Downloaded 142 times
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
マルチエージェント強化学習と心の理論
9/17 今井翔太 (松尾研究室)
えるエル@ImAI_Eruel](https://image.slidesharecdn.com/0917imai-211210044729/75/DL-1-2048.jpg)



![マルチエージェント深層強化学習
深層強化学習によって、あるタスクで高い性能を発揮する(報酬を最大化する)エー
ジェントの方策を獲得することが目標
環境内の複数エージェントが同時に強化学習を行なっている設定
特に、実機を用いた難しい協調タスクへの応用が期待され、現在は計算機上での比較的
難しいタスクをベンチマークとしてアルゴリズムの研究が進む
有名な手法
- MADDPG (Multi-Agent Deep Deterministic Policy Gradients)
- COMA (Counterfactual Multi-Agent Policy Gradients)
- VDN (Value-Decomposition Networks)
- QMIX
- AlphaStar
5
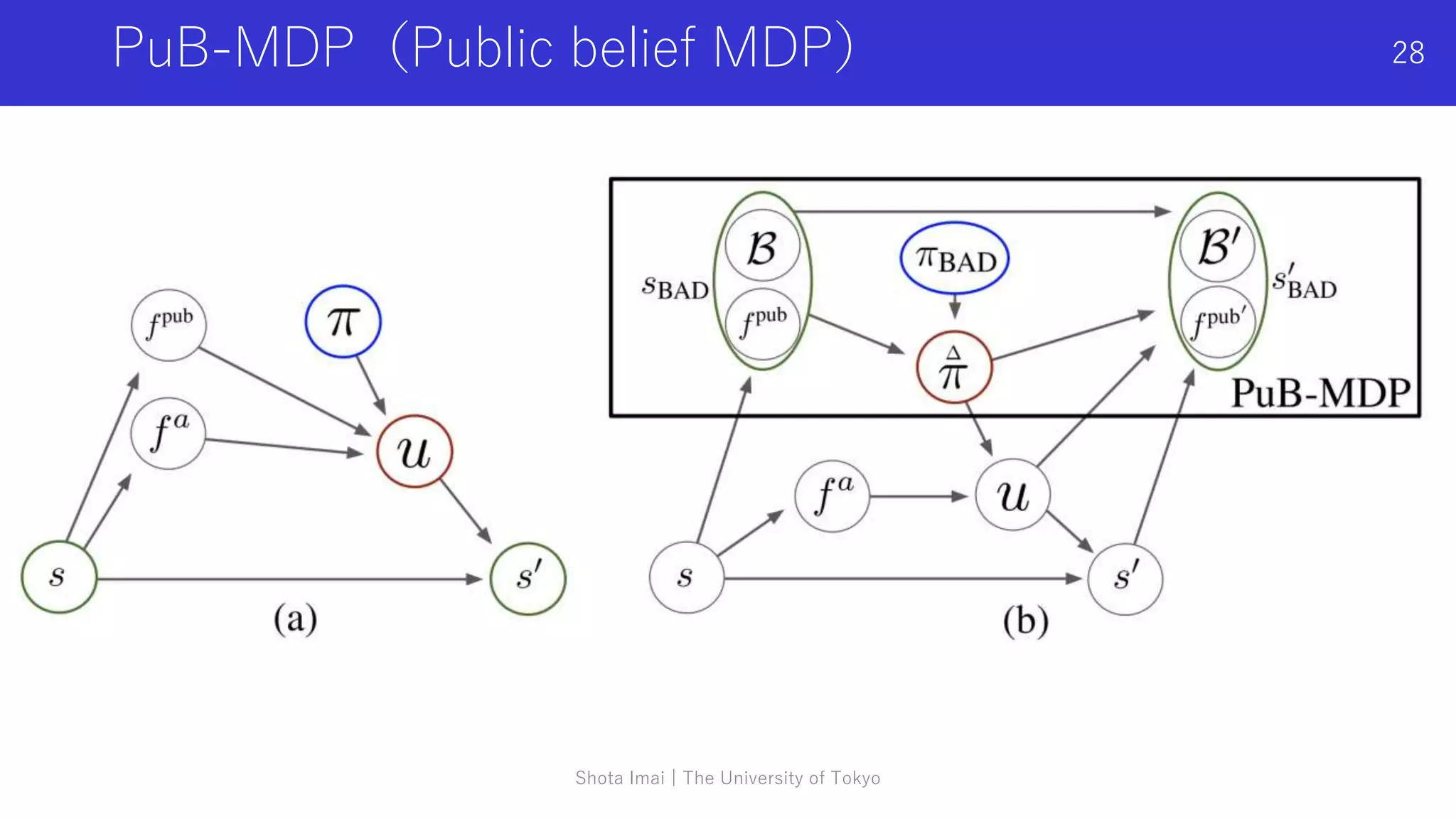
マルチエージェント深層強化学習に関する記号の定義
• 環境の状態:𝑠 ∈ 𝑆
• 行動:各エージェント𝑎 ∈ 𝐴 ≡ {1, … , 𝑛}の行動ua
∈ 𝑈
• 共同行動(joint action):𝒖 ∈ 𝑈 ≡ 𝑈𝑛
• 状態遷移関数:𝑃(𝑠′|𝑠, 𝑢): 𝑆 × 𝑈 × 𝑆 → [0,1]
• 部分観測関数:𝑂(𝑠, 𝑎): 𝑆 × 𝐴 → 𝑧
• 報酬関数:𝑟(𝑠, 𝑢): 𝑆 × 𝑈 → 𝑅](https://image.slidesharecdn.com/0917imai-211210044729/75/DL-5-2048.jpg)

![中央集権型学習分散型実行
CTDE; Centralized Learning Distributed Execution
現在のMARLの最重要概念(だが、今回の発表の本質ではない)
中央集権型学習:学習時のみ,勾配を計算する時に全体のエージェントの情報を含む環
境の「中央の状態」を使う
(e.g, 各エージェントの方策パラメータの勾配計算に部分観測に加え真の状態sを使う)
分散型実行:テスト時には,各エージェントは自身の部分観測のみを入力として方策を
実行
COMA[Foerster+ 2017]以降,特に用いられるアプローチで,
“in many cases, learning can take place in a simulator or a laboratory in which extra
state information is available and agents can communicate freely”[Foerster+ 2016]
つまり,「マルチエージェントの学習は,研究的な環境でシミュレータ等を使えるため,
学習を促進するために追加の状態の情報を使ってもよい」という仮定によるアプローチ
本来エージェントが動作するテスト環境(Execution時)は,基本的に各エージェントが
個別の観測だけを受け取って強調しているため,状態の追加情報は使えない
今回紹介する手法も学習時にはCTDEの設定で学習している前提で、一部の手法はCTDE
の仮定をフル活用している
Shota Imai | The University of Tokyo
7](https://image.slidesharecdn.com/0917imai-211210044729/75/DL-7-2048.jpg)

































![参考文献
Opponent modeling
- H. He, J. Boyd-Graber, K. Kwok, H.D. III, Opponent modeling in deep reinforcement learning, in: Proceedings of the International Conference on
Machine Learning (ICML), 2016.
- R. Raileanu, E. Denton, A. Szlam, R. Fergus, Modeling Others using Oneself in Multi-Agent Reinforcement Learning., in: International Conference on
Machine Learning, 2018. 12, 15, 22, 28
- Z.-W. Hong, S.-Y. Su, T.-Y. Shann, Y.-H. Chang, C.-Y. Lee, A Deep Policy Inference Q-Network for MultiAgent Systems, in: International Conference
on Autonomous Agents and Multiagent Systems, 2018. 12, 15, 22, 23, 27, 28 [169] M. Lanctot, V. F. Z
心の理論(心理学・行動科学)
- D. Premack, G. Woodruff, Does the chimpanzee have a theory of mind? Behav. Brain Sci. 1 (1978) 515–526
- C. Camerer, T. Ho, J. Chong, A cognitive hierarchy model of games, Q. J. Econ. 119 (3) (2004) 861–898.
- H. de Weerd, R. Verbrugge, B. Verheij, How much does it help to know what she knows you know? An agent-based simulation study, Artif. Intell. 199
(2013) 67–92.
- 川越敏司(2010):行動ゲーム理論入門, NTT出版
- 子安増生、郷式徹(2016):心の理論 第2世代の研究へ, 新曜社
- 西野成昭, 花木伸行(2021):マルチエージェントからの行動科学:実験経済学からのアプローチ, コロナ社
心の理論(機械学習)
- Bard, N., Foerster, J. N., Chandar, S., Burch, N., Lanctot, M., Song, H. F., Parisotto, E., Dumoulin, V., Moitra, S., Hughes, E., et al. The hanabi challenge:
A new frontier for ai research. Artificial Intelligence, 280:103216, 2020.
- Foerster, J., Song, F., Hughes, E., Burch, N., Dunning, I., Whiteson, S., Botvinick, M., and Bowling, M. Bayesian action decoder for deep multi-agent
reinforcement learning. In International Conference on Machine Learning, pp. 1942–1951. PMLR, 2019.
- Hu, H. and Foerster, J. N. Simplified action decoder for deep multi-agent reinforcement learning. In 8th International Conference on Learning
Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
- Hu, H., Peysakhovich, A., Lerer, A., and Foerster, J. “otherplay”for zero-shot coordination. In Proceedings of Machine Learning and Systems 2020, pp.
9396–9407. 2020.
- N. C. Rabinowitz, F. Perbet, H. F. Song, C. Zhang, S. M. A. Eslami, M. Botvinick, Machine Theory of Mind., in: International Conference on Machine
Learning, Stockholm, Sweden, 2018. 12, 15, 24, 28
Shota Imai | The University of Tokyo
42](https://image.slidesharecdn.com/0917imai-211210044729/75/DL-42-2048.jpg)

The document summarizes recent research related to "theory of mind" in multi-agent reinforcement learning. It discusses three papers that propose methods for agents to infer the intentions of other agents by applying concepts from theory of mind: 1. The papers propose that in multi-agent reinforcement learning, being able to understand the intentions of other agents could help with cooperation and increase success rates. 2. The methods aim to estimate the intentions of other agents by modeling their beliefs and private information, using ideas from theory of mind in cognitive science. This involves inferring information about other agents that is not directly observable. 3. Bayesian inference is often used to reason about the beliefs, goals and private information of other agents based

![[DL輪読会]AlphaStarとその関連技術](https://cdn.slidesharecdn.com/ss_thumbnails/dlalphastar-190605035416-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]マルチエージェント強化学習と⼼の理論 〜Hanabiゲームにおけるベイズ推論を⽤いたマルチエージェント 強化学習⼿法〜](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai1-210917021923-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)















































