Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
正志 坪坂
9,689 views
Deeplearning輪読会
BengioのDeep Learningの輪読会資料 http://www.deeplearningbook.org/ 10.7-10.14
Science
◦
Read more
8
Save
Share
Embed
Embed presentation
Download
Downloaded 21 times
1
/ 12
2
/ 12
3
/ 12
4
/ 12
5
/ 12
6
/ 12
7
/ 12
8
/ 12
9
/ 12
10
/ 12
11
/ 12
12
/ 12
More Related Content
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
Bayesian Neural Networks : Survey
by
tmtm otm
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
What's hot
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PDF
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PDF
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PDF
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
強化学習 DQNからPPOまで
by
harmonylab
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
Optimizer入門&最新動向
by
Motokawa Tetsuya
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
Similar to Deeplearning輪読会
PDF
Deep Learning
by
Masayoshi Kondo
PDF
Deeplearning勉強会20160220
by
正志 坪坂
PDF
dl-with-python01_handout
by
Shin Asakawa
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
20180110 AI&ロボット勉強会 Deeplearning4J と時系列データの異常検知について
by
Kazuki Motohashi
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
PDF
[DL輪読会]Training RNNs as Fast as CNNs
by
Deep Learning JP
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
Recurrent Neural Networks
by
Seiya Tokui
PPTX
深層学習による自然言語処理 第2章 ニューラルネットの基礎
by
Shion Honda
PDF
Learning to forget continual prediction with lstm
by
Fujimoto Keisuke
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
Rnncamp2handout
by
Shin Asakawa
PPTX
CVPR2017 参加報告 速報版 本会議 4日目
by
Atsushi Hashimoto
PPTX
Tf勉強会(5)
by
tak9029
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
[ML論文読み会資料] Training RNNs as Fast as CNNs
by
Hayahide Yamagishi
PDF
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PPTX
[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...
by
Deep Learning JP
Deep Learning
by
Masayoshi Kondo
Deeplearning勉強会20160220
by
正志 坪坂
dl-with-python01_handout
by
Shin Asakawa
Deep Learningの基礎と応用
by
Seiya Tokui
20180110 AI&ロボット勉強会 Deeplearning4J と時系列データの異常検知について
by
Kazuki Motohashi
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
[DL輪読会]Training RNNs as Fast as CNNs
by
Deep Learning JP
Deep Learningの技術と未来
by
Seiya Tokui
Recurrent Neural Networks
by
Seiya Tokui
深層学習による自然言語処理 第2章 ニューラルネットの基礎
by
Shion Honda
Learning to forget continual prediction with lstm
by
Fujimoto Keisuke
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
Rnncamp2handout
by
Shin Asakawa
CVPR2017 参加報告 速報版 本会議 4日目
by
Atsushi Hashimoto
Tf勉強会(5)
by
tak9029
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
[ML論文読み会資料] Training RNNs as Fast as CNNs
by
Hayahide Yamagishi
Deep Forest: Towards An Alternative to Deep Neural Networks
by
harmonylab
LSTM (Long short-term memory) 概要
by
Kenji Urai
[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...
by
Deep Learning JP
More from 正志 坪坂
PDF
Recsys2018 unbiased
by
正志 坪坂
PDF
WSDM2018Study
by
正志 坪坂
PDF
Recsys2016勉強会
by
正志 坪坂
PPTX
KDD 2016勉強会 Deep crossing
by
正志 坪坂
PDF
WSDM 2016勉強会 Geographic Segmentation via latent factor model
by
正志 坪坂
PDF
OnlineMatching勉強会第一回
by
正志 坪坂
PDF
Recsys2015
by
正志 坪坂
PDF
KDD 2015読み会
by
正志 坪坂
PDF
Recsys2014 recruit
by
正志 坪坂
PDF
EMNLP2014_reading
by
正志 坪坂
PDF
Tokyowebmining ctr-predict
by
正志 坪坂
PDF
KDD2014_study
by
正志 坪坂
PDF
Riak Search 2.0を使ったデータ集計
by
正志 坪坂
PDF
Contexual bandit @TokyoWebMining
by
正志 坪坂
PDF
Introduction to contexual bandit
by
正志 坪坂
PDF
確率モデルを使ったグラフクラスタリング
by
正志 坪坂
PDF
Big Data Bootstrap (ICML読み会)
by
正志 坪坂
PDF
Tokyowebmining2012
by
正志 坪坂
PDF
static index pruningについて
by
正志 坪坂
PDF
NIPS 2012 読む会
by
正志 坪坂
Recsys2018 unbiased
by
正志 坪坂
WSDM2018Study
by
正志 坪坂
Recsys2016勉強会
by
正志 坪坂
KDD 2016勉強会 Deep crossing
by
正志 坪坂
WSDM 2016勉強会 Geographic Segmentation via latent factor model
by
正志 坪坂
OnlineMatching勉強会第一回
by
正志 坪坂
Recsys2015
by
正志 坪坂
KDD 2015読み会
by
正志 坪坂
Recsys2014 recruit
by
正志 坪坂
EMNLP2014_reading
by
正志 坪坂
Tokyowebmining ctr-predict
by
正志 坪坂
KDD2014_study
by
正志 坪坂
Riak Search 2.0を使ったデータ集計
by
正志 坪坂
Contexual bandit @TokyoWebMining
by
正志 坪坂
Introduction to contexual bandit
by
正志 坪坂
確率モデルを使ったグラフクラスタリング
by
正志 坪坂
Big Data Bootstrap (ICML読み会)
by
正志 坪坂
Tokyowebmining2012
by
正志 坪坂
static index pruningについて
by
正志 坪坂
NIPS 2012 読む会
by
正志 坪坂
Deeplearning輪読会
1.
DeepLearning輪読会 10.7-10.14 リクルートテクノロジーズ 坪坂 正志
2.
本⽇の内容 • ⻑期のRNNにおける課題 • 10.7
The challenge of long-term dependencies • 課題を克服するための⼿法について • 10.8 Echo state networks • 10.10 Leaky Units • 10.9, 10.14 skip connection, multiple time scale • 10.12,10.13 second-order optimization, clipping gradients, regularizing to encourage information flow • 10.11 LSTM and other gated RNNs
3.
RNNの問題 • Recurrent networkは⼊⼒に対して同じ操作を繰り返していく ため共通の重みを何回かかけてくと⾮常に値が⼤きくなるか0 に近づくかのいずれかとなる •
例えば⼊⼒と⾮線形項を除いたRNNの隠れ層の式 ℎ(#) = 𝑤ℎ(#'() を考え ると初期の⼊⼒によらず0か発散のいずれかになることがわかる • 通常のdeep networkでは各レイヤーで異なる重みを使うためこ ういう問題は発⽣しない • これによりgradient-basedの学習⽅法を⽤いようとすると短期 の勾配の影響が⻑期の勾配に⽐べて⾮常に⼤きくうまく学習で きないという問題が発⽣する
4.
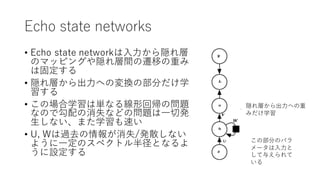
Echo state networks •
Echo state networkは⼊⼒から隠れ層 のマッピングや隠れ層間の遷移の重み は固定する • 隠れ層から出⼒への変換の部分だけ学 習する • この場合学習は単なる線形回帰の問題 なので勾配の消失などの問題は⼀切発 ⽣しない、また学習も速い • U, Wは過去の情報が消失/発散しない ように⼀定のスペクトル半径となるよ うに設定する この部分のパラ メータは⼊⼒と して与えられて いる 隠れ層から出⼒への重 みだけ学習
5.
Leaky units • unitの値の更新の際に自分の過去の値をそのまま利用するself- connectionを導入する •
式で書くと 𝜇(#) = 𝛼𝜇(#'() + (1 − 𝛼)𝑣(#) となる • Self-connectionについては最近画像のコンテストILSVRC 2015 で優勝したResNetでも使われているアイディア • http://research.microsoft.com/en- us/um/people/kahe/ilsvrc15/ilsvrc2015_deep_residual_learning_kai minghe.pdf
6.
Skip connection, Multiple
time scale • Skip Connection through time • 時刻tからt+1のコネクション以外にもtからt+dのようなジャンプして いるコネクションを追加する • Multiple time scale • Skip connectionではユニットは遠い過去の情報を⼊⼒として受け取る が⼀個前の情報にも依存している • Multiple time scaleの場合⼀個前ではなく2個,4個,8個と遠い距離の⼊ ⼒のみを受け取るユニットを⽤意してネットワークを構成する
7.
Second-order optimization • ⼀次の勾配が0に近づくタイミングで⼆次の勾配も同様に0に近 づくことがわかっている •
この場合second-order optimizationを使うと • 例えばニュートン法の更新が 𝑥 ← 𝑥 − => =>> であることから⽐率は変わら ないことからfirst-orderの⽅法と違ってvanishing gradient問題が回避 できる • しかし、second-order optimizationの計算量の課題からこの⽅ 法はあまり使われずSGD + LSTMが主流の⽅法となっている • これは機械学習でよくある最適化が簡単なモデルを構築する法 が最適化を⼯夫するよりも簡単だという話となっている
8.
Clipping gradients • 勾配が⼤きくならないようにgradientの値を計算した後に値が 閾値を超えていたら修正する •
修正の仕⽅は • Element wise : 要素ごとに閾値で抑える • Clip the norm : 勾配のノルムを計算して、ノルムが閾値以下になるよ うに修正 • Clip the normの⽅が勾配の⽅向が変わらないという利点があるが⼆者 の性能については実験的にはあまり⼤差がない
9.
Regularizing to encourage
information flow • Gradient clippingは勾配の発散には対処できるが消失には対応 できていない • ⼀つのアイディアとして時刻tにおける損失関数の勾配の影響が 過去にも残るような正則化項をいれるという⽅法があり、以下 の正則化項が提案されている
10.
Gated RNNs • Leaky
unitは過去の情報を蓄積するためのαという項を備えて いた • Gated RNNsではこの部分の過去の情報を蓄積するための項を 各ステップで変化させていく • またGated RNNsでは過去の情報を忘却するための機構も備え ている
11.
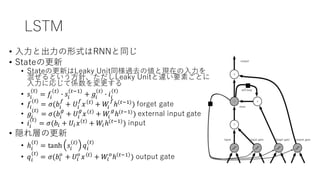
LSTM • ⼊⼒と出⼒の形式はRNNと同じ • Stateの更新 •
Stateの更新はLeaky Unit同様過去の値と現在の⼊⼒を 混ぜるという⽅針、ただしLeaky Unitと違い要素ごとに ⼊⼒に応じて係数を変更する • 𝑠@ (#) = 𝑓@ # B 𝑠@ #'( + 𝑔@ # B 𝑖@ (#) • 𝑓@ (#) = 𝜎(𝑏@ = + 𝑈@ = 𝑥 # + 𝑊@ = ℎ(#'() ) forget gate • 𝑔@ (#) = 𝜎(𝑏@ I + 𝑈@ I 𝑥 # + 𝑊@ I ℎ(#'() ) external input gate • 𝑖@ (#) = 𝜎(𝑏@ + 𝑈@ 𝑥 # + 𝑊@ℎ(#'() ) input • 隠れ層の更新 • ℎ@ (#) = tanh 𝑠@ # 𝑞@ (#) • 𝑞@ (#) = 𝜎(𝑏@ M + 𝑈@ M 𝑥 # + 𝑊@ M ℎ #'( ) output gate
12.
Other gated RNNs •
GRU • ℎ@ (#) = 𝑢@ (#) ℎ@ (#'() + (1 − 𝑢@ # )𝑖@ (#'() • 𝑢@ (#) = 𝜎(𝑏@ O + 𝑈@ O 𝑥 # + 𝑊@ O ℎ(#'() ) update gate • 𝑖@ (#) = 𝜎(𝑏@ + 𝑈@ 𝑥 # + 𝑊@(𝑟⨂ℎ #'( )) • 𝑟@ (#) = 𝜎(𝑏@ R + 𝑈@ R 𝑥 # + 𝑊@ R ℎ(#'() ) reset gate • Update gateとreset gateという⼆つの部分で元の隠れ層の値を 残すかどうかをコントロールしている • LSTMに⽐べgateが⼀つ減っている分学習するパラメータが少 なくなっている
Download















![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/20171002dlhacks-171002105129-thumbnail.jpg?width=640&height=640&fit=bounds)









![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...](https://cdn.slidesharecdn.com/ss_thumbnails/20190816-190816001737-thumbnail.jpg?width=640&height=640&fit=bounds)



















