Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
11,670 views
[DL輪読会]When Does Label Smoothing Help?
2019/12/27 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 30 times
1
/ 46
2
/ 46
3
/ 46
4
/ 46
5
/ 46
6
/ 46
7
/ 46
8
/ 46
9
/ 46
10
/ 46
Most read
11
/ 46
Most read
12
/ 46
13
/ 46
14
/ 46
15
/ 46
16
/ 46
Most read
17
/ 46
18
/ 46
19
/ 46
20
/ 46
21
/ 46
22
/ 46
23
/ 46
24
/ 46
25
/ 46
26
/ 46
27
/ 46
28
/ 46
29
/ 46
30
/ 46
31
/ 46
32
/ 46
33
/ 46
34
/ 46
35
/ 46
36
/ 46
37
/ 46
38
/ 46
39
/ 46
40
/ 46
41
/ 46
42
/ 46
43
/ 46
44
/ 46
45
/ 46
46
/ 46
More Related Content
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
最適輸送入門
by
joisino
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
最適輸送入門
by
joisino
最適輸送の計算アルゴリズムの研究動向
by
ohken
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
What's hot
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
不老におけるOptunaを利用した分散ハイパーパラメータ最適化 - 今村秀明(名古屋大学 Optuna講習会)
by
Preferred Networks
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
最適輸送の解き方
by
joisino
PPTX
強化学習における好奇心
by
Shota Imai
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
12. Diffusion Model の数学的基礎.pdf
by
幸太朗 岩澤
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
深層生成モデルと世界モデル
by
Masahiro Suzuki
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
不老におけるOptunaを利用した分散ハイパーパラメータ最適化 - 今村秀明(名古屋大学 Optuna講習会)
by
Preferred Networks
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
最適輸送の解き方
by
joisino
強化学習における好奇心
by
Shota Imai
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
深層学習の数理
by
Taiji Suzuki
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
モデル高速化百選
by
Yusuke Uchida
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
12. Diffusion Model の数学的基礎.pdf
by
幸太朗 岩澤
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
Similar to [DL輪読会]When Does Label Smoothing Help?
PDF
【DL輪読会】Learning Instance-Specific Adaptation for Cross-Domain Segmentation (E...
by
Deep Learning JP
PDF
「解説資料」Pervasive Label Errors in Test Sets Destabilize Machine Learning Bench...
by
Takumi Ohkuma
PDF
シリーズML-08 ニューラルネットワークを用いた識別・分類ーシングルラベルー
by
Katsuhiro Morishita
PPTX
DNNの曖昧性に関する研究動向
by
Naoki Matsunaga
PPTX
Noisy Labels と戦う深層学習
by
Plot Hong
PPTX
Deep Learning基本理論とTensorFlow
by
Tadaichiro Nakano
PPTX
Icml2019 kyoto ohno_ver20190805
by
Shuntaro Ohno
PDF
Snlp2016 kameko
by
Hirotaka Kameko
PPTX
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
PDF
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
PDF
Journal club dec24 2015 splice site prediction using artificial neural netw...
by
Hiroya Morimoto
PDF
TensorFlow DevSummitを概観する
by
Y OCHI
PDF
SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜
by
SSII
PDF
論文紹介:"RAt: Injecting Implicit Bias for Text-To-Image Prompt Refinement Models...
by
Toru Tamaki
PDF
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PPTX
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
PDF
[論文紹介] Convolutional Neural Network(CNN)による超解像
by
Rei Takami
PDF
深層学習入門
by
Danushka Bollegala
【DL輪読会】Learning Instance-Specific Adaptation for Cross-Domain Segmentation (E...
by
Deep Learning JP
「解説資料」Pervasive Label Errors in Test Sets Destabilize Machine Learning Bench...
by
Takumi Ohkuma
シリーズML-08 ニューラルネットワークを用いた識別・分類ーシングルラベルー
by
Katsuhiro Morishita
DNNの曖昧性に関する研究動向
by
Naoki Matsunaga
Noisy Labels と戦う深層学習
by
Plot Hong
Deep Learning基本理論とTensorFlow
by
Tadaichiro Nakano
Icml2019 kyoto ohno_ver20190805
by
Shuntaro Ohno
Snlp2016 kameko
by
Hirotaka Kameko
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
Journal club dec24 2015 splice site prediction using artificial neural netw...
by
Hiroya Morimoto
TensorFlow DevSummitを概観する
by
Y OCHI
SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜
by
SSII
論文紹介:"RAt: Injecting Implicit Bias for Text-To-Image Prompt Refinement Models...
by
Toru Tamaki
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
[論文紹介] Convolutional Neural Network(CNN)による超解像
by
Rei Takami
深層学習入門
by
Danushka Bollegala
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
Recently uploaded
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
[DL輪読会]When Does Label Smoothing Help?
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ When Does Label Smoothing help? (NeurIPS2019) MasashiYokota, RESTAR Inc.
2.
書誌情報 • 著者 – Rafael
Müller, Simon Kornblith, Geoffrey Hintonら Google Brainの研究チーム – NeurIPS2019 採択 • Penultimate layer(Softmax層の一つ前の層) を線形な方法で二次 元平面に可視化。それによりLabel Smoothingの効果の直感的な 理解を可能にし、さらにLabel Smoothingについて深く分析した。 2
3.
1. 概要 3
4.
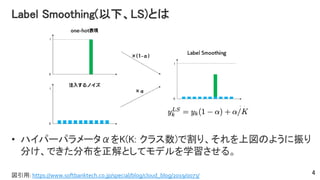
Label Smoothing(以下、LS)とは • ハイパーパラメータαをK(K:
クラス数)で割り、それを上図のように振り 分け、できた分布を正解としてモデルを学習させる。 4図引用: https://www.softbanktech.co.jp/special/blog/cloud_blog/2019/0073/
5.
1. 概要 LSは様々なタスクやモデルで使われている。一方で、なぜ 性能が上がるのかわかっていない。本論文ではLSを分析し、その 理解を深めた。 5
6.
1. この論文の貢献 • Penultimate
layer(Softmax層の一つ前の層)の可視化方法の提案 • LSがキャリブレーション効果があることを発見 • LSが蒸留に向いていないことの発見 6
7.
2. Penultimate layer
representations 7
8.
Label Smoothing再考 LSの説明の前にHard Targetについて考える Hard
Target 正解ラベルの値を1、それ以外を0として学習させる • できるだけ正解クラスのlogitと不正解クラスのlogitが 大きくなるようにモデルのパラメータを更新する。 • 不正解クラスのlogitと正解クラスのlogitは 単にできるだけ離れていれば良い 8
9.
Label Smoothing再考 Label Smoothing –
xはPenultimate layerの出力, 𝒘 𝒌 はk 番目クラスのtemplate(重み)とする とk番目のクラスのlogit ( 𝒙 𝑻 𝒘 𝒌 )は以下のようにユークリッド距離の二乗 𝒙 − 𝒘 𝒌 2 と考えられる: LSでは 𝒙 − 𝒘 𝒌 2 がパラメータαに依存した定数となるように学習されるの で「正解クラスのtemplateと全ての不正解クラスのtemplateが等距離にな るように学習している」と考えられる 9 重みによらないので Factored out k番目クラスのとき 常に同じなので Factored out
10.
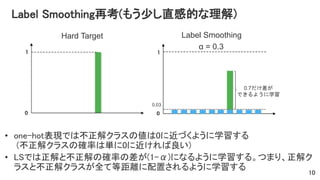
Label Smoothing再考(もう少し直感的な理解) • one-hot表現では不正解クラスの値は0に近づくように学習する (不正解クラスの確率は単に0に近ければ良い) •
LSでは正解と不正解の確率の差が(1-α)になるように学習する。つまり、正解ク ラスと不正解クラスが全て等距離に配置されるように学習する 10 0.03 0.7だけ差が できるように学習 α = 0.3 Hard Target Label Smoothing
11.
先の考察の検証 以下の条件でPenultimate Layersを可視化・定性分析し、 先の考察の検証を行う。 • 検証モデル/データセット –
AlexNet/CIFAR-10 – ResNet-56/CIFAR-100 – Inception-v4/ImageNet • 非類似クラス3つ • 類似クラス2つ+非類似クラス1つ 11
12.
Penultimate layerの可視化方法 Penultimate layerを以下のプロセスで可視化し定性分析する 1.
3つのクラスをピックアップ 2. 選んだクラスの重み上にある平面の正規直行基底を計算 3. 先のステップの平面にPenultimate layerの出力をサンプリングし 可視化 12
13.
ちなみに…各条件でのLSの有無による性能の変化 各モデル/データセットの組み合わせでのLSの効果をみる。 LSの有無では性能は微妙によくなる or 変化なし。 13
14.
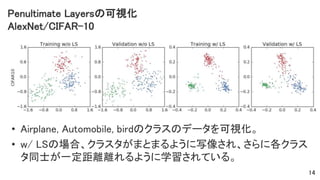
Penultimate Layersの可視化 AlexNet/CIFAR-10 • Airplane,
Automobile, birdのクラスのデータを可視化。 • w/ LSの場合、クラスタがまとまるように写像され、さらに各クラス タ同士が一定距離離れるように学習されている。 14
15.
• Beaver, Dolphin,
Otterの3クラスをvisualize • w/ LSの場合、明確に密集したクラスタがつくられ、各クラスタは 等距離に写像されるように学習されている 15 Penultimate Layersの可視化 ResNet-56/CIFAR-100
16.
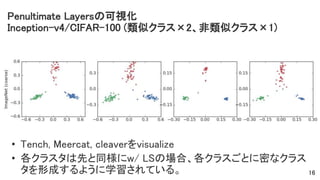
• Tench, Meercat,
cleaverをvisualize • 各クラスタは先と同様にw/ LSの場合、各クラスごとに密なクラス タを形成するように学習されている。 16 Penultimate Layersの可視化 Inception-v4/CIFAR-100 (類似クラス×2、非類似クラス×1)
17.
• Tench, toy
poodle, miniature poodleの3クラスをvisualize • w/o LSでは、似ているクラス同士が一つのクラスタになってしまう。一方で、w/LSで は異なるクラスのクラスタを中心とした円弧上に配置される。 • クラス間の情報は仮想的に消されてしまっている 17 Penultimate Layersの可視化 Inception-v4/CIFAR-100 (類似クラス×2、非類似クラス×1)
18.
• Tench, toy
poodle, miniature poodleの3クラスをvisualize • w/o LSでは、似ているクラス同士が一つのクラスタになってしまう。一方で、w/LSで は異なるクラスのクラスタを中心とした円弧上に配置される。 • クラス間の情報は仮想的に消されてしまっている 18 Penultimate Layersの可視化 Inception-v4/CIFAR-100 (類似クラス×2、非類似クラス×1)
19.
先の検証でわかったこと • 正解クラスと他の不正解クラスがそれぞれ一定の距離分、離れる ように学習させる →over confidence問題(モデルが自信を持って回答しているのに それが外れてしまう問題)が発生しにくいと考えられる (3.
Implicit model calibration に続く) • ただし正解クラスに似ているクラス同士は、不正解クラスを中心と した円の弧の上に写像される →logit内での相互情報量を落としていると考えられる (4. Knowledge Distillationに続く) 19
20.
3. Implicit model
calibration 20
21.
Calibrationとは • Calibration (もしくはConfidence
Calibration)とは: モデルが出した確率がその正答率を反映できるようにモデルを学 習させることを目的にした研究課題 • CalibrationはGuoらの研究[ICML 2017]で提案されたEstimated Calibration Error(ECE)により評価できる 21
22.
ECEとは • データサンプル全てに関して、モデルのconfidenceの値ごとにM等 分し、それぞれのbinを用いて以下を計算する: 𝐵 𝑚:m番目のbin,
M: binの数, n: サンプル数 22 bin毎にaccuracyを計算 bin毎にconfidenceを計算 ( 𝑝𝑖: confidence)
23.
Implicit model calibrationの検証 検証したいこと:
LSによりcalibrationができたかどうか • 実験条件 – ECEの計算に用いるbin数: 15 • 比較手法 ① w/o LS (baseline) ② w/ LS ③ w/ temperature scaling (以下、TSと表記。なお、先行研究でCalibrationに有効と検証済み) • 実験内容 1. Image Classification • ResNet-56/CIFAR-100 • Inception-v4/ImageNet 2. Machine Translation • Transformer architecture / English-German translation 23
24.
Implicit model calibration ResNet-56/CIFAR-100 •
完全にcalibrationされている 場合、黒の点線と重なる • LSはTSと同レベルに calibrationされている 24
25.
Implicit model calibration Inception-v4/ImageNet •
完全にcalibrationされている 場合、黒の点線と重なる • LSはTSより、やや劣るが baselineよりもcalibrationされ ている 25
26.
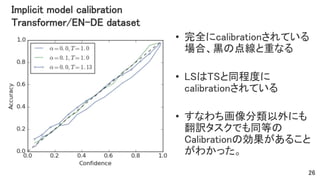
Implicit model calibration Transformer/EN-DE
dataset • 完全にcalibrationされている 場合、黒の点線と重なる • LSはTSと同程度に calibrationされている • すなわち画像分類以外にも 翻訳タスクでも同等の Calibrationの効果があること がわかった。 26
27.
Implicit model calibration ECEでの比較 •
Inception-v4/ImageNetでのLSはTSに比べてやや劣るが、他では TSと同程度calibrateできている 27
28.
先の実験でわかったことと次の疑問 • わかったこと – LSはTSと同程度にCalibrationできていることがわかった •
次の疑問 – LSとTSを組み合わせれば、もっとよくなるのではないか? 28 MachineTranslationに関して、LSの有無やTSの温度が BLEUやECE、NLLにどのような変化を与えるのか確かめる
29.
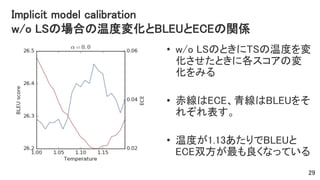
Implicit model calibration w/o
LSの場合の温度変化とBLEUとECEの関係 • w/o LSのときにTSの温度を変 化させたときに各スコアの変 化をみる • 赤線はECE、青線はBLEUをそ れぞれ表す。 • 温度が1.13あたりでBLEUと ECE双方が最も良くなっている 29
30.
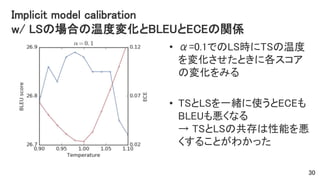
Implicit model calibration w/
LSの場合の温度変化とBLEUとECEの関係 • α=0.1でのLS時にTSの温度 を変化させたときに各スコア の変化をみる • TSとLSを一緒に使うとECEも BLEUも悪くなる → TSとLSの共存は性能を悪 くすることがわかった 30
31.
Implicit model calibration LSの有無と温度とNLLの関係 •
マーカーあり: w/ LS • マーカなし: w/o LS • LSはNLLに対して悪い影響を与え ている。(ただし、LSを使った方が BLEUは良くなる) 31
32.
Implicit model calibrationでわかったこと •
LSはTSとImage ClassificationとMachine Translationにおいて同程 度にCalibrationができることがわかった • LSとTSを共存させると逆に悪くなり、共存はできないことがわかっ た 32
33.
4. Knowledge distillation 33
34.
Knowledge distillation • ここで確かめたいこと –
LSはlogit間の相互情報量まで落としていると考えられ相互情報量が重 要な蒸留では、LSは悪影響を与えるのではないか? • 上記は筆者らは以下の簡易的な実験でもその傾向はわかる – MLPのteacherモデルを使ってMNISTを学習。学習したteacherモデルを studentモデルに蒸留すると以下のような結果になる。 w/o LS teacherで蒸留 : train: 0.67%, test: 0.74% w/ LS LS teacherで蒸留: train: 0.59%, test: 0.91% → LSは蒸留に良くない影響を与えていることがわかる 34
35.
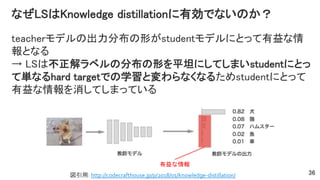
なぜLSはKnowledge distillationに有効でないのか? Knowledge Distillationおさらい 教師モデルの出力を教師とするsoft
target lossと通常の学習 の hard target lossの組み合わせでstudentモデルを学習 35図引用: http://codecrafthouse.jp/p/2018/01/knowledge-distillation/
36.
なぜLSはKnowledge distillationに有効でないのか? teacherモデルの出力分布の形がstudentモデルにとって有益な情 報となる → LSは不正解ラベルの分布の形を平坦にしてしまいstudentにとっ て単なるhard
targetでの学習と変わらなくなるためstudentにとって 有益な情報を消してしまっている 36 有益な情報 図引用: http://codecrafthouse.jp/p/2018/01/knowledge-distillation/
37.
Knowledge distillation • 以下の内容を確認し、LSがどれくらい蒸留に悪影響を与えるのか 調査 1.
w/ LS teacher のaccuracy 2. 蒸留なしのstudentのaccuracy 3. w/o LS Teacher を利用して蒸留したw/ TS studentのaccuracy 4. w/ LS Teacherを利用して蒸留したstudentのaccuracy ※なお、Teacherからの蒸留する場合、hard targetは使わず Teacherの出力分布のみを使ってstudentは学習する。 37
38.
Knowledge distillation LSの有無による蒸留後の性能の差 • Teacher
w/ LSは0.6まで精 度は上がっている • Teacher w/ LSを用いて蒸 留したstudentは性能が ベースラインと同程度。 Teacher w/ TSの蒸留と比 べて性能が劣る → 蒸留に重要なlogit間の 相互情報量が落ちてしまっ ていると考えられる 38
39.
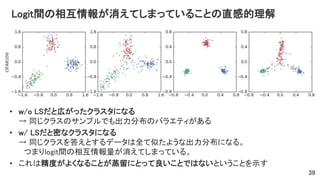
Logit間の相互情報が消えてしまっていることの直感的理解 • w/o LSだと広がったクラスタになる →
同じクラスのサンプルでも出力分布のバラエティがある • w/ LSだと密なクラスタになる → 同じクラスを答えとするデータは全て似たような出力分布になる。 つまりlogit間の相互情報量が消えてしまっている。 • これは精度がよくなることが蒸留にとって良いことではないということを示す 39
40.
Logit間の相互情報量を考える 1 /
2 Inputとlogitの多次元かつ分布不明なデータの相互情報量を計算す るのは困難。以下の仮定を元に簡易的に相互情報量を計算 – X: 入力画像, Y: 2クラス間のロジットの差 – Yの分布をガウス分布とし、Xをランダムにshiftしてモンテカルロサンプリ ングすることで平均𝜇 𝑥と分散𝜎2を求める – d(・): 画像をランダムにshiftする関数, f(・): 学習済みモデル, L: モンテカルロのサンプル数, N: Trainingデータのサンプル数 40
41.
Logit間の相互情報量を考える 2 /
2 • 上記の式の値は、0からlog(N)の範囲に収まる • 0の時は、全てのデータ点が1つのポイントに集まった状態で、そ れは相対エントロピーが0であることを示す。 • log(N)の時は、N個全てのデータ点がバラバラになっている状態。 41
42.
Knowledge distillation Logit間の相互情報量が落ちているのか検証 • N=600として2つのクラス間の 相互情報量を計算 •
明らかにw/ LSの場合は、相 互情報量が落ちていることが 確認できる • 点線のlog(2)は、全てのサンプ ルが完全に2つのクラスタに別 れた状態 →w/ LSのteacherはかなり log(2)に近い状態といえる。 42
43.
5. 関連研究 43
44.
Do Better ImageNet
Models Transfer Better? [Kornblith+ 2019] ImageNetで良い性能を出しているモデルを転移学習させても良い性能が出るのかを調査。(この論文 では他にも調査しているが)LSは転移学習に良い影響を与えないことが実験的にわかった。おそらくこ れもLSが何かしらの情報量を落としてしまっていると考えられる。 44
45.
Future Work • 筆者ら曰く、LSが相互情報量を落としていることの発見を応用し 以下の様々な分野の研究を加速させる可能性がある –
information bottleneck principle – モデル圧縮 – モデルの汎化 – 転移学習 • また、LSにCalibrationを進める効果もモデル解釈可能性に関する 研究分野に関しても大きなインパクトらしい。 45
46.
まとめ • Penultimate layerを可視化し、Label
Smoothingの定性的な効果と して「正解クラスと他の他の不正解クラスの距離が全て等距離に なるように学習する」ことを発見した • Label Smoothingにはcalibration効果があることを発見した • 画像分類や翻訳タスクにはLabel Smoothingの効果がある一方で、 蒸留には不向きであることがわかった • 蒸留には不向きである理由として、logit間の相互情報量が落ちて いることが原因であることがわかった • これらの発見は、いろんな研究分野で有益な発見である 46
Editor's Notes
#17
Penultimate Layersの可視化 Inception-v4/CIFAR-100 (非類似クラス×3)
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
When Does Label Smoothing help? (NeurIPS2019)
MasashiYokota, RESTAR Inc.](https://image.slidesharecdn.com/yokota20191227dl-191227001522/85/DL-When-Does-Label-Smoothing-Help-1-320.jpg)















![Calibrationとは
• Calibration (もしくはConfidence Calibration)とは:
モデルが出した確率がその正答率を反映できるようにモデルを学
習させることを目的にした研究課題
• CalibrationはGuoらの研究[ICML 2017]で提案されたEstimated
Calibration Error(ECE)により評価できる
21](https://image.slidesharecdn.com/yokota20191227dl-191227001522/85/DL-When-Does-Label-Smoothing-Help-21-320.jpg)

















![Do Better ImageNet Models Transfer Better?
[Kornblith+ 2019]
ImageNetで良い性能を出しているモデルを転移学習させても良い性能が出るのかを調査。(この論文
では他にも調査しているが)LSは転移学習に良い影響を与えないことが実験的にわかった。おそらくこ
れもLSが何かしらの情報量を落としてしまっていると考えられる。 44](https://image.slidesharecdn.com/yokota20191227dl-191227001522/85/DL-When-Does-Label-Smoothing-Help-44-320.jpg)



![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)















![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)

































