Download as PDF, PPTX





![ෆภਪఆྔ
Unbiased Estimator
ਪఆ͍ͨ͠ྔɿ ɹਪఆྔɿ
͕Γཱͭͱ͖ʮ ͷෆภਪఆྔͰ͋Δʯͱ͍͏
y ̂
y
𝔼
[ ̂
y] = y ̂
y y](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-6-2048.jpg)
![ෆภਪఆྔ
Unbiased Estimator
Ex. 1: ਖ਼نͷฏۉͷਪఆ
σʔλ ͕ਖ਼ن ͔ΒಘΒΕͨͱ͢Δ
αϯϓϧฏۉ ฏۉ ͷෆภਪఆྔ
x(1)
, …, x(n)
𝒩
(x; μ, σ2
)
x̄ =
∑
n
i=1
x(i)
n
μ
𝔼
[x̄] =
𝔼
[
∑
n
i=1
x(i)
n ]
=
1
n
n
∑
i=1
𝔼
[x(i)
] = μ](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-7-2048.jpg)

![ෆภਪఆྔ
Unbiased Estimator
Ex. 3: Reparameterization trick
Λਪఆ͍ͨ͠
ͱͯ͠ ͷෆภਪఆྔ
• VAEͷΤϯίʔμͷޯਪఆʹΘΕΔ
∇θ
𝔼
pθ(x) [f (x)] (pθ (x) =
𝒩
(x; μθ, σθ))
ϵ ∼
𝒩
(ϵ; 0,1) ∇θ f (μθ + ϵ ⋅ σθ) ∇θ
𝔼
pθ(x) [f (x)]
𝔼
ϵ∼
𝒩
(ϵ; 0,1) [∇θ f (μθ + ϵ ⋅ σθ)] = ∇θ
𝔼
pθ(x) [f (x)]](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-9-2048.jpg)
![ෆภਪఆྔ
Unbiased Estimator
Ex. 4: Likelihood ratio gradient estimator (REINFORCE)
Λਪఆ͍ͨ͠
ͱͯ͠ ͷෆภਪఆྔ
• ڧԽֶशͷํࡦޯ๏ͰΘΕΔ
∇θ
𝔼
pθ(x) [f (x)]
x ∼ pθ (x) f (x)∇θlog pθ (x) ∇θ
𝔼
pθ(x) [f (x)]
𝔼
pθ(x) [f (x)∇θlog pθ (x)] = ∇θ
𝔼
pθ(x) [f (x)]](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-10-2048.jpg)




![มਪ
Variational Inference
ରपล͍ͳ͖ͰࢉܭͷͰɺมԼքΛ༻͍Δ
͜ͷෆࣜ ͷͱ͖߸ཱ
➡ Λ ʹͳΔ͍͔ۙ͘Βબྑ͍
log pθ (x) = log
∫
pθ (x, z) dz
≥
𝔼
q(z) [
log
pθ (x, z)
q (z) ]
= ℒ (θ, q)
q (z) = pθ (z ∣ x)
q (z) pθ (z ∣ x)](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-15-2048.jpg)

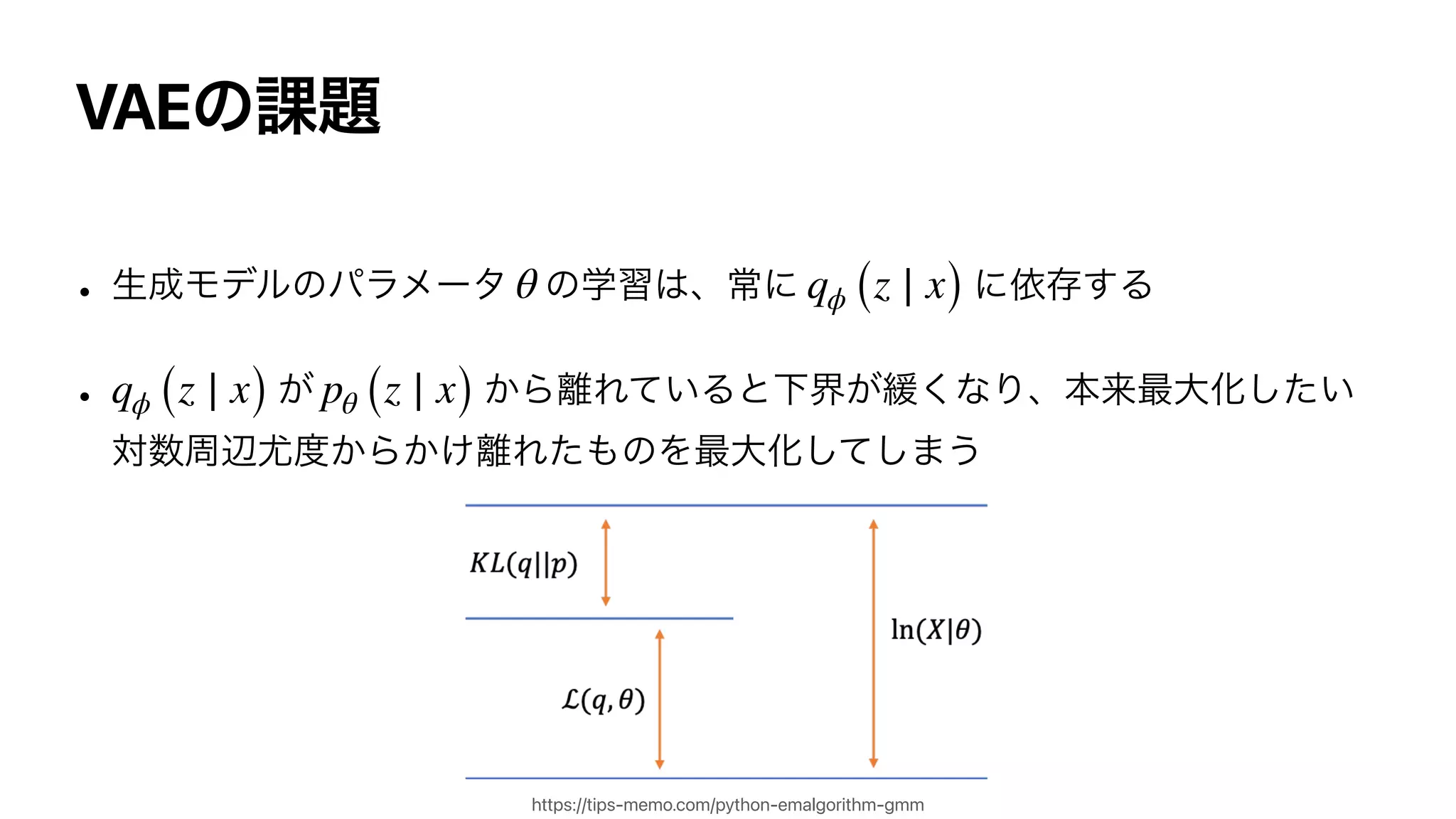


![Importance Weighted Autoencoder
IWAE
• ͷͱ͖ɺVAEͷมԼքͱҰக
• Ͱ߸ཱ
log pθ (x) = log
𝔼
z(1),…,z(k)∼q(z)
[
1
k
k
∑
i=1
pθ (x, z(i)
)
q (z(i)
) ]
≥
𝔼
z(1),…,z(k)∼q(z)
[
log
1
k
k
∑
i=1
pθ (x, z(i)
)
q (z(i)
) ]
= ℒk (θ, q)
k = 1
k → ∞](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-20-2048.jpg)
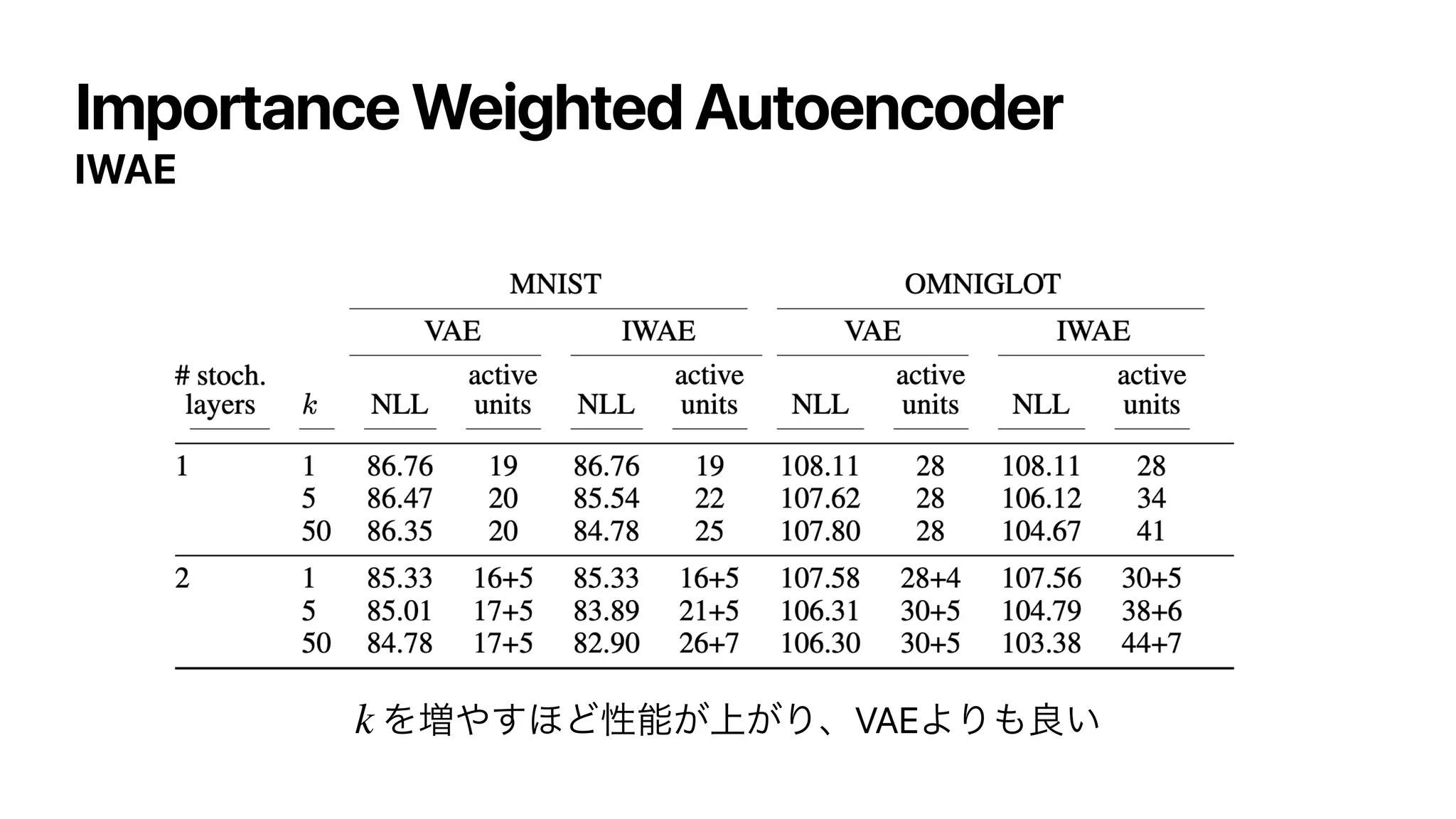




![Russian Roulette Estimator
ͷෆภਪఆྔͰ͋Δ͜ͱ͕Θ͔Δ
̂
y
∞
∑
k=1
Δk
̂
y = Δ1 +
∑
∞
k=2
Δk
μ
⋅ b, b ∼ Bernoulli (b; μ)
𝔼
[ ̂
y] = Δ1 +
∑
∞
k=2
Δk
μ
⋅
𝔼
[b] =
∞
∑
k=1
Δk](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-26-2048.jpg)

![SUMO
Stochastically Unbiased Marginalization Objective
log pθ (x) =
𝔼
K∼p(K)
[
K
∑
k=1
Δk
μk−1 ]
= ℒ1 (θ, qϕ) +
𝔼
K∼p(K)
K
∑
k=2
ℒk (θ, qϕ) − ℒk−1 (θ, qϕ)
μk−1
VAEͱಉ͡
ิਖ਼߲](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-28-2048.jpg)
![SUMO
Stochastically Unbiased Marginalization Objective
SUMOରपลͷෆภਪఆྔ
SUMO (x) = log w(1)
+
K
∑
k=2
log
1
k
∑
k
i=1
w(i)
− log
1
k − 1
∑
k−1
i=1
w(i)
μk−1
w(i)
=
pθ (x, z(i)
)
qϕ (z(i) ∣ x)
, K ∼ p (K), z(1)
, …, z(K)
∼ qϕ (z ∣ x)
𝔼
K∼p(K), z(1),…,z(K)∼qϕ(z ∣ x) [SUMO (x)] = log pθ (x)](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-29-2048.jpg)

![SUMO
Τϯίʔμͷֶश
SUMOɺΤϯίʔμଆ͔ΒͨݟΒύϥϝʔλ ʹؔͯ͠ఆ
VAEͷΑ͏ʹɺಉ͡ϩεͰֶशͯ͠ҙຯ͕ͳ͍
จͰɺਪఆྔͷࢄΛ࠷খԽ͢ΔΑ͏ʹֶश͢Δ͜ͱΛఏҊ͍ͯ͠Δ
ϕ
∇ϕ
𝕍
[SUMO (x)] =
𝔼
[∇ϕ(SUMO (x))2
]](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-31-2048.jpg)
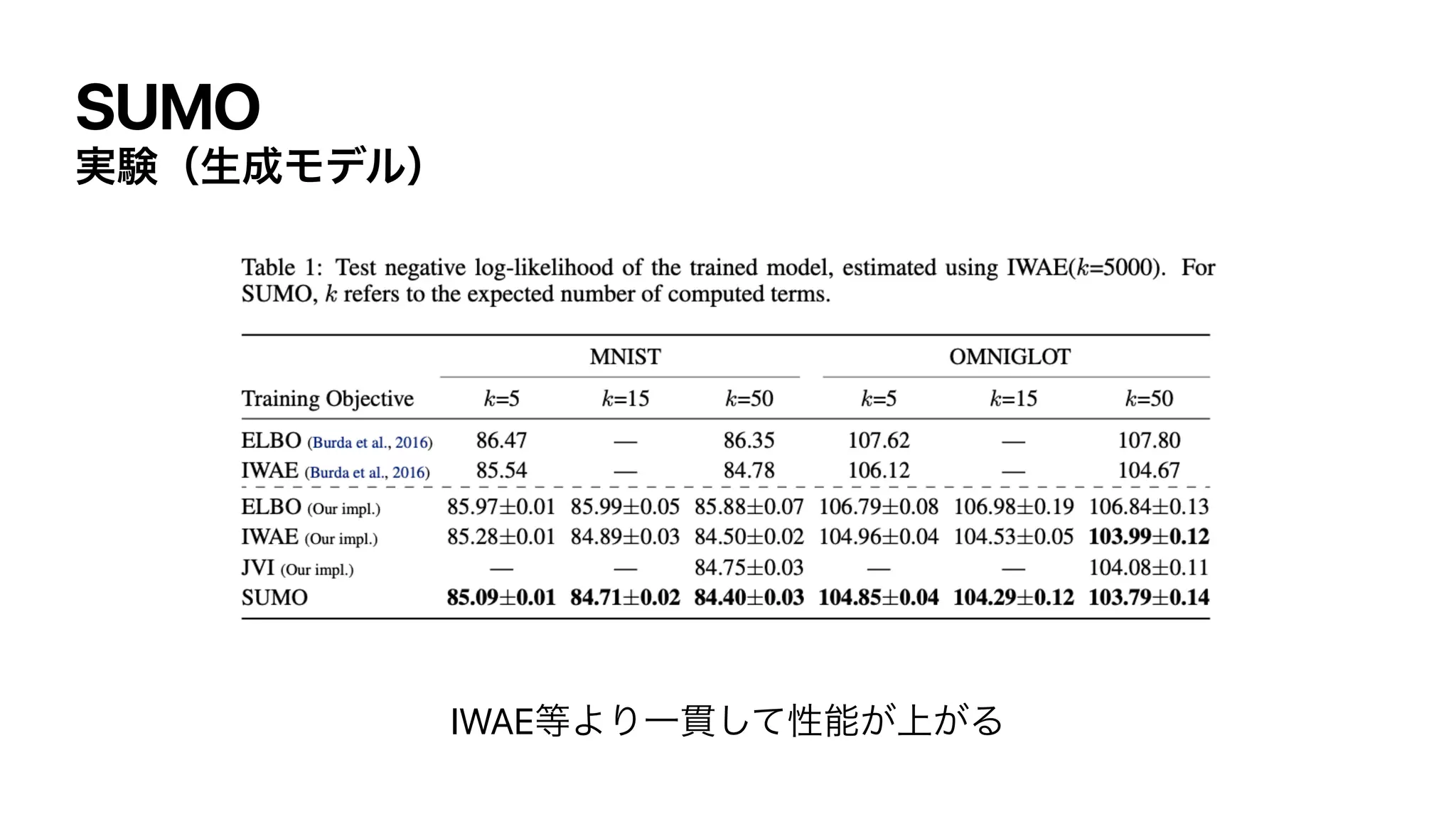
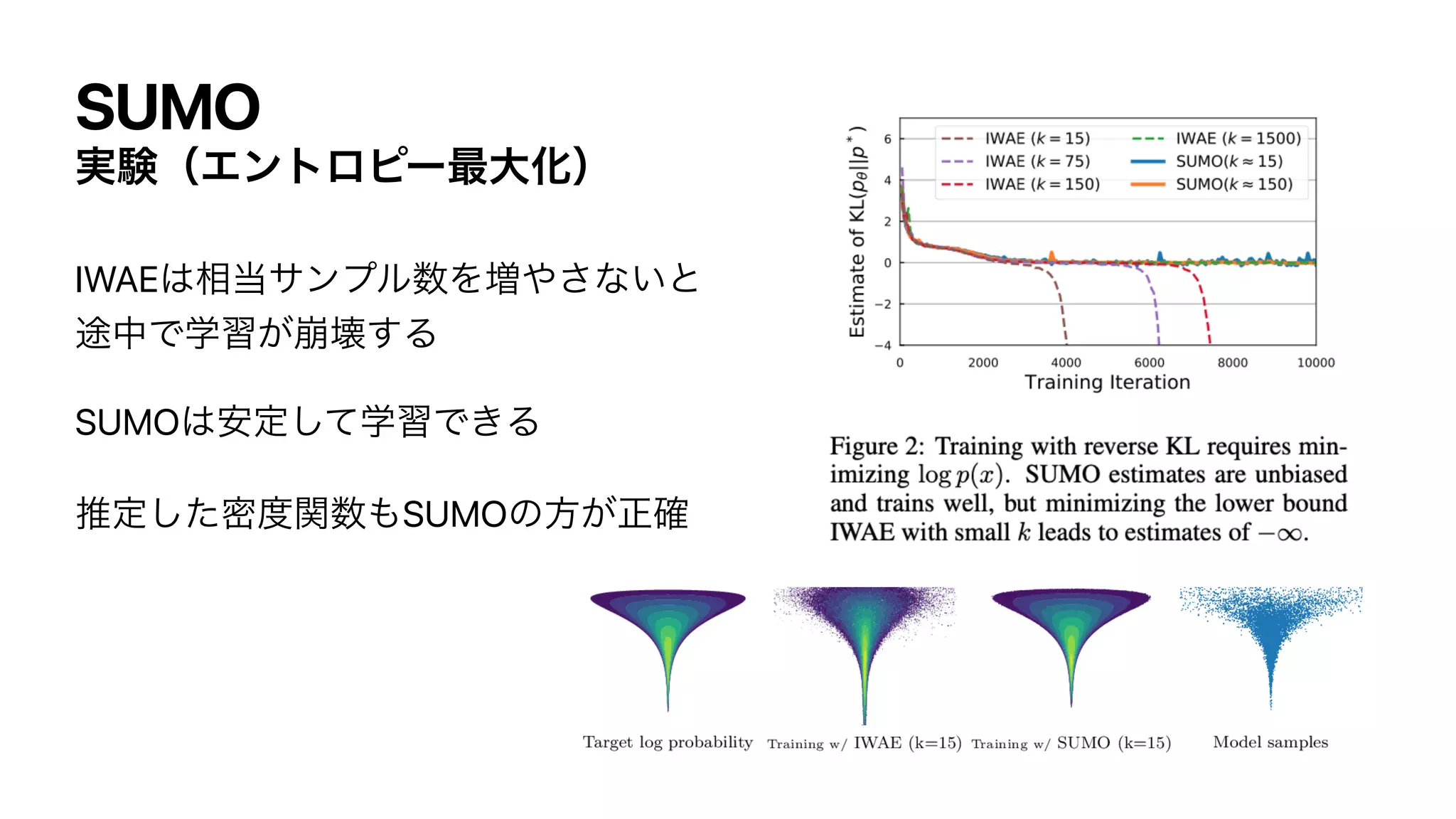
![SUMO
Τϯτϩϐʔ࠷େԽ
ີؔΘ͔͍ͬͯΔ͕ɺαϯϓϦϯά͕͍͠ Λۙࣅ͍ͨ͠
͜ΕΛજࡏมϞσϧͰֶश͢Δͱ͖ɺreverse KLͷ࠷খԽ͕Α͘ΘΕΔ
ୈ1߲ͷΤϯτϩϐʔ߲ͷ͕ࢉܭ͍͠
p* (x)
min
θ
KL (pθ(x)∥ p*(x)) = min
θ
𝔼
x∼pθ(x) [log pθ(x) − log p*(x)]](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-33-2048.jpg)
![SUMO
Τϯτϩϐʔ࠷େԽ
ͷਪఆʹIWAEΛ͏ͱɺతؔͷԼքΛ࠷খԽͯ͠͠·͏
SUMOΛ͑ɺ͜ͷΛճආͰ͖Δɹ
log pθ (x)
𝔼
pθ(x) [log pθ (x)] ≥
𝔼
pθ(x),z(1),…,z(k)∼qϕ(z ∣ x)
[
log
1
k
k
∑
i=1
pθ (x, z(i)
)
q (z(i)
) ]
=
𝔼
pθ(x) [log pθ (x) − KL (q̃θ,ϕ (z ∣ x) ∥ pθ (z ∣ x))]
𝔼
pθ(x) [log pθ (x)] =
𝔼
[SUMO (x)]
͜͜Λ࠷େԽ͠Α͏ͱͯ͠͠·͏](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-34-2048.jpg)
![SUMO
REINFORCEͷԠ༻
REINFORCEͰɺ ͕͖ͰࢉܭΔඞཁ͕͋Δ
ʹજࡏมϞσϧΛ͏ͱɺ؆୯ʹͳ͘ͳ͖ͰࢉܭΔ
e.g., ڧԽֶशͷํࡦʹજࡏมϞσϧΛ͏
log pθ (x)
∇θ
𝔼
pθ(x) [f (x)] =
𝔼
pθ(x) [f (x)∇θlog pθ (x)]
pθ (x)
πθ (a ∣ s) =
∫
pθ (z) pθ (a ∣ s, z) dz](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-36-2048.jpg)
![SUMO
REINFORCEͷԠ༻
SUMOΛ͑ɺ͜ΕෆภਪఆͰ͖Δ
∇θ
𝔼
pθ(x) [f (x)] =
𝔼
pθ(x) [f (x)∇θlog pθ (x)]
=
𝔼
[f (x)∇θSUMO (x)]](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-37-2048.jpg)
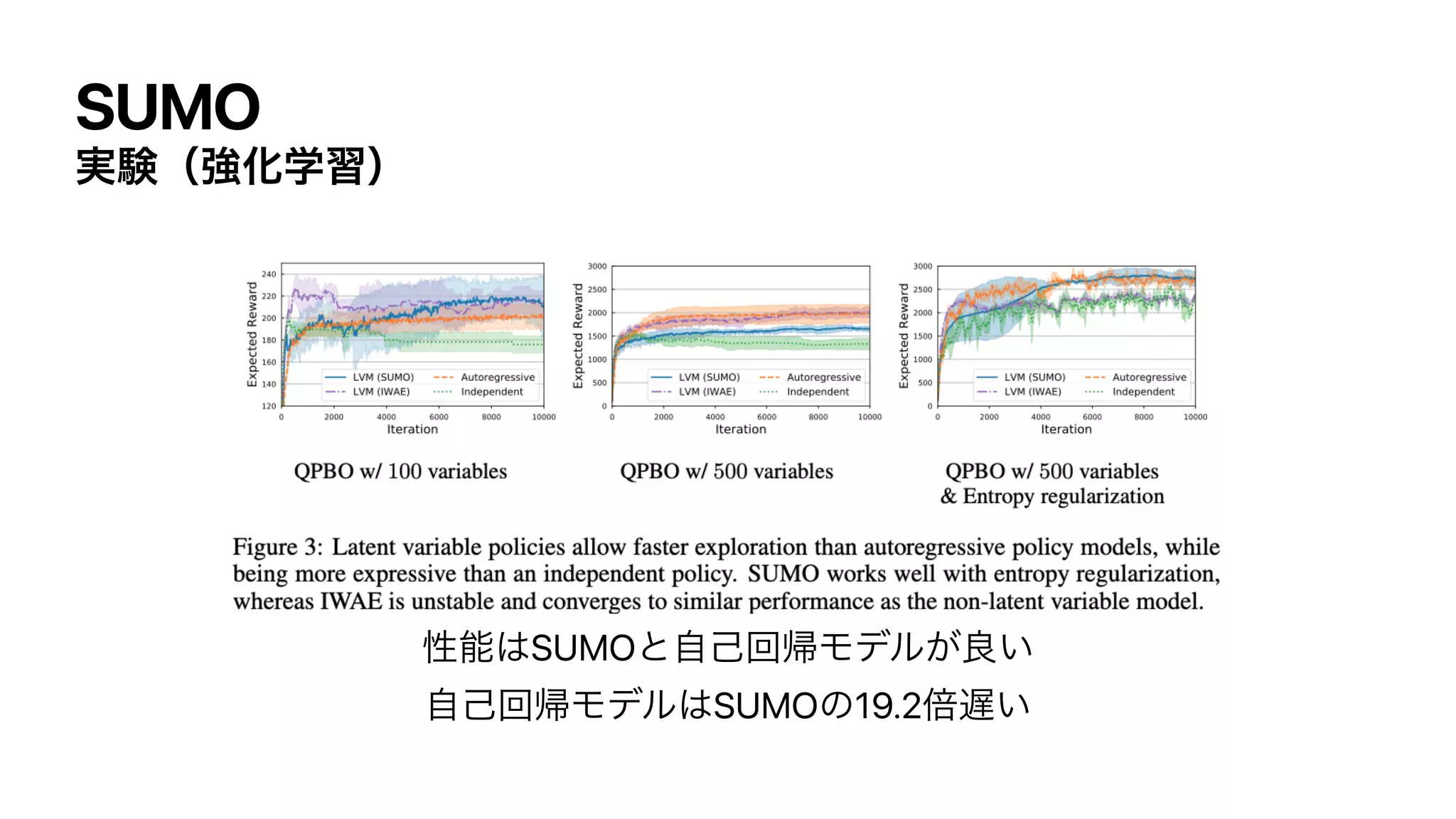
![SUMO
࣮ݧʢڧԽֶशʣ
࣌ྻܥΛ͍ͳ·ؚ؆୯ͳڧԽֶशͷͰɺ ͷ࠷େԽΛߟ͑Δ
ֶशREINFORCEΛͬͯɺํࡦޯ๏Ͱߦ͏
ํࡦ ʹજࡏมϞσϧΛ͏߹ʹɺSUMO͕͑Δ
𝔼
x∼pθ(x)[R(x)]
∇θ
𝔼
x∼pθ(x)[R(x)] =
𝔼
pθ(x) [R (x)∇θlog pθ (x)]
pθ (x)
∇θ
𝔼
x∼pθ(x)[R(x)] =
𝔼
[R (x)∇θSUMO (x)]](https://image.slidesharecdn.com/dlseminar202108201-210820030528/75/DL-SUMO-Unbiased-Estimation-of-Log-Marginal-Probability-for-Latent-Variable-Models-38-2048.jpg)




The document proposes a method called SUMO (Stochastically Unbiased Marginalization Objective) for estimating log marginal probabilities in latent variable models. SUMO uses a Russian roulette estimator to obtain an unbiased estimate of the log marginal likelihood. This allows SUMO to provide an objective function for variational inference that converges to the log marginal likelihood as more samples are taken, avoiding the bias issues of methods like VAEs and IWAE. The paper outlines SUMO, compares it to existing methods, and demonstrates its effectiveness on density estimation tasks.



![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)