* Satoshi Hara and Kohei Hayashi. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. AISTATS'18 (to appear).
arXiv ver.: https://arxiv.org/abs/1606.09066#
* GitHub
https://github.com/sato9hara/defragTrees
論文とコード
n Satoshi Haraand Kohei Hayashi. Making Tree Ensembles Interpretable: A
Bayesian Model Selection Approach. AISTATS'18 (to appear).
• arXiv ver.: https://arxiv.org/abs/1606.09066#
n GitHub
• https://github.com/sato9hara/defragTrees
2
3.
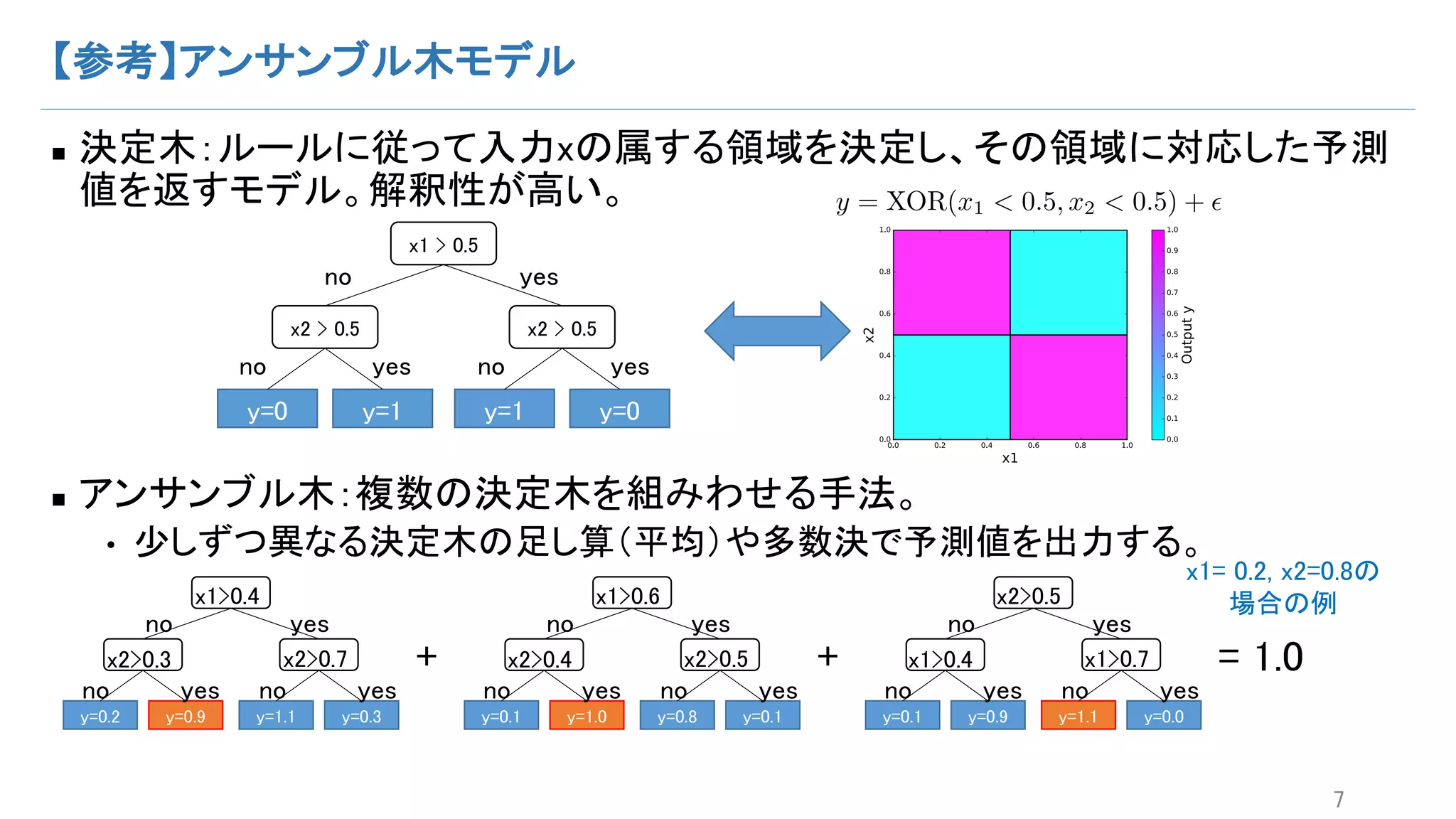
背景(1):機械学習で得られた予測を人の意思決定に使いたい。
n 機械学習モデルの予測精度は年々高まっている。SVM→Boosting→Deep
• Kaggleなどの予測コンペではBoostingやDeepLearningがよく使われている。
n 機械学習で得られた予測を人の意思決定に使いたい。
• 売り上げ予測に基づく経営戦略の立案、製品の在庫需要予測に基づく製造計画の
策定など。
n しかし、機械学習の予測はブラックボックス。意思決定に使いづらい。
• 機械学習モデルからは予測値だけが得られる。どのような経緯でその予測値が得ら
れたかは不明なことが多い。
• 機械学習モデルを解釈したい。予測を人が理解できるようにしたい。
- モデルがどのような経緯で予測値を出したか知りたい。
- 「来週の気温は高いのでアイスの売り上げ増が見込める。」
- モデルが適切に学習されているか確認したい。
- 実用上役に立たないはずの特徴量が偶然予測モデルに組み込まれてしまうのを防ぎたい。
- KDD Cup’08で優勝したモデルは「患者ID」と「癌の予測」を結びつけた不適切なモデル。
3
4.
背景(2) :モデルを解釈したい。でも予測精度は落としたくない。
n 解釈可能な機械学習モデルは一般に予測精度が高くない。
•線形モデルや決定木が解釈可能なモデルとして一般に使われている。しかし、これ
らのモデルは予測精度が低い傾向がある。
• 決定木を拡張して、解釈性と予測精度を
両立させようという研究が多い。
(e.g., Eto et al., AISTATS’14, Wang et al., KDD’15)
n 解釈性のために予測精度を犠牲にしたくない。
• 意思決定のためには精度の高い予測が不可欠。
• 予測精度を犠牲にしたくない。
4
解釈性
予測精度
トレードオフ:
予測精度を犠牲に
解釈性を向上させ
る。
解釈性
予測精度
目指したいのはここ
目次
n 研究背景
n 研究目的と課題
n既存研究
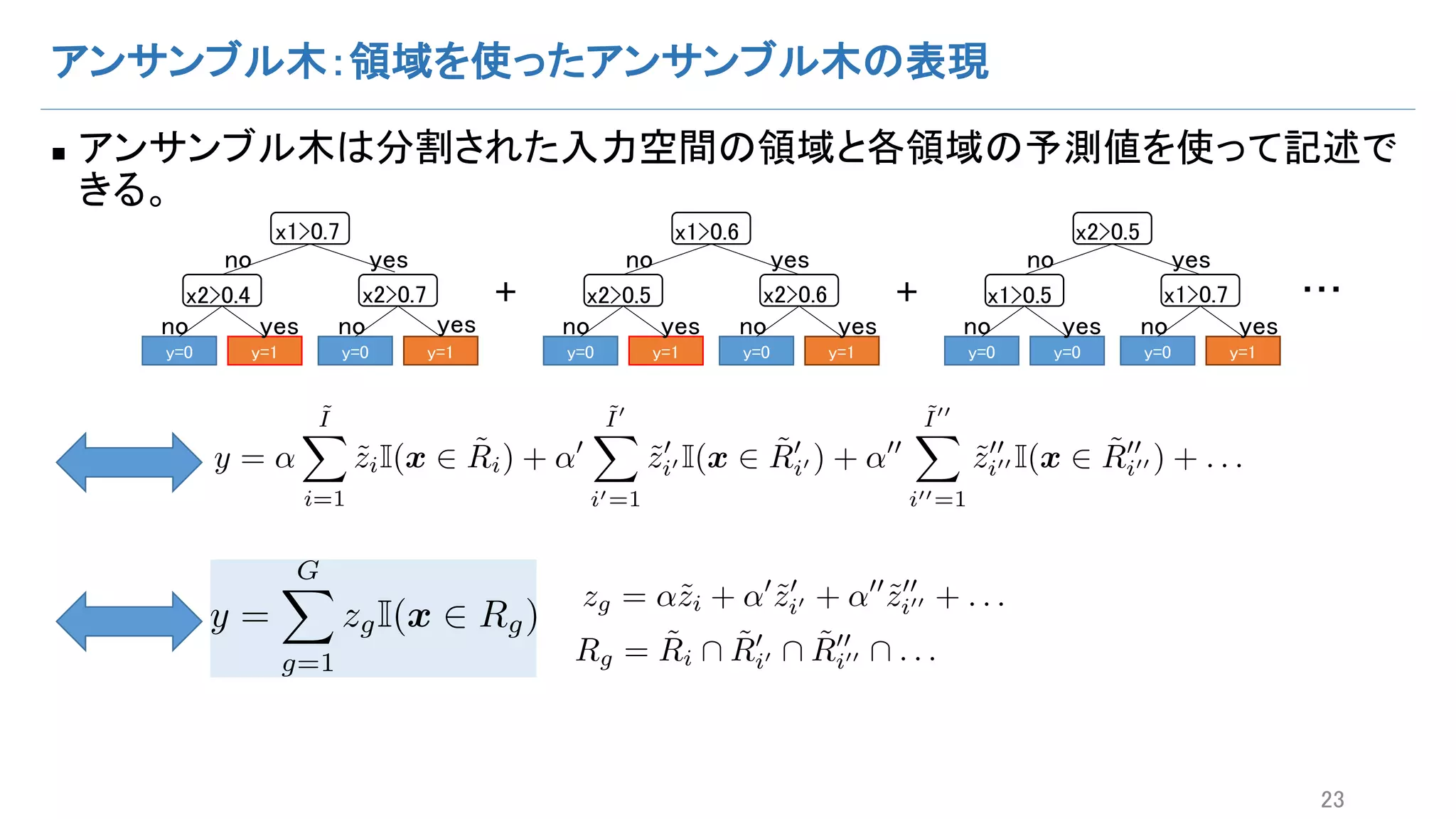
n 問題:アンサンブル木の簡略化
n 提案法
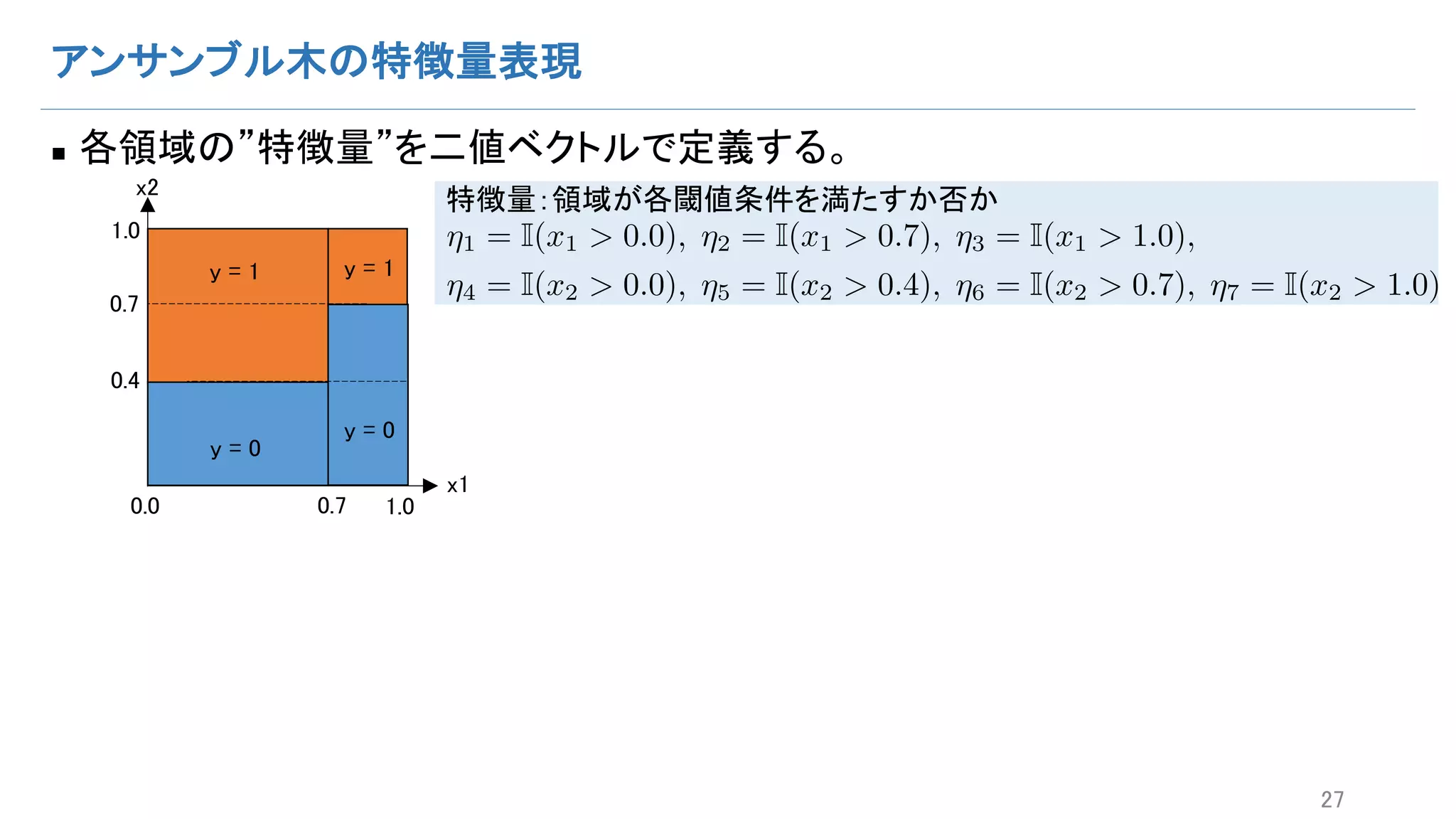
• アンサンブル木の確率的生成モデルによる表現
• EMアルゴリズム
• FAB Inference
n 実験
• 実験設定
• EM vs. FAB
• 提案法 vs. 既存手法
n まとめ 50
51.
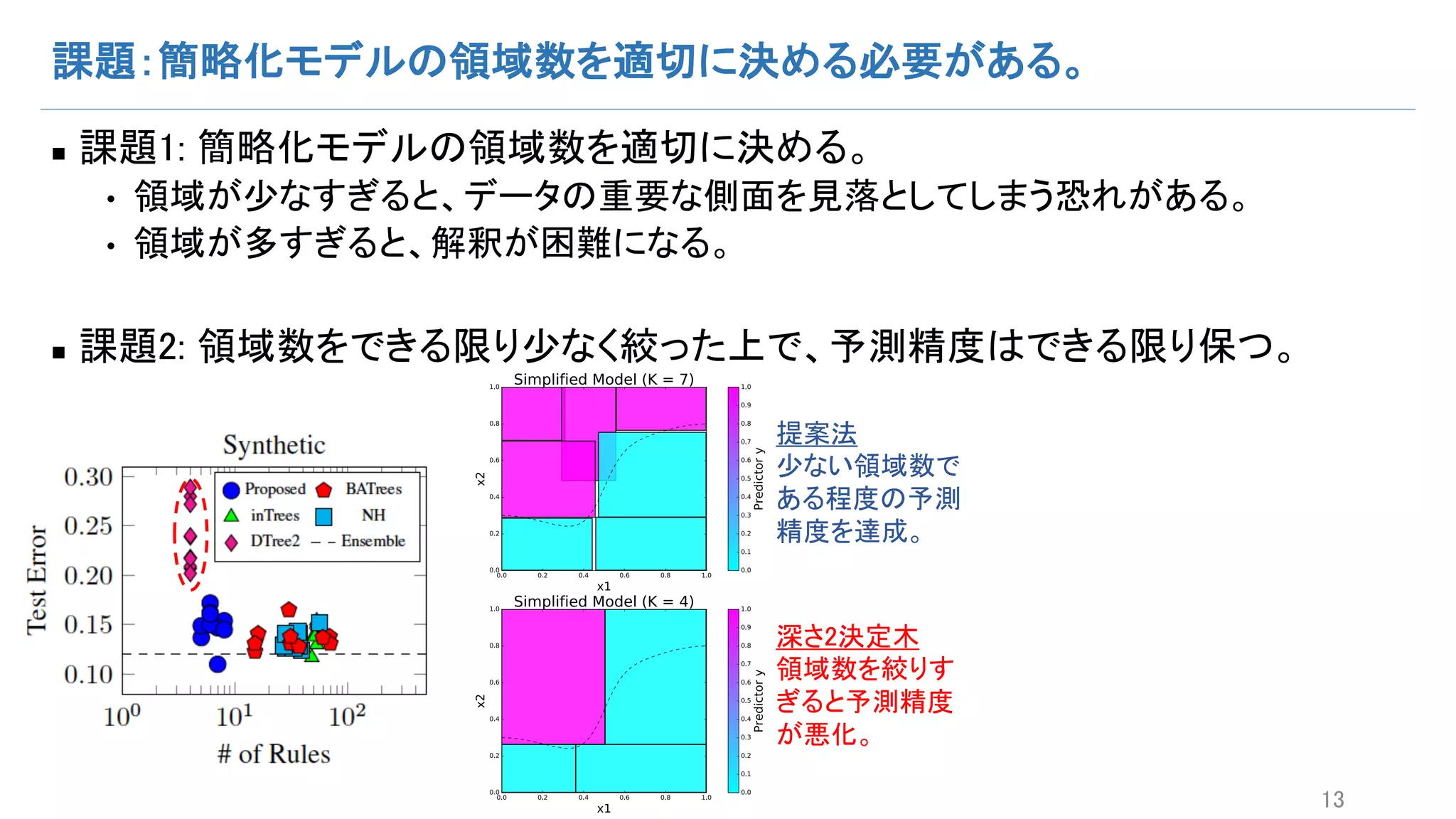
EM vs. FAB– 1:領域数の比較
n EMアルゴリズムでは適切な領域数Kを決定するために、様々なKを試してその中
で良い結果をピックアップする必要がある。
51
どのデータでも、FABはテスト誤差がほぼ最小になる領域数を選択できている。
EMのように様々なKを試すことなく適切な領域数が自動決定されている。
52.
EM vs. FAB– 2:計算時間の比較
n EMアルゴリズムでは適切な領域数Kを決定するために、様々なKを試してその中
で良い結果をピックアップする必要がある。
n EMアルゴリズムをKを変えて問題を解き直すだけ時間がかかる。
• 本実験ではKを1~10の間で変えて計算した。
52
FABはKを変えて計算し直さなくて良いだけ速い。
実験ではEMより5~20倍程度速かった。
53.
目次
n 研究背景
n 研究目的と課題
n既存研究
n 問題:アンサンブル木の簡略化
n 提案法
• アンサンブル木の確率的生成モデルによる表現
• EMアルゴリズム
• FAB Inference
n 実験
• 実験設定
• EM vs. FAB
• 提案法 vs. 既存手法
n まとめ 53
54.
提案法 vs. 既存手法
n比較対象
• 既存手法
- Born Again Trees (BATrees)
- inTrees
- Node Harvest (NH)
• 他のベースライン
- DTree2
- 深さ2の決定木(ルール数4のモデル)。少ないルール数のモデルの代表として導入。同じく
少ないルール数のモデルを学習する提案法との比較のためのベースライン。
- Ensemble
- もとのランダムフォレスト。予測精度の比較のために導入。
- 簡略化モデルのテスト誤差がランダムフォレストの予測誤差に近いほど良い。
54
55.
提案法 vs. 既存手法:提案法が少ルール、低誤差を達成
nルール数 vs. テスト誤差
55
提案法の結果が全体的に左下
にある。
つまり、少ないルール数で低い
テスト誤差を達成できた。
既存手法は全体的にルール数
が多かった(30~200程度)。
DTree2はルール数が少ないた
め予測誤差が高めだった。
56.
提案法 vs. 既存手法:提案法が少ルールでモデル簡略化を達成
n学習された簡略化モデルの例(Synthetic)
56
真のデータ 提案法
Born Again Trees inTrees Node Harvest
他の手法よりも少ない領域数で
モデルを簡略化できた。
少し領域数多め 領域数非常に多い
重複も大きい
重複が非常に
大きい
57.
【参考】提案法はルール間の重複が少ない。
n inTreesはルール間の重複が大きい。
n NodeHarvestはアンサンブルなのでルール間の重複が非常に大きい。
n 提案法も一部ルール間に重複が発生する場合がある。
• 確率的生成モデルとして領域の定義を緩和したため。
n 提案法の重複度合いはinTrees, Node Harvestよりも小さい。
• 提案法の重複度合いは1に近い(=ほぼ重複がない)。
• inTrees, Node Harvestの重複度合いは5~10程度と大きい。
57
58.
まとめ
n アンサンブル木モデルを簡略化する方法を提案した。
• モデル簡略化をベイズモデル選択の問題として定式化した。
-アンサンブル木モデルを確率的生成モデルとして表現することで、ベイズモデル選択が使えるよ
うになった。
- FAB Inferenceを使うことでモデル選択の計算を効率化した。
n 実験により、FABがEMより効率的であることを確認した。
• FABはEMを使った領域数探索よりも5~20倍程度速かった。
n 実験により、提案法を使うことで「少ないルール」で「低い予測誤差」を達成できる
ことを確認した。
• 既存手法のBorn Again Trees, inTrees, Node Harvestはどれもルール数が多くなる
傾向があった。
• 提案法を使うことで「少ないルール数」によるモデルの簡略化という、モデル解釈に
おいて重要な目的を達成できた。 58




































![【参考】EMアルゴリズムによるパラメータ推定 - 更新式
n EMの下限
n Eステップ:潜在変数の分布 の最適化
n Mステップ:モデルパラメータ の最適化
41
エントロピー
⌘k` =
PN
n=1 q(u
(n)
k )s
(n)
`
PN
n=1 q(u
(n)
k )
↵k =
1
N
NX
n=1
q(u
(n)
k ) k の更新も解析的に計算可能
LB =
NX
n=1
KX
k=1
Eq(U)[u
(n)
k ] log p(y(n)
| k) +
LX
`=1
log ⌘
s
(n)
`
k` (1 ⌘k`)1 s
(n)
` + log ↵k
!
+ H(q(U))
q(U)
⇧
q(u
(n)
k ) / p(y(n)
| k)
LY
`=1
⌘
s
(n)
`
k` (1 ⌘k`)1 s
(n)
` ↵k](https://image.slidesharecdn.com/haraaistats18-180402025819/75/slide-41-2048.jpg)


![FAB: Factorized Asymptotic Bayesian Inference
(Fujimaki et al., AISTATS’12, Hayashi et al., ICML’15)
n 対数周辺尤度を最大化して、パラメータ と領域数Kを同時決定する。
• 潜在変数モデルに対するラプラス近似を使って周辺対数尤度を近似する。
- ただし、 , は のヘシアン,
, はエントロピー。
n FABでは上記近似式の下限をEM-likeに最適化する。
44
log p(D|K) ⇡ Eq⇤(U)
log p(D, U|⇧, K)
1
2
log det Fˆ⇧ + H(q⇤
(U))
dim⇧
2
log N
Fˆ⇧
ˆ⇧ = argmax⇧ log p(D, U|⇧, K) log p(D, U|⇧, K)/N
q⇤
(U) = p(U|D, K)
⇧
H
LB =
NX
n=1
KX
k=1
Eq(U)[u
(n)
k ] log p(y(n)
| k) +
LX
`=1
log ⌘
s
(n)
`
k` (1 ⌘k`)1 s
(n)
` + log ↵k
!
!
KX
k=1
log
NX
n=1
Eq(U)[u
(n)
k ] + 1
!
+ H(q(U))
! =
dim( k) + L + 1
2](https://image.slidesharecdn.com/haraaistats18-180402025819/75/slide-44-2048.jpg)
![【参考】FABの下限はEMの下限に”正則化項”を加えたもの
n EM下限
n FAB下限
45
LB =
NX
n=1
KX
k=1
Eq(U)[u
(n)
k ] log p(y(n)
| k) +
LX
`=1
log ⌘
s
(n)
`
k` (1 ⌘k`)1 s
(n)
` + log ↵k
!
+ H(q(U))
追加の”正則化項”
この項により、領域数の自動決定が可能となる(次頁)。
LB =
NX
n=1
KX
k=1
Eq(U)[u
(n)
k ] log p(y(n)
| k) +
LX
`=1
log ⌘
s
(n)
`
k` (1 ⌘k`)1 s
(n)
` + log ↵k
!
!
KX
k=1
log
NX
n=1
Eq(U)[u
(n)
k ] + 1
!
+ H(q(U))](https://image.slidesharecdn.com/haraaistats18-180402025819/75/slide-45-2048.jpg)






















![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)






























