This document provides mathematical formulas and explanations for many machine learning and statistical concepts. Some of the key concepts covered include:
- Naive Bayes classifier formulas for calculating posterior probability.
- Bayes optimal classifier and maximum a posteriori (MAP) estimation.
- Mixture models, mixtures of Gaussians, and the EM algorithm.
- Derivative rules including the product, chain and sum rules.
- Statistical concepts such as variance, standard deviation, covariance, and confidence intervals.
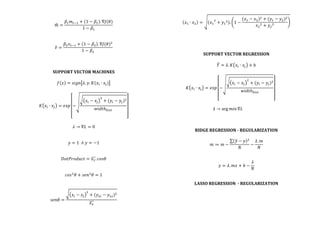
- Linear and logistic regression formulas.
- Decision trees and information gain.
The document serves as a reference sheet, concisely defining many foundational techniques in just a few sentences each.





![K
NEAREST
NEIGHBOR
𝑓 𝑥 ←
𝑓(𝑥)
𝑘
𝐷𝐸 𝑥!, 𝑥! = 𝑥! − 𝑥!
!
+ (𝑦!" − 𝑦!")!
WEIGHTED
NEAREST
NEIGHBOR
𝑓 𝑥 =
𝑓(𝑥)
𝐷(𝑥! 𝑥!)!
. 𝐷(𝑥! 𝑥!)!
PRINCIPAL
COMPONENTS
ANALYSIS
𝑥′ = 𝑥 − 𝑥
𝐸𝑖𝑔𝑒𝑛𝑣𝑎𝑙𝑢𝑒 = 𝐴 − 𝜆𝐼
𝐸𝑖𝑔𝑒𝑛𝑣𝑒𝑐𝑡𝑜𝑟 = 𝐸𝑛𝑔𝑒𝑛𝑣𝑎𝑙𝑢𝑒. [𝐴]
𝑓 𝑥 = 𝐸𝑖𝑔𝑒𝑛𝑣𝑒𝑐𝑡𝑜𝑟!
. [𝑥!!. . . 𝑥!"]
LINEAR
REGRESSION
𝑚! =
𝑥!
!
𝑥! 𝑦 − 𝑥! 𝑥! 𝑥! 𝑦
𝑥!
!
𝑥!
!
− ( 𝑥! 𝑥!)!
𝑏 = 𝑦 − 𝑚! 𝑥! − 𝑚! 𝑥!
𝑓 𝑥 = 𝑚! 𝑥!
!
!!!
+ 𝑏
LOGISTIC
REGRESSION
𝑂𝑑𝑑𝑠 𝑅𝑎𝑡𝑖𝑜 = 𝑙𝑜𝑔
𝑃
1 − 𝑃
= 𝑚𝑥 + 𝑏
𝑃
1 − 𝑃
= 𝑒!"!!
𝐽 𝜃 = −
𝑦. log (𝑦) + 1 − 𝑦 . log (1 − 𝑦)
𝑛
𝑤ℎ𝑒𝑟𝑒 𝑦 =
1
1 + 𝑒!"!!
𝑓𝑜𝑟 𝑦 = 0 ∧ 𝑦 = 1
−2𝐿𝐿 → 0](https://image.slidesharecdn.com/equations-200629131955/85/Some-Equations-for-MAchine-LEarning-5-320.jpg)
![𝑥 !~ 𝑥! ≠ 𝑥!′ ~ 𝑥!′
𝑚𝑥 + 𝑏 =
𝑝
1 − 𝑝
𝑃 𝑎 𝑐 =
𝑚𝑥 + 𝑏
𝑚𝑥 + 𝑏 + 1
𝐿𝑜𝑔𝑖𝑡 =
1
100. log (𝑃(𝑎|𝑐))
DECISION
TREES
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 = −𝑃. log (𝑃)
!
!!!
𝐼𝑛𝑓𝑜𝐺𝑎𝑖𝑛 = 𝑃!. −𝑃!!. log 𝑃!! − 𝑃!(!!!)−. log (𝑃!(!!!))
RULE
INDUCTION
𝐺𝑎𝑖𝑛 = 𝑃. [ −𝑃!!!. log (𝑃) − (−𝑃!. log (𝑃))]
RULE
VOTE
Weight=accuracy
.
coverage
ENTROPY
𝐻 𝐴 = − 𝑃 𝐴 . 𝑙𝑜𝑔𝑃(𝐴)
JOINT
ENTROPY
𝐻 𝐴, 𝐵 = − 𝑃 𝐴, 𝐵 . 𝑙𝑜𝑔𝑃(𝐴, 𝐵)
CONDITIONAL
ENTROPY
𝐻 𝐴|𝐵 = − 𝑃 𝐴, 𝐵 . 𝑙𝑜𝑔𝑃(𝐴|𝐵)
MUTUAL
INFORMATION
𝐼 𝐴, 𝐵 = 𝐻 𝐴 − 𝐻(𝐴|𝐵)
EIGENVECTOR
CENTRALITY
=
PAGE
RANK
𝑃𝑅 𝐴 =
1 − 𝑑
𝑛
− d
𝑃𝑅(𝐵)
𝑂𝑢𝑡(𝐵)
+
𝑃𝑅(𝑛)
𝑂𝑢𝑡(𝑛)
where
d=1
few
connections](https://image.slidesharecdn.com/equations-200629131955/85/Some-Equations-for-MAchine-LEarning-6-320.jpg)


![BACKPROPAGATION
𝛿! = 𝑜!. 1 − 𝑜! . (𝑡 − 𝑜!)
𝛿! = 𝑜!. 1 − 𝑜! . 𝑤!" 𝛿!
𝑤!" ← 𝑤!" + 𝜂!". 𝛿!. 𝑥!"
𝑤! = 1 + (𝑡 − 𝑜!)
∆𝑤!"(𝑛) = 𝜂. 𝛿!. 𝑥!" + 𝑀. ∆𝑤!"(𝑛 − 1)
where
M=momentum
NEURAL
NETWORKS
COST
FUNCTION
𝐽! =
𝑡!. log 𝑜 + 1 − 𝑡 . log (1 − 𝑜)!
!!!
!
!!!
𝑁
+
𝜆 𝜃!"
!!!!!
!!!
!!
!!!
!!
!!!
2𝑁
MOMENTUM
Υ
𝜃 = 𝜃 − (𝛾𝑣!!! + 𝜂. ∇𝐽 𝜃 )
NESTEROV
𝜃 = 𝜃 − (𝛾𝑣!!! + 𝜂. ∇𝐽(𝜃 − 𝛾𝑣!!!))
ADAGRAD
𝜃 = 𝜃 −
𝜂
𝑆𝑆𝐺!"#$ + 𝜖
. ∇𝐽(𝜃)
ADADELTA
𝜃 = 𝜃 −
𝑅𝑀𝑆[∆𝜃]!!!
𝑅𝑀𝑆∇𝐽(𝜃)
𝑅𝑀𝑆 Δ𝜃 = 𝐸 ∆𝜃! + 𝜖
RMSprop
𝜃 = 𝜃 −
𝜂
𝐸 𝑔! + 𝜖
. ∇𝐽(𝜃)
ADAM
𝜃 = 𝜃 −
𝜂
𝑣 + 𝜖
. 𝑚](https://image.slidesharecdn.com/equations-200629131955/85/Some-Equations-for-MAchine-LEarning-9-320.jpg)