Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PDF, PPTX
2,673 views
[DL輪読会]1次近似系MAMLとその理論的背景
2019/04/12 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 31
2
/ 31
3
/ 31
Most read
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
Most read
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
Most read
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
最適輸送入門
by
joisino
PDF
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
数学で解き明かす深層学習の原理
by
Taiji Suzuki
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
最適輸送入門
by
joisino
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
What's hot
PDF
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PDF
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
PDF
全力解説!Transformer
by
Arithmer Inc.
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PDF
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PPTX
強化学習における好奇心
by
Shota Imai
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
【メタサーベイ】Neural Fields
by
cvpaper. challenge
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
機械学習のためのベイズ最適化入門
by
hoxo_m
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
マルチモーダル深層学習の研究動向
by
Koichiro Mori
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
全力解説!Transformer
by
Arithmer Inc.
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
Attentionの基礎からTransformerの入門まで
by
AGIRobots
深層学習の数理
by
Taiji Suzuki
劣モジュラ最適化と機械学習1章
by
Hakky St
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
強化学習における好奇心
by
Shota Imai
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
Similar to [DL輪読会]1次近似系MAMLとその理論的背景
PDF
論文紹介 Amortized bayesian meta learning
by
Xiangze
PPTX
[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization
by
Deep Learning JP
PPTX
人と機械の協働によりデータ分析作業の効率化を目指す協働型機械学習技術(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
PDF
computer visionen 勉強会
by
ShuNakamura2
PDF
[DL Hacks]Model-Agnostic Meta-Learning for Fast Adaptation of Deep Network
by
Deep Learning JP
PPTX
数理最適化と機械学習の 融合アプローチ -分類と新しい枠組み-(改訂版)
by
MIKIOKUBO3
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
機械学習 入門
by
Hayato Maki
PDF
[DL輪読会]Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer ...
by
Deep Learning JP
PDF
PRML s1
by
eizoo3010
PDF
SAT/SMTソルバの仕組み
by
Masahiro Sakai
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
2020 0906 acl_2020_reading_shared
by
亮宏 藤井
PPTX
[Paper Reading] Variational Sequential Labelers for Semi-Supervised Learning
by
Kazutoshi Shinoda
PPTX
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
PPTX
survey on math transformer 2023 0628 sato
by
satoyuta0112
PPTX
Introduction of the_paper
by
NaokiIto8
PDF
FOBOS
by
Hidekazu Oiwa
論文紹介 Amortized bayesian meta learning
by
Xiangze
[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization
by
Deep Learning JP
人と機械の協働によりデータ分析作業の効率化を目指す協働型機械学習技術(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
computer visionen 勉強会
by
ShuNakamura2
[DL Hacks]Model-Agnostic Meta-Learning for Fast Adaptation of Deep Network
by
Deep Learning JP
数理最適化と機械学習の 融合アプローチ -分類と新しい枠組み-(改訂版)
by
MIKIOKUBO3
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
機械学習 入門
by
Hayato Maki
[DL輪読会]Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer ...
by
Deep Learning JP
PRML s1
by
eizoo3010
SAT/SMTソルバの仕組み
by
Masahiro Sakai
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
2020 0906 acl_2020_reading_shared
by
亮宏 藤井
[Paper Reading] Variational Sequential Labelers for Semi-Supervised Learning
by
Kazutoshi Shinoda
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
survey on math transformer 2023 0628 sato
by
satoyuta0112
Introduction of the_paper
by
NaokiIto8
FOBOS
by
Hidekazu Oiwa
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL輪読会]1次近似系MAMLとその理論的背景
1.
1 1次近似系MAMLとその理論的背景 Naruya Kondo, Matsuo
Lab (B4)
2.
背景 2 • メタ学習の流行 – 複数の似た問題に対して汎用的な能力を得てほしい –
でも、後で特定のタスクには特化できてほしい • MAMLの流行(?) – メタ学習といえばまずはMAML • タスク普遍な、全パラメタの良い初期値を求める – すごく自然な発想 • MAMLは計算コストが高すぎるので1次近似する手法が出ている – ☆割と大事な計算を捨ててなぜうまくいくのか – ☆メタ的に見て良いローカルの更新とは何か – (個人的解釈)基本1次近似系を使っといた方が良さそう
3.
発表内容 3 • 論文 – On
First-Order Meta-Learning Algorithms(OpenAI, 2018) • https://arxiv.org/abs/1803.02999 – MAMLの一次近似手法FOMAMLを拡張した『Reptile』を提案 – 一次近似系MAMLを解析的/実験的に評価 – 後続研究が凄そう(方向性はそれぞれ少し違う) • Transferring Knowledge across Learning Processes(ICLR 2019 oral) • Bayesian Model-Agnostic Meta-Learning(NeurIPS 2018) • Auto-Meta: Automated Gradient Based Meta Learner Search(NeurIPS 2018) • 内容 – 前提知識(メタ学習, joint training, MAML, FOMAML) – 提案手法Reptile – メタ更新の解釈(メタ勾配の向き, パラメタ空間内での振る舞い) – 実験(Reptile v.s. MAML/FOMAML, Reptileの頑健性)
4.
メタ学習 • 複数の似た問題に対して汎用的な能力を得てほしい – 様々な言語での文字認識 –
強化学習(様々な身体的パラメタ/様々な環境/様々な報酬(タスク)) – (汎用AI感?) • 全タスクでのエラーの期待値を最小化したい 4omniglot/Guided Meta-Policy Search
5.
• 恐らく一番単純なmeta-learning手法 • どんなタスクも満遍なくこなせるよう、エラーの期待値を最小化 –
Τ: 全train taskからサンプリング – 評価タスクでは、学習したθ or 少しチューニングしたθ’を使って解く • チューニングで精度が上がる保証は全く無い • 4本足歩行RLの例(あくまでイメージ) – どんな坂道でも歩けるよう、グローバルに良いリズムで足を繰り出す – 結局は平均的な道(≒平坦な道)でしっかり歩けるようにするだけ • 単純だけど、MAMLも半分joint training。 5
6.
joint trainingとの比較を意識して書くと、 • 本当にやりたいのは、評価時のエラーの期待値の最小化 –
学習時(meta-train) • Τ_tr/Τ_val: train taskからサンプリングしたΤをさらに訓練用/評価用に分ける • inner_update & meta_updateを繰り返す。 – 評価時(meta-test) • 解きたいタスクのfew sample/few episodeでチューニング • 必ず良いチューニングができる==良い初期値が得られている。 6https://www.slideshare.net/YoonhoLee4/on-firstorder-metalearning-algorithms
7.
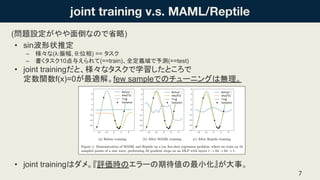
(問題設定がやや面倒なので省略) • sin波形状推定 – 様々な(λ:振幅,
θ:位相) == タスク – 書くタスク10点与えられて(==train)、全定義域で予測(==test) • joint trainingだと、様々なタスクで学習したところで 定数関数f(x)=0が最適解。few sampleでのチューニングは無理。 • joint trainingはダメ。『評価時のエラーの期待値の最小化』が大事。 7
8.
• 実利用上の話、 MAMLはかなりのメモリを消費することが知られている。 – 結果から見れば無駄に計算コストが高い –
inner_updateの回数にほぼ比例してメモリが持ってかれる(後述) • そのため多くのMAML実装ではfew_stepなinner_updateが一般的(主観) • MAMLのmeta-train時の式を一次近似して使うと良いらしい。 – (MAMLが初めに提案された論文にも命名書かれている) – 後にFOMAML(first-order MAML)と命名される 8
9.
• 初期パラメタφの更新 – 二次勾配(L’’(φ))が登場する •
lossをパラメタ数nの2乗回微分(?)←重たい – L_i: iステップ目でのloss, 9 後で囲った 部分それぞ れでα^2以 上の項を無 視してみる
10.
• 二次勾配全部無視(Ui(φi)=φi, →Lkはφ1で発生) •
一番最後のloss == train taskのvalでのlossのみ使う – inner_update時の勾配を保存しない。実装的に自然な発想。 – 恐らくfew stepな更新を前提にしているのでうまくいく 10 φ1 φ2 φ3 φ4 φ5 φ6
11.
• inner_update時の勾配を全部合成する – こちらも二次勾配は無視。 –
パラメータ空間上の動きを見ると こちらの方が自然。 – FOMAMLと比べて計算コストはほぼ増えない – step数が増えても問題ない • 別の解釈 – 最後にたどり着いたパラメタとの差の方向に進む • MAMLの直接的な近似ではない(と思う) 11
12.
transduction: テスト時に渡すデータが1つか複数か(複数の方が簡単) • 遜色なし。(勝手な解釈→)難しいタスクだと、Reptile≧MAML≧FOMAML
12
13.
13 メタ更新の解釈
14.
• ヘッセ行列をまるごと無視していいのか • MAML/FOMAML/Reptileの勾配方向の差には どのような意味があるのか 14 後で囲った 部分それぞ れでα^2以 上の項を無 視してみる
15.
メタ勾配の向き • まず、g_i – Loss関数に依存するが、φ1周りでテイラー展開して α^2以上の項を無視してすべてφ1周りの勾配で表す •
全部φ1周りを計算すれば各地点での勾配を集めて処理しやすくなる 15
16.
メタ勾配の向き • 前2枚のスライドの内容 • を合わせて、 16
17.
メタ勾配の向き • ここから一旦k=2まで(inner_update1回+評価1回)を考える。 • FOMAML/Reptileについても、 •
から同様に – ただし 17 ( )
18.
メタ勾配の向き • 勾配の更新は実際には、複数タスクでの勾配の平均を取る – 平均をとると面白い(平均を取ることに大きな意味がある) 18
19.
メタ勾配の向き • g_barの平均 • H_bar
gの平均 19
20.
メタ勾配の向き • gi_barの平均 – 『−
AvgGrad』方向はjoint trainingに相当している • 「φ1をどっちに更新すればlossが小さくなったのか」 • それがチューニングしやすいかは考慮されてない 20
21.
メタ勾配の向き • Hi_bar gjの平均 –
『AvgGradInner』方向は、各inner_update時の(各ミニバッチ間の)勾配の内積の値 を上げている • 同じタスクなのに違う方向に更新することは過適合している証(たぶん) • タスクに共通な汎化性能の向上に寄与する 21
22.
メタ勾配の向き • 平均を取ると、 • FOMAMLがMAMLから捨てたのはAvgGradInner一回分 –
同じiter回数ならその分だけ性能が落ちる • ReptileはMAMLにAvgGradを+1回、AvgGradInnerを-1回 – Reptileは厳密にはMAMLの一次近似ではないので良し悪しは自明でない。 – AvgGradInnerを増やすには…→inner_update数を増やす 22
23.
メタ勾配の向き • kステップ先まで伸ばすと、 • どの手法も伸ばせば伸ばすほどAvgGradInnerの 割合が高くなる –
伸ばしておけば汎化性があがると考えられる • Reptileはエラーの期待値を高速に下げる効果も この式から期待できる。 23
24.
パラメタ空間内での探索時の振る舞い • Reptileは、パラメタ空間内でユークリッド距離的に最適な場所へ行くことが 示せる • Reptileは暗黙的に以下を行っている(距離の期待値の最小化) –
Wτ: あるタスクτの最適なパラメタのリスト(多様体?) • 最適なパラメタは無数にある(入れ替え可能なパラメタはたくさんあるので) 24 W1 W2
25.
パラメタ空間内での探索時の振る舞い • 現在の初期値φに最も近いWτ内のパラメタをP_Wτとすると • 一つ一つのタスクに注目すると、 •
実際にはP_Wτはわからないので、 これをφkに置き換える • これはReptileのmeta_updateの式と同じ • MAML/FOMAMLには無い良さ 25
26.
26 実験
27.
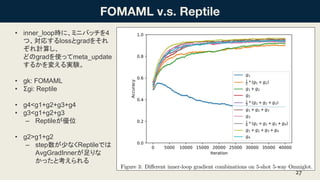
• inner_loop時に、ミニバッチを4 つ、対応するlossとgradをそれ ぞれ計算し、 どのgradを使ってmeta_update するかを変える実験。 • gk:
FOMAML • Σgi: Reptile • g4<g1+g2+g3+g4 • g3<g1+g2+g3 – Reptileが優位 • g2>g1+g2 – step数が少なくReptileでは AvgGradInnerが足りな かったと考えられる 27
28.
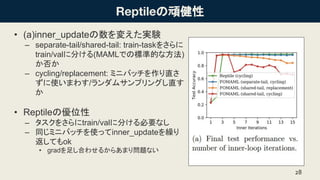
の頑健性 • (a)inner_updateの数を変えた実験 – separate-tail/shared-tail:
train-taskをさらに train/valに分ける(MAMLでの標準的な方法) か否か – cycling/replacement: ミニバッチを作り直さ ずに使いまわす/ランダムサンプリングし直す か • Reptileの優位性 – タスクをさらにtrain/valに分ける必要なし – 同じミニバッチを使ってinner_updateを繰り 返してもok • gradを足し合わせるからあまり問題ない 28
29.
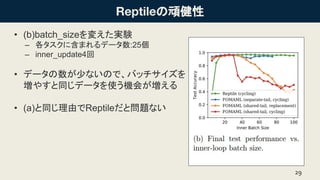
の頑健性 • (b)batch_sizeを変えた実験 – 各タスクに含まれるデータ数:25個 –
inner_update4回 • データの数が少ないので、バッチサイズを 増やすと同じデータを使う機会が増える • (a)と同じ理由でReptileだと問題ない 29
30.
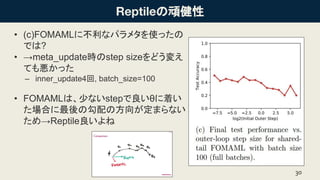
の頑健性 • (c)FOMAMLに不利なパラメタを使ったの では? • →meta_update時のstep
sizeをどう変え ても悪かった – inner_update4回, batch_size=100 • FOMAMLは、少ないstepで良いθに着い た場合に最後の勾配の方向が定まらない ため→Reptile良いよね 30
31.
まとめ • 一次近似MAMLベースの手法Reptileを提案 – 速い収束&頑健性が期待できる •
良い(MAML/勾配法ベースの)メタ学習法とは何かを示した – エラー期待値の最小化 – ステップ間の内積の最大化 – 解探索時の振る舞い • MAMLを使う際は一旦一次近似版を考えてみるべき 31
Download





























![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks]Model-Agnostic Meta-Learning for Fast Adaptation of Deep Network](https://cdn.slidesharecdn.com/ss_thumbnails/maml-181024060235-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer ...](https://cdn.slidesharecdn.com/ss_thumbnails/180302nonaka-180309041654-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Paper Reading] Variational Sequential Labelers for Semi-Supervised Learning](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180920-shinoda-181013064657-thumbnail.jpg?width=640&height=640&fit=bounds)























