https://image.slidesharecdn.com/022matteointerlandi-170613030754/85/Lazy-Join-Optimizations-Without-Upfront-Statistics-with-Matteo-Interlandi-9-320.jpg)
![Bad statistics
◦ Adaptive Query planning
◦ RoPe [NSDI 12, VLDB 2013]
No upfront statistics
◦ Pilot runs (samples)
◦ DynO [SIGMOD 2014]
Cost-base Optimizer in DISC: State of the Art
Assumption is that some initial
statistics exist](https://image.slidesharecdn.com/022matteointerlandi-170613030754/85/Lazy-Join-Optimizations-Without-Upfront-Statistics-with-Matteo-Interlandi-10-320.jpg)
![Bad statistics
◦ Adaptive Query planning
◦ RoPe [NSDI 12, VLDB 2013]
No upfront statistics
◦ Pilot runs (samples)
◦ DynO [SIGMOD 2014]
Cost-base Optimizer in DISC: State of the Art
Assumption is that some initial
statistics exist
• Samples are expensive
• Only foreign-key joins
• No runtime plan revision](https://image.slidesharecdn.com/022matteointerlandi-170613030754/85/Lazy-Join-Optimizations-Without-Upfront-Statistics-with-Matteo-Interlandi-11-320.jpg)



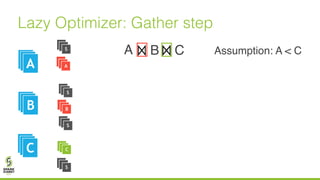
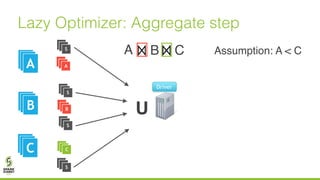
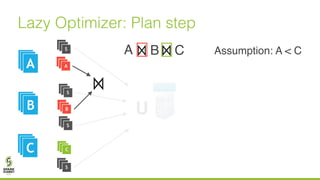
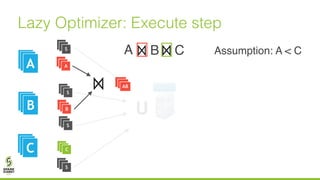
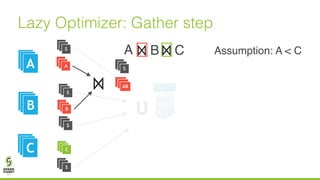
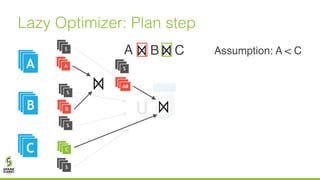
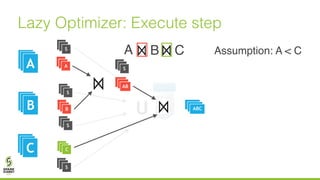



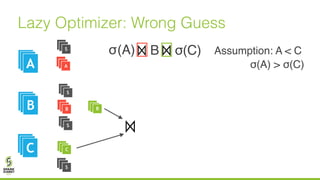
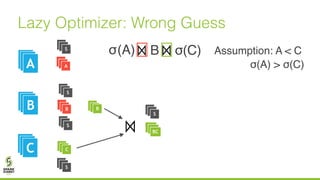
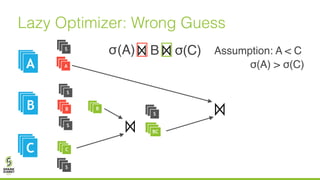
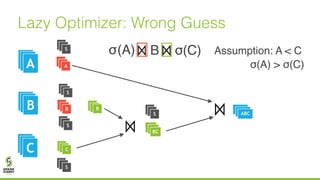



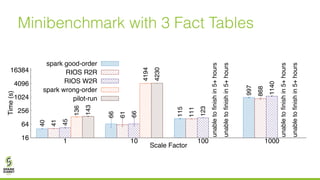

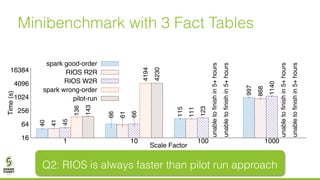
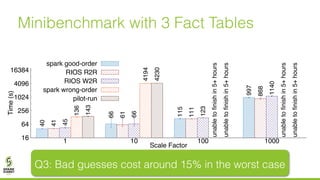
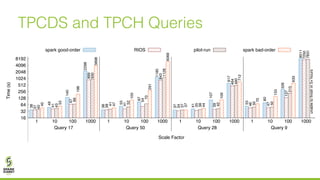
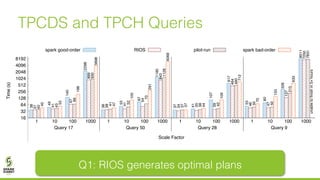
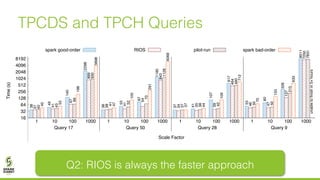





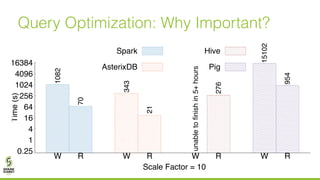
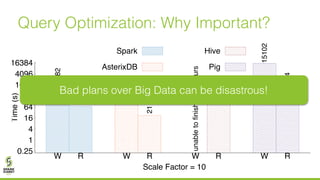
The document discusses lazy join optimization techniques for big data query processing, specifically focusing on a cost-based optimizer for Spark that executes joins without requiring upfront statistics or pilot runs. It presents the benefits of runtime statistics collection, emphasizing improved performance compared to traditional methods and showcases experimental results demonstrating that the proposed approach can achieve significant speedups. The conclusions highlight potential for future improvements in optimization strategies and configurations to further enhance query execution efficiency.
































![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)






















































