[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
1.
http://deeplearning.jp/
Model soups: averagingweights of multiple fine-tuned models
improves accuracy without increasing inference time
小林 範久 Present Square Co.,Ltd.
DEEP LEARNING JP
[DL Papers]
1
2.
Copyright (C) PresentSquare Co., Ltd. All Rights Reserved.
書誌情報
Model soups: averaging weights of multiple fine-tuned models improves accuracy
without increasing inference time
https://arxiv.org/abs/2203.05482
タイトル:
著者: Mitchell Wortsmany, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs,
Raphael Gontijo-Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi,
Yair Carmon, Simon Kornblith, Ludwig Schmidt
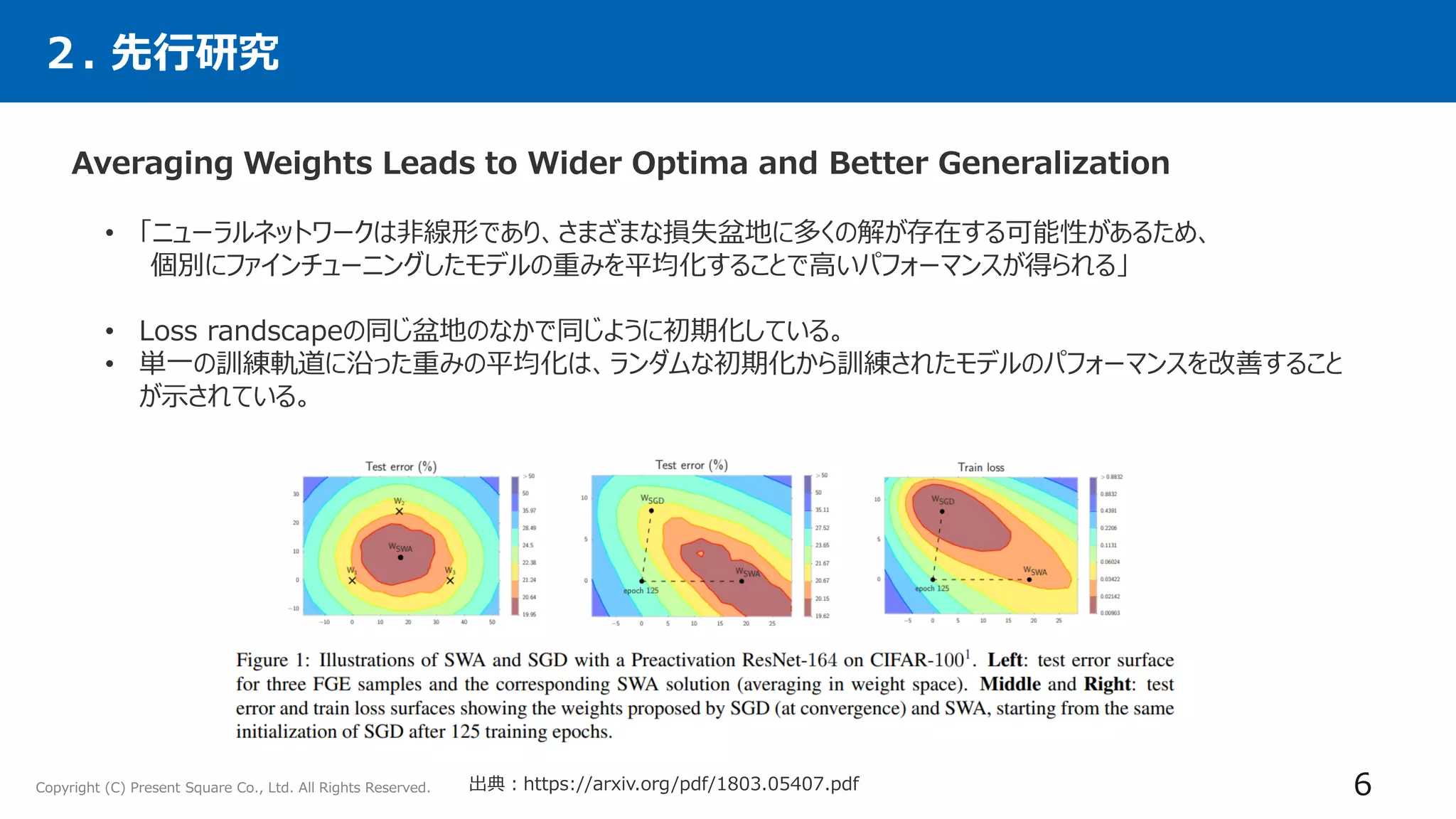
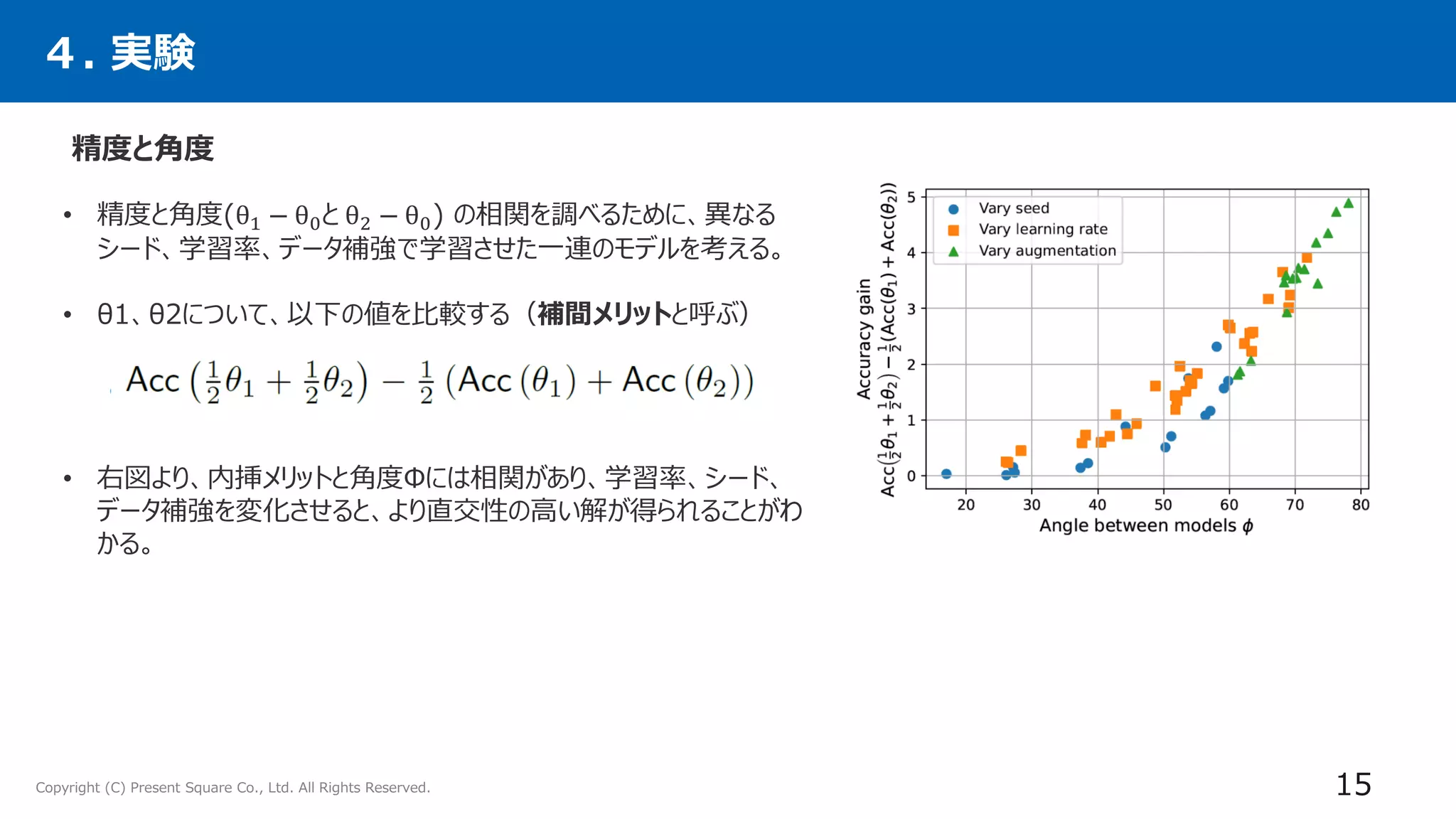
• 異なるハイパーパラメータの構成で学習した複数のファインチューニングモデルの「重み」を平均化すること
で、「精度」と「ロバスト性」が向上させる手法「Model soups」を提案。
• 従来のアンサンブルとは異なり、推論コストやメモリコストをかけることなく、多くのモデルを平均化することが
できる。
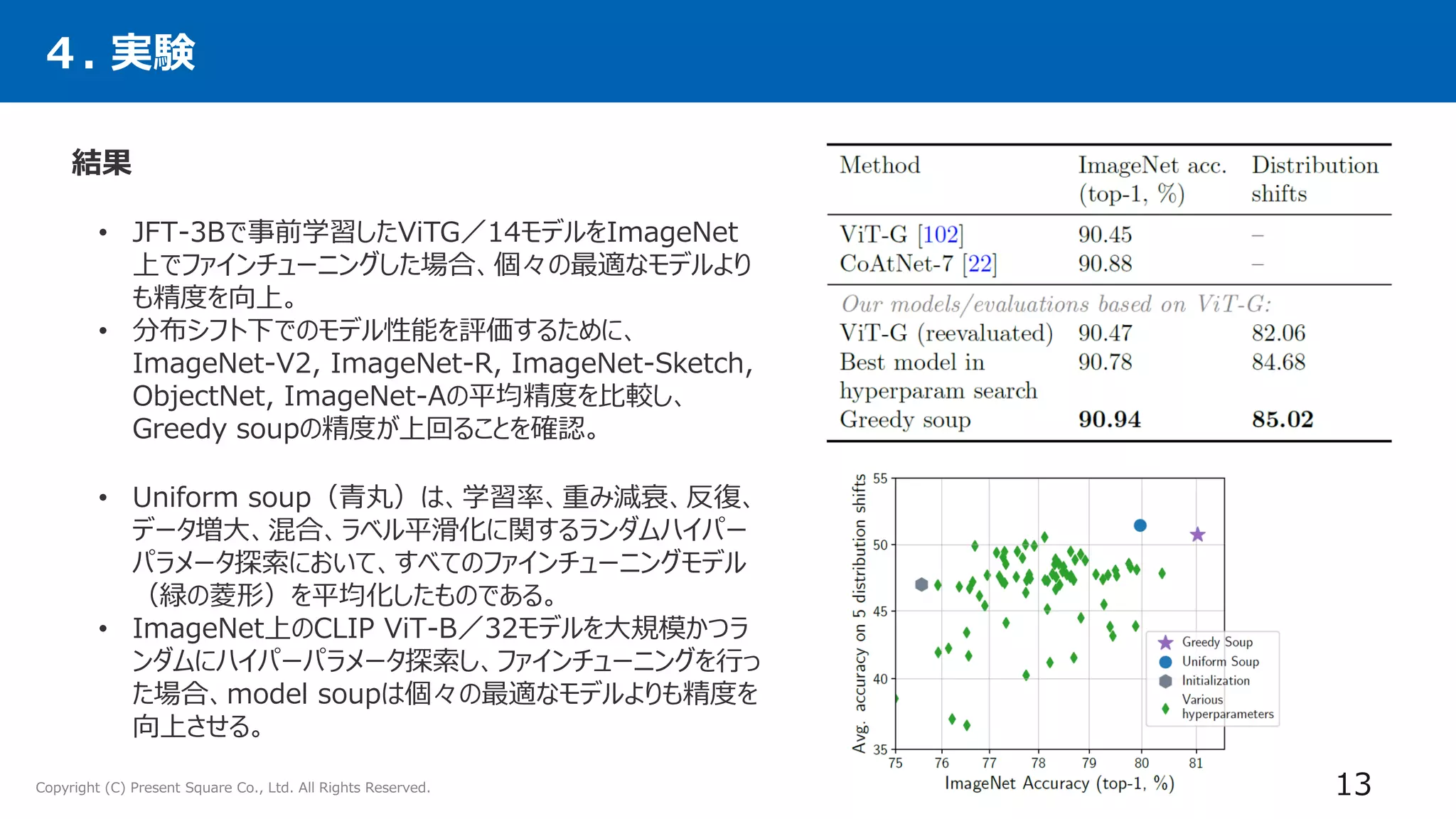
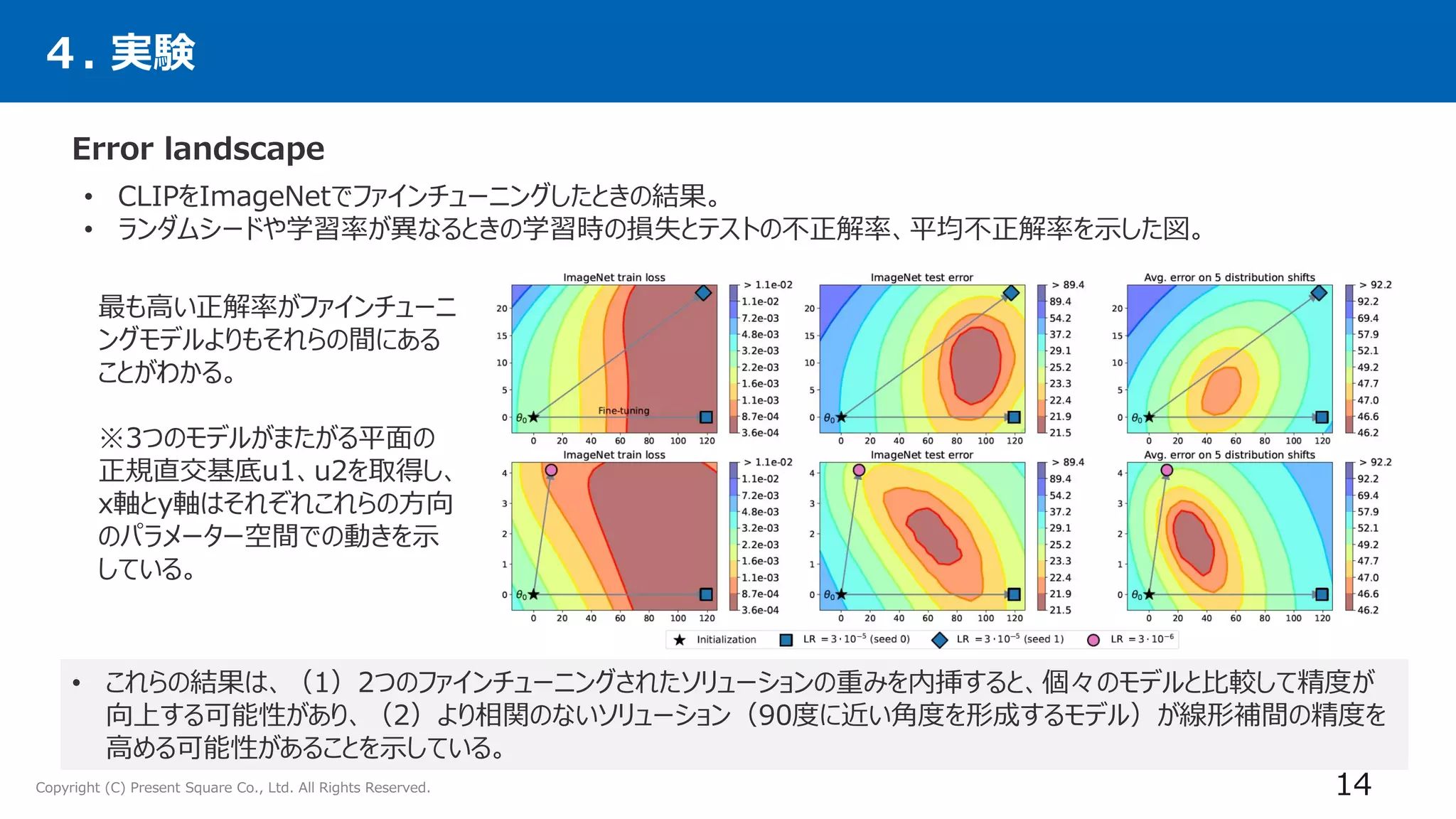
• CLIP、ALIGN、JFTで事前学習したViT-Gを利用することで、ImageNetで最良のモデルよりも大幅
に改善し、90.94%のトップ1精度を達成。
• さらにこのアプローチが、複数の画像分類や自然言語処理タスクに拡張され、分布外性能を向上させ、
新しい下流タスクのゼロショット性能を向上させることを示す。
概要:
2
3.
Copyright (C) PresentSquare Co., Ltd. All Rights Reserved.
アジェンダ
1. 導入
2. 先行研究
3. 手法
4. 実験
5. まとめ
3
Copyright (C) PresentSquare Co., Ltd. All Rights Reserved.
Appendix
参考文献
• [32] Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. Linear mode connectivity and the
lottery ticket hypothesis. In International Conference on Machine Learning (ICML), 2020.
https://arxiv.org/abs/1912.05671.
• [46] Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights
leads to wider optima and better generalization. In Conference on Uncertainty in Articial Intelligence(UAI), 2018.
https://arxiv.org/abs/1803.05407.
• [47] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V Le, Yunhsuan Sung, Zhen Li, and
Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International
Conference on Machine Learning (ICML), 2021. https://arxiv.org/abs/2102.05918.
• [72] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda
Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from
natural language supervision. In International Conference on Machine Learning (ICML), 2021.
https://arxiv.org/abs/2103.00020.
• [102] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers, 2021.
https://arxiv.org/abs/2106.04560.
27
![http://deeplearning.jp/
Model soups: averaging weights of multiple fine-tuned models
improves accuracy without increasing inference time
小林 範久 Present Square Co.,Ltd.
DEEP LEARNING JP
[DL Papers]
1](https://image.slidesharecdn.com/dl0401-220405031053/75/DL-Model-soups-averaging-weights-of-multiple-fine-tuned-models-improves-accuracy-without-increasing-inference-time-1-2048.jpg)











![Copyright (C) Present Square Co., Ltd. All Rights Reserved.
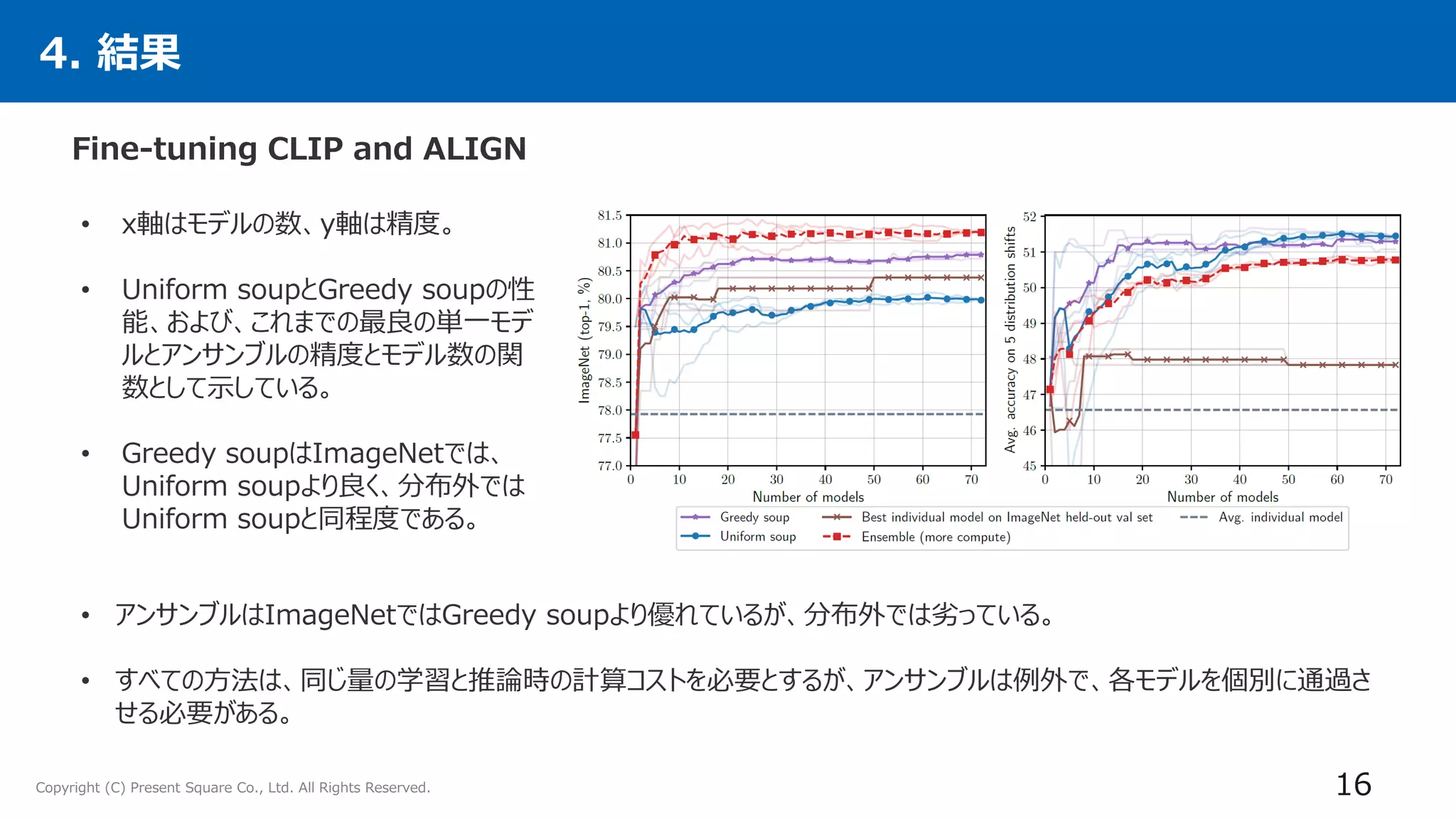
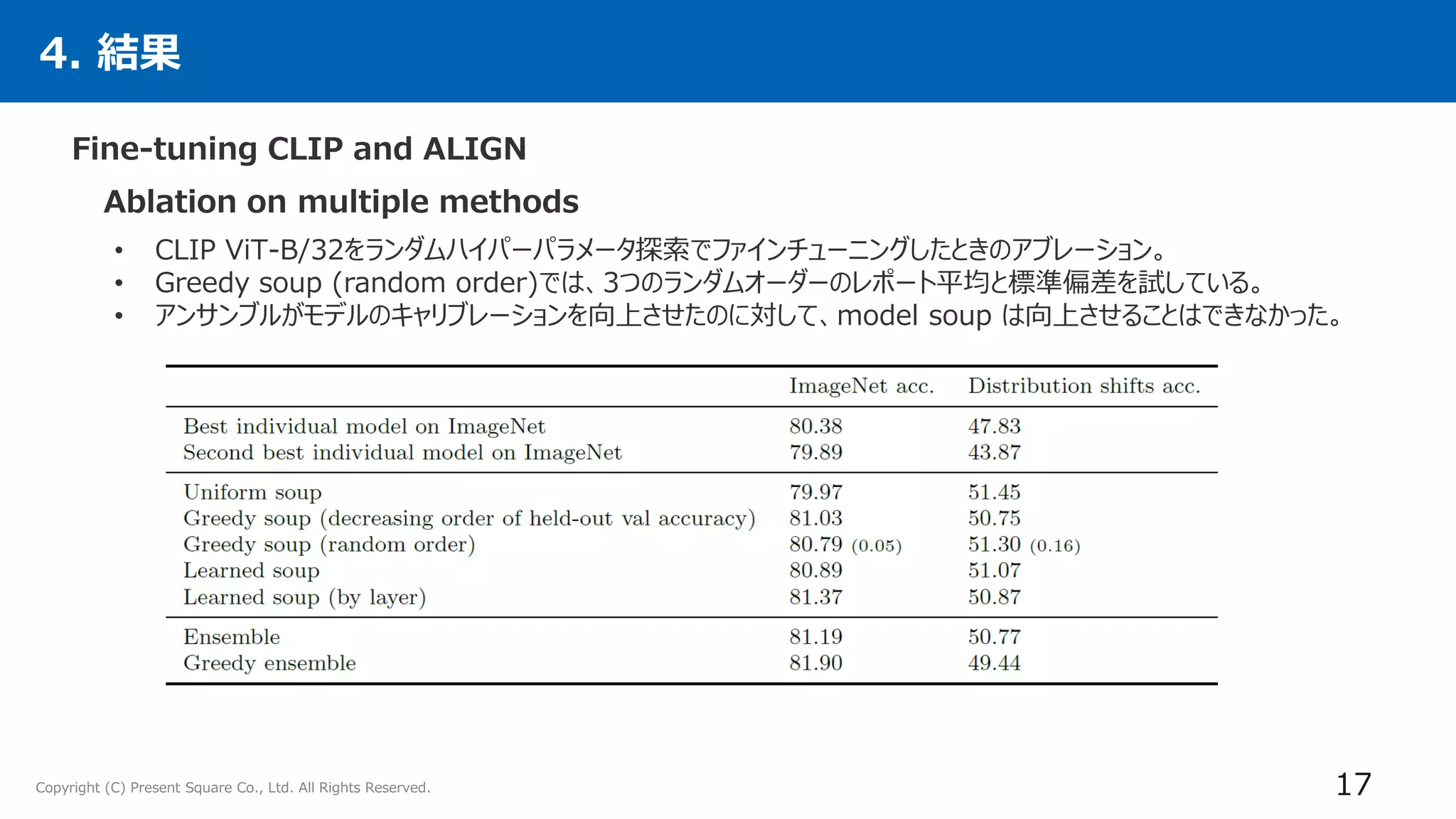
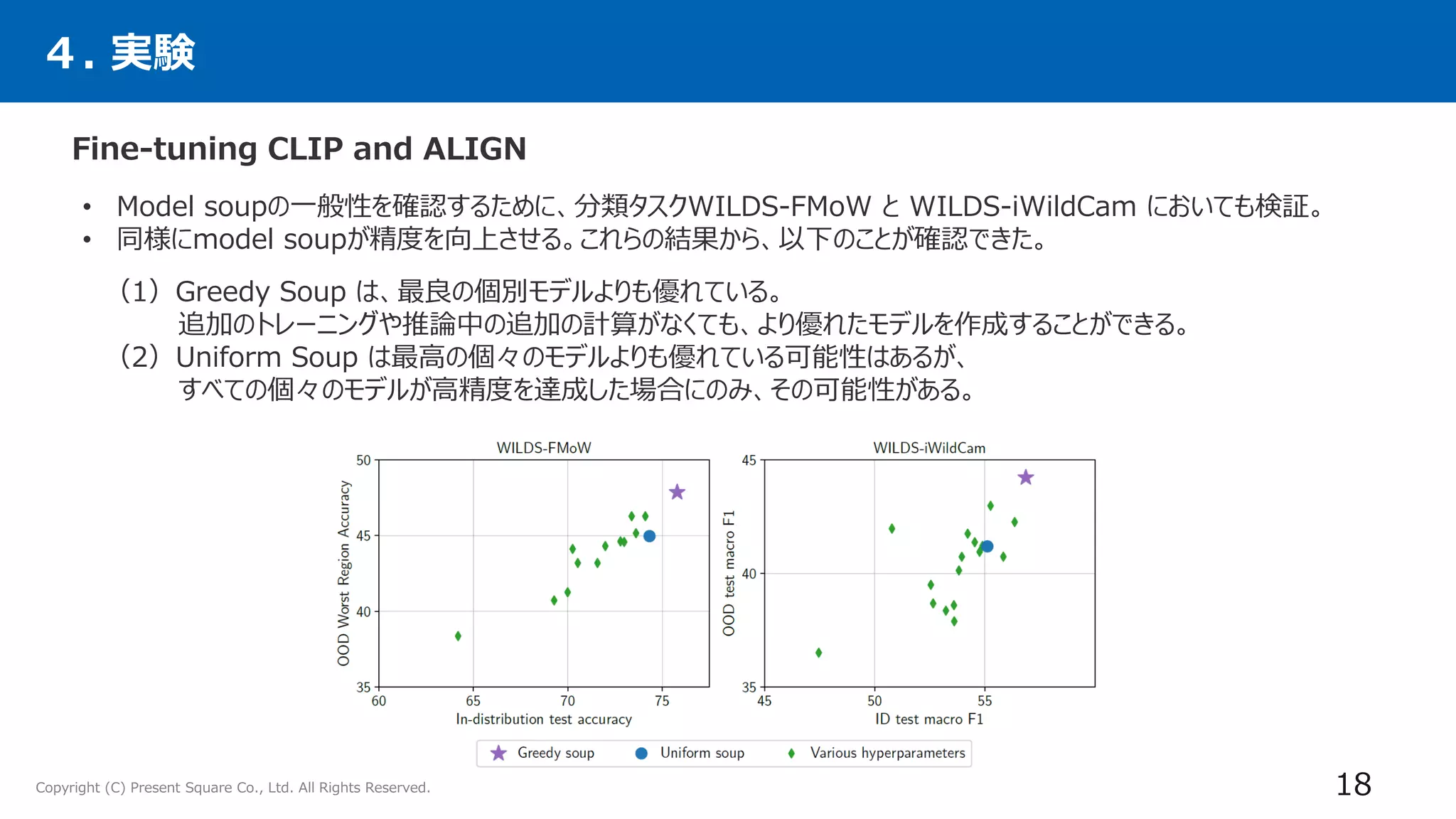
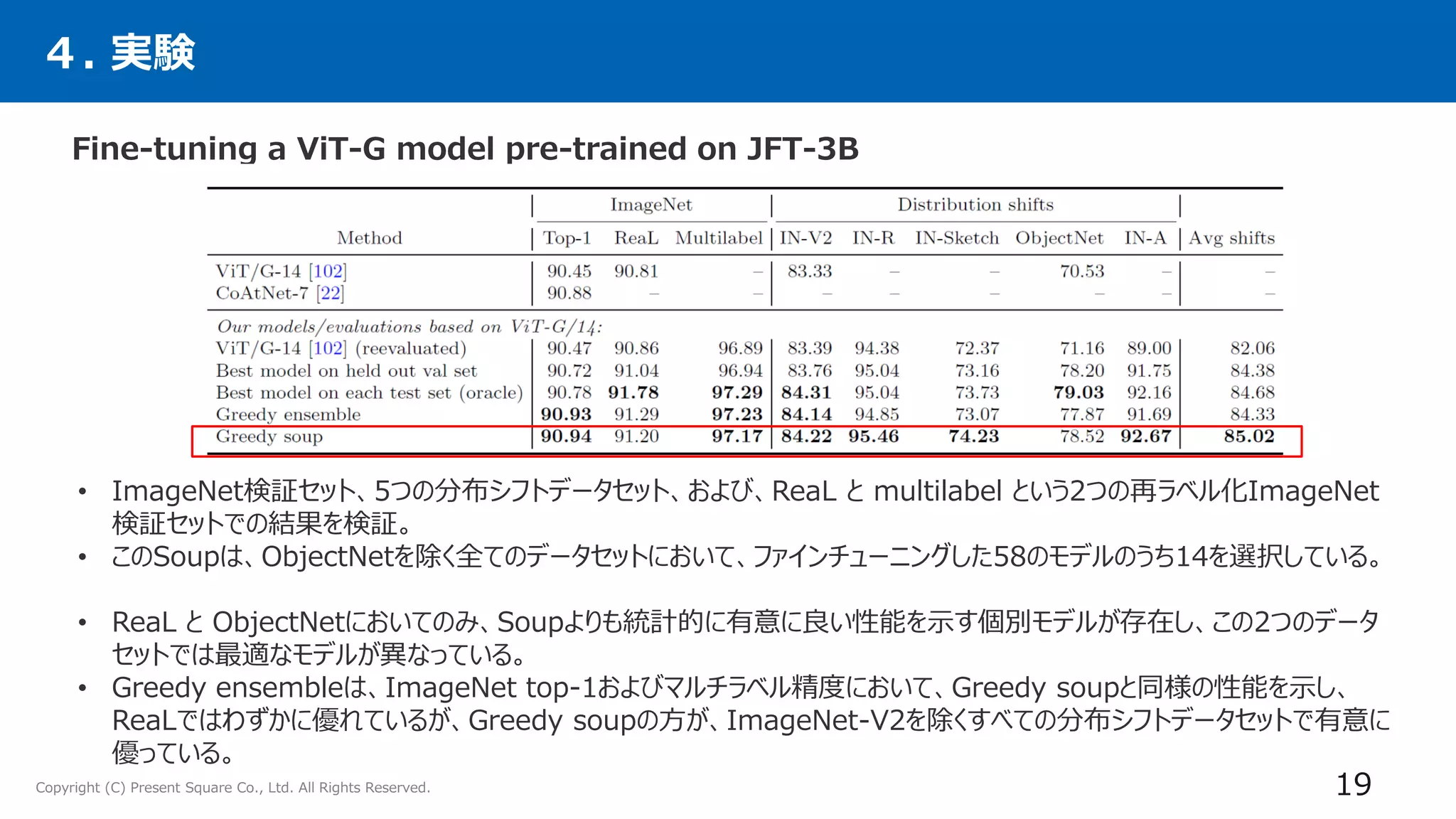
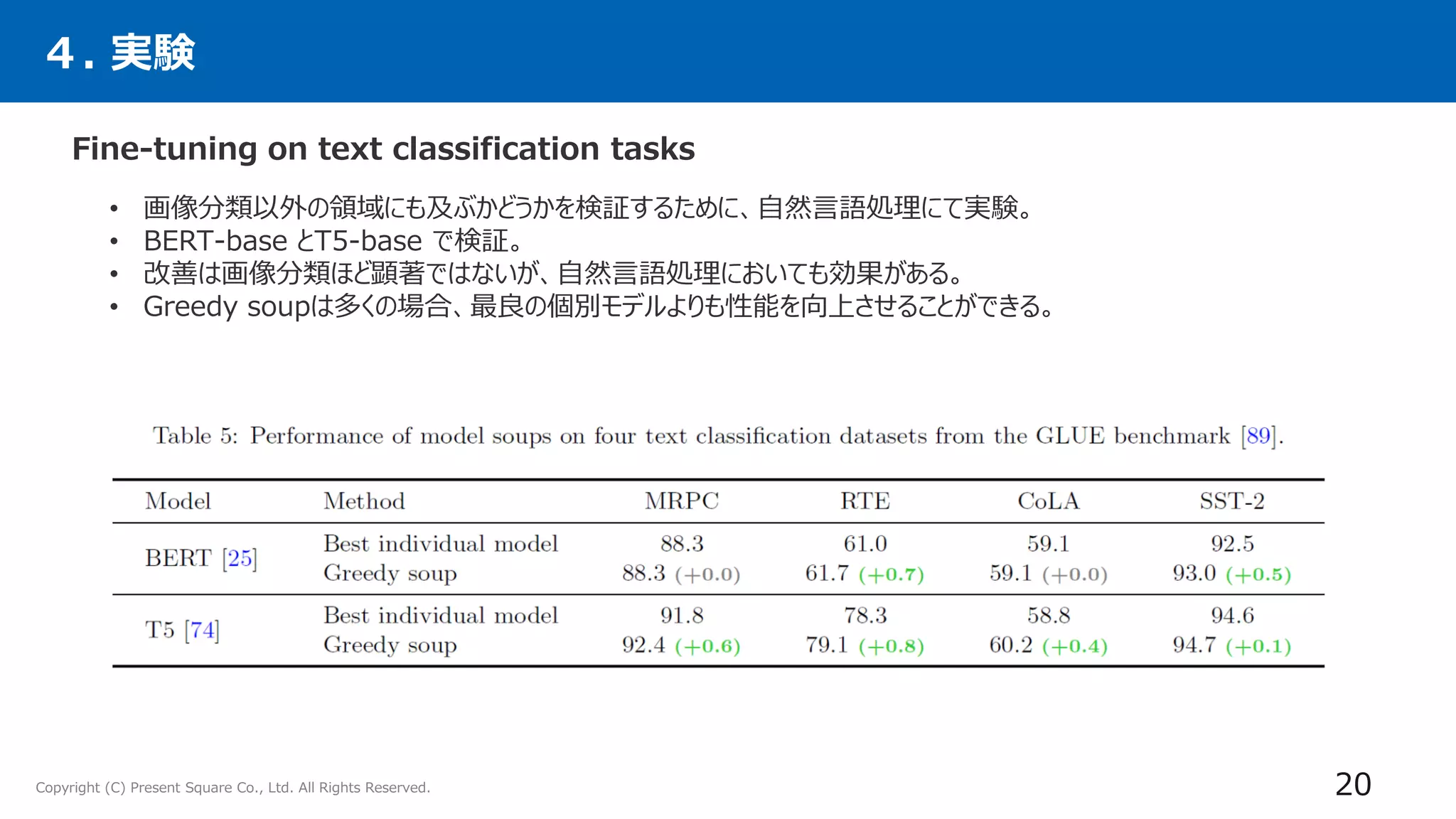
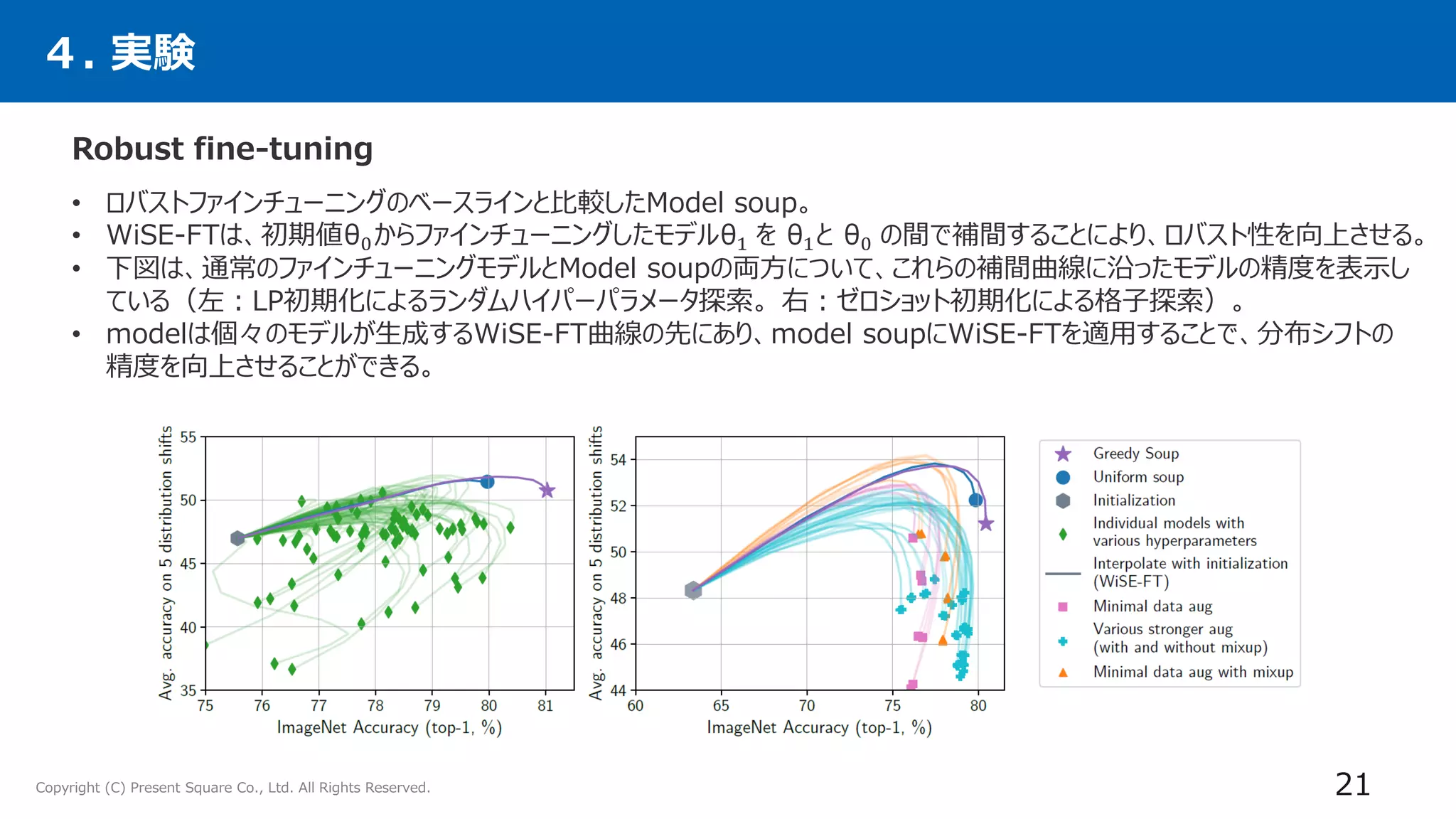
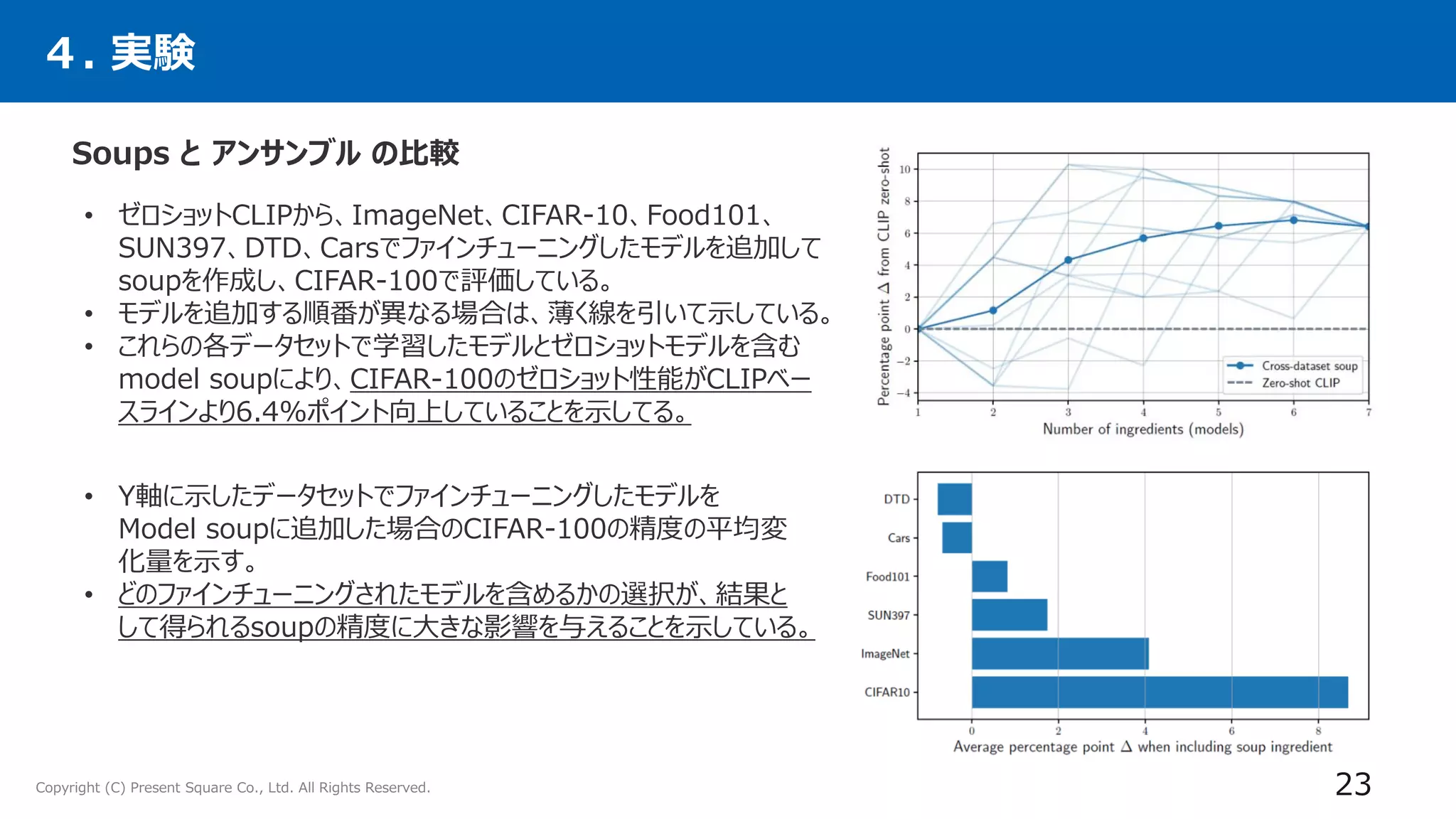
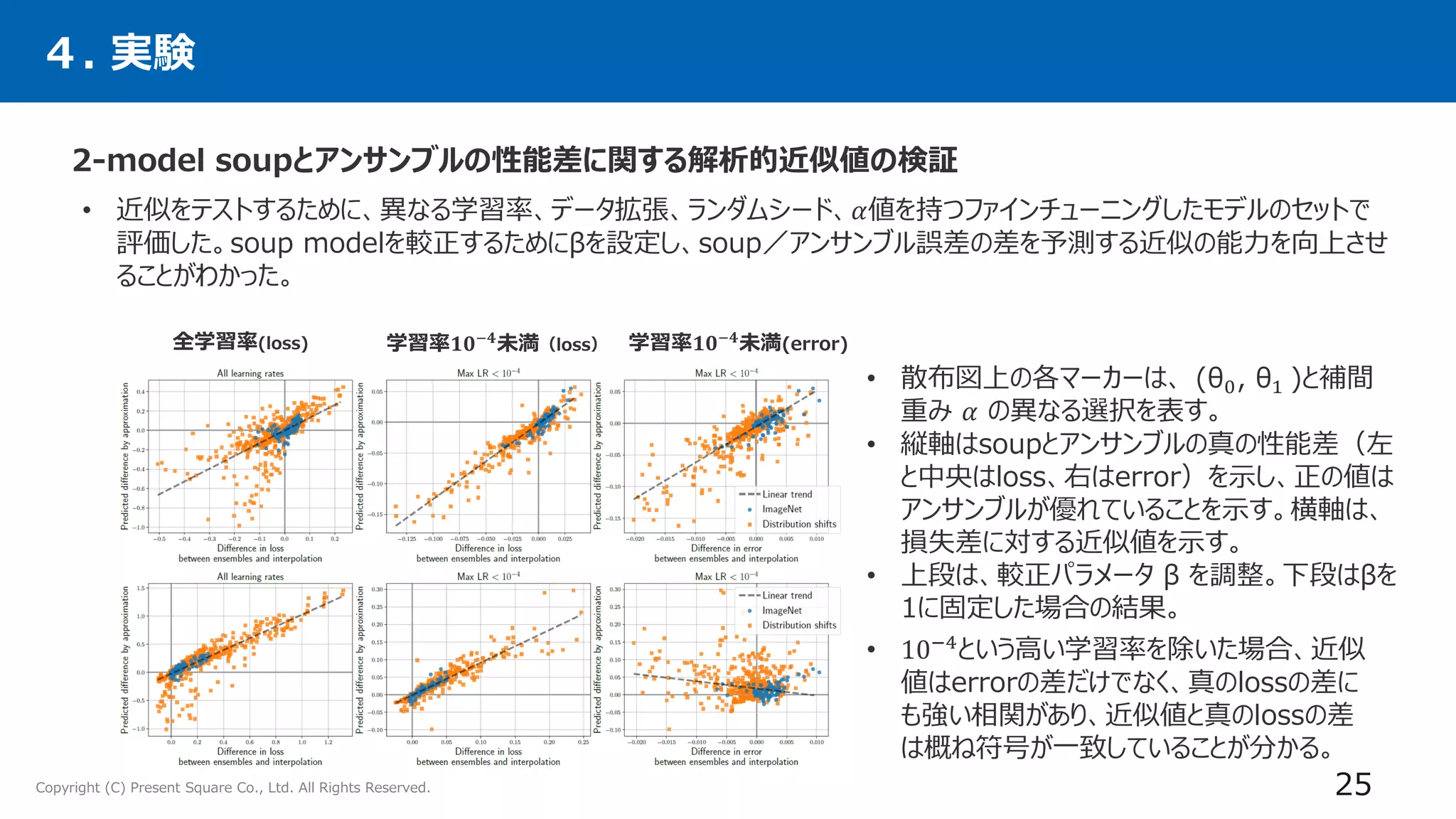
4. 実験
24
• パラメータθ0とθ1 の2つのモデルのみからなるスープを考える。
• 以上から、損失差の近似値を以下のように導出する。
θα = 1 − α θ0 + αθ1
𝑒𝑟𝑟α
𝑒𝑛𝑠
は、通常 min{𝑒𝑟𝑟0, 𝑒𝑟𝑟1} より小さい。
交差エントロピー誤差
重みパラメータ 𝛼 ∈ [0, 1] とすると
が、両エンドポイントである min{𝑒𝑟𝑟0, 𝑒𝑟𝑟1 }の最小値より低くなるのはいつなのか?
アンサンブルモデルの式
アンサンブルモデルの
2-model soupとアンサンブルの性能差に関する解析的近似値の検証](https://image.slidesharecdn.com/dl0401-220405031053/75/DL-Model-soups-averaging-weights-of-multiple-fine-tuned-models-improves-accuracy-without-increasing-inference-time-24-2048.jpg)

![Copyright (C) Present Square Co., Ltd. All Rights Reserved.
Appendix
参考文献
• [32] Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. Linear mode connectivity and the
lottery ticket hypothesis. In International Conference on Machine Learning (ICML), 2020.
https://arxiv.org/abs/1912.05671.
• [46] Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights
leads to wider optima and better generalization. In Conference on Uncertainty in Articial Intelligence(UAI), 2018.
https://arxiv.org/abs/1803.05407.
• [47] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V Le, Yunhsuan Sung, Zhen Li, and
Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International
Conference on Machine Learning (ICML), 2021. https://arxiv.org/abs/2102.05918.
• [72] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda
Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from
natural language supervision. In International Conference on Machine Learning (ICML), 2021.
https://arxiv.org/abs/2103.00020.
• [102] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers, 2021.
https://arxiv.org/abs/2106.04560.
27](https://image.slidesharecdn.com/dl0401-220405031053/75/DL-Model-soups-averaging-weights-of-multiple-fine-tuned-models-improves-accuracy-without-increasing-inference-time-27-2048.jpg)




![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)








































