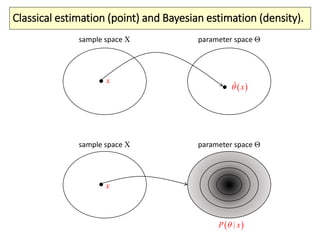
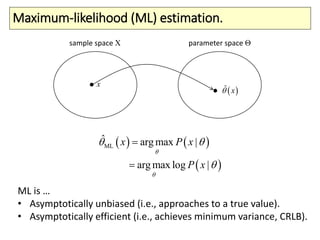
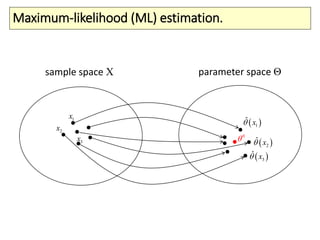
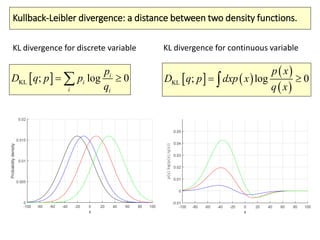
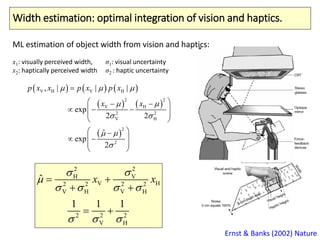
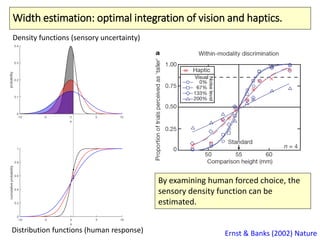
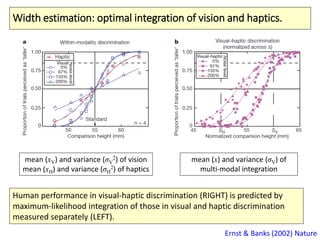
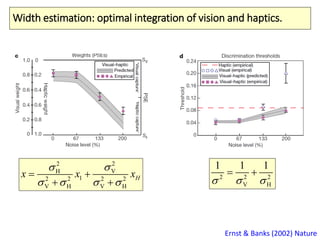
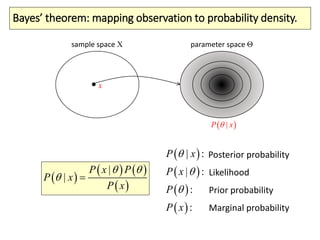
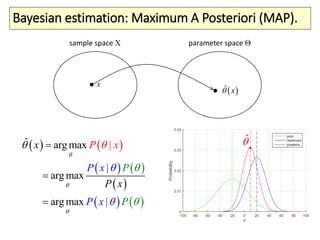
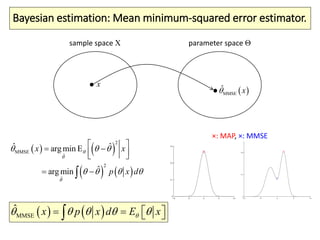
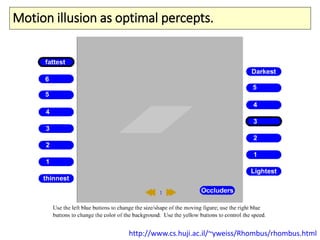
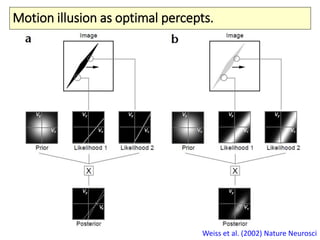
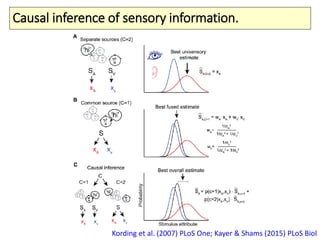
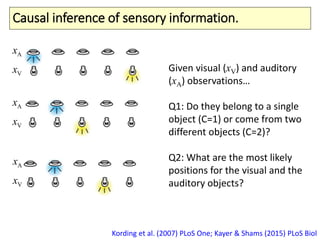
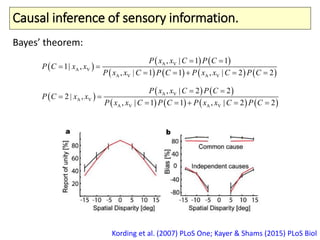
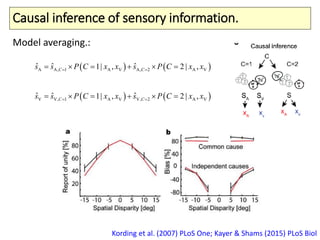
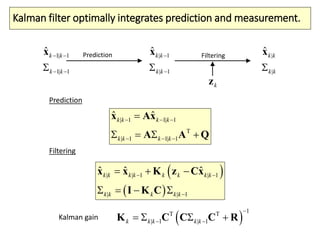
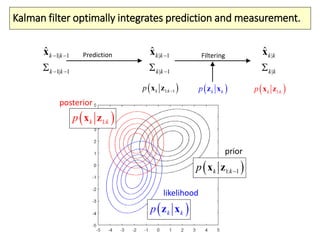
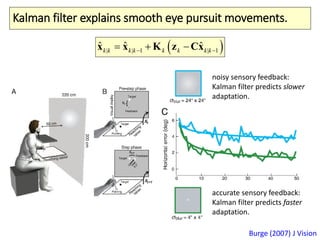
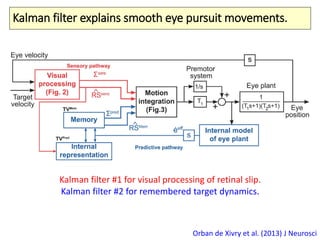
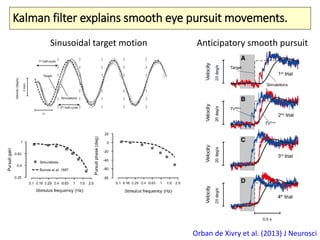
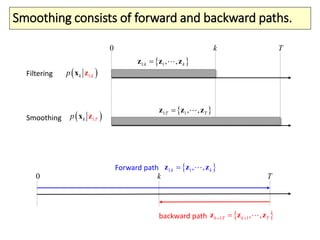
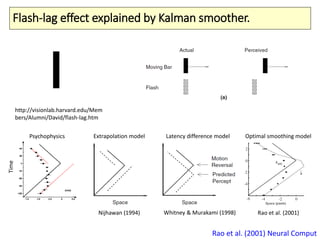
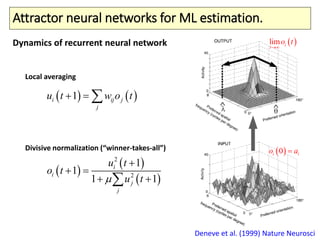
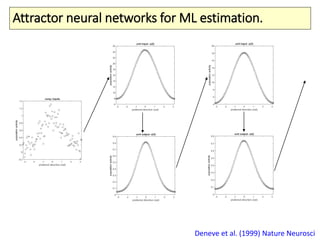
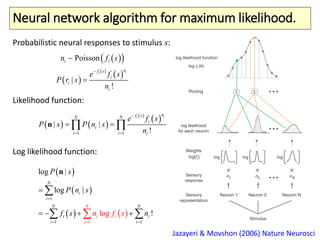
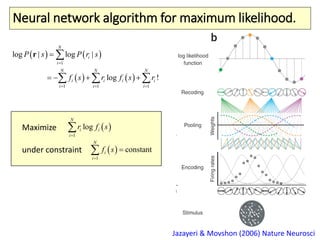
The document covers a summer school lecture on optimal estimation in noisy environments, focusing on techniques such as maximum-likelihood estimation, Bayesian estimation, and Kalman filtering. It discusses key concepts including the Cramer-Rao lower bound, causal inference, and the integration of sensory information from vision and haptics for width estimation. Additionally, the lecture addresses the application of these estimation methods in understanding perception and modeling dynamic systems.