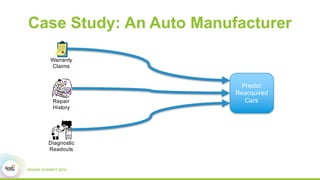
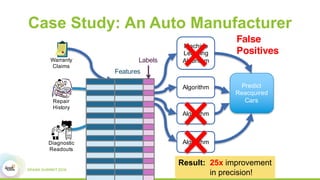
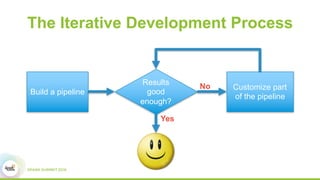
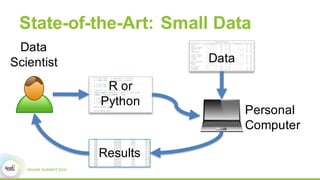
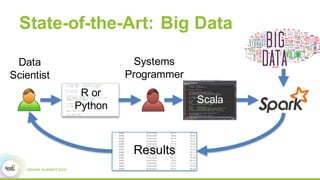
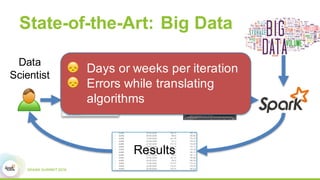
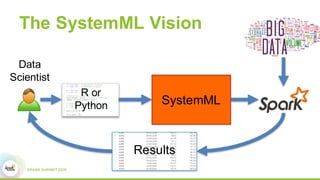
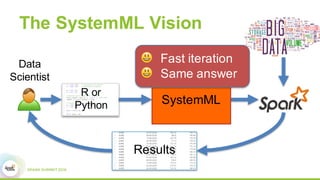
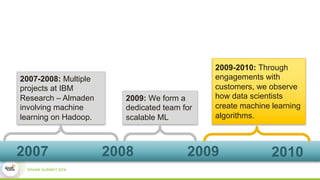
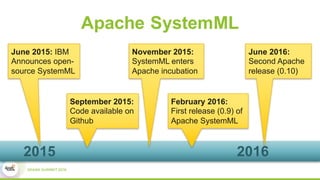
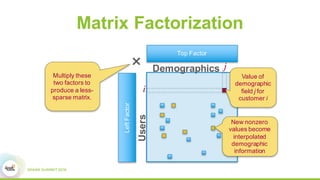
This document discusses Apache SystemML, which is a machine learning framework for building custom machine learning algorithms on Apache Spark. It originated from research projects at IBM involving machine learning on Hadoop. SystemML aims to allow data scientists to build ML solutions using languages like R and Python, while executing algorithms on big data platforms like Spark. It provides a high-level language for expressing algorithms and performs automatic parallelization and optimization. The document demonstrates SystemML through a matrix factorization example for a targeted advertising problem. It shows how to wrangle data, build a custom algorithm, and get results. In conclusion, it recommends that readers try out SystemML through its website.

















































































![[DSC Europe 22] Smart approach in development and deployment process for vari...](https://cdn.slidesharecdn.com/ss_thumbnails/danijelilievskimilosjosifovic-221130080722-69bdf3af-thumbnail.jpg?width=640&height=640&fit=bounds)










































