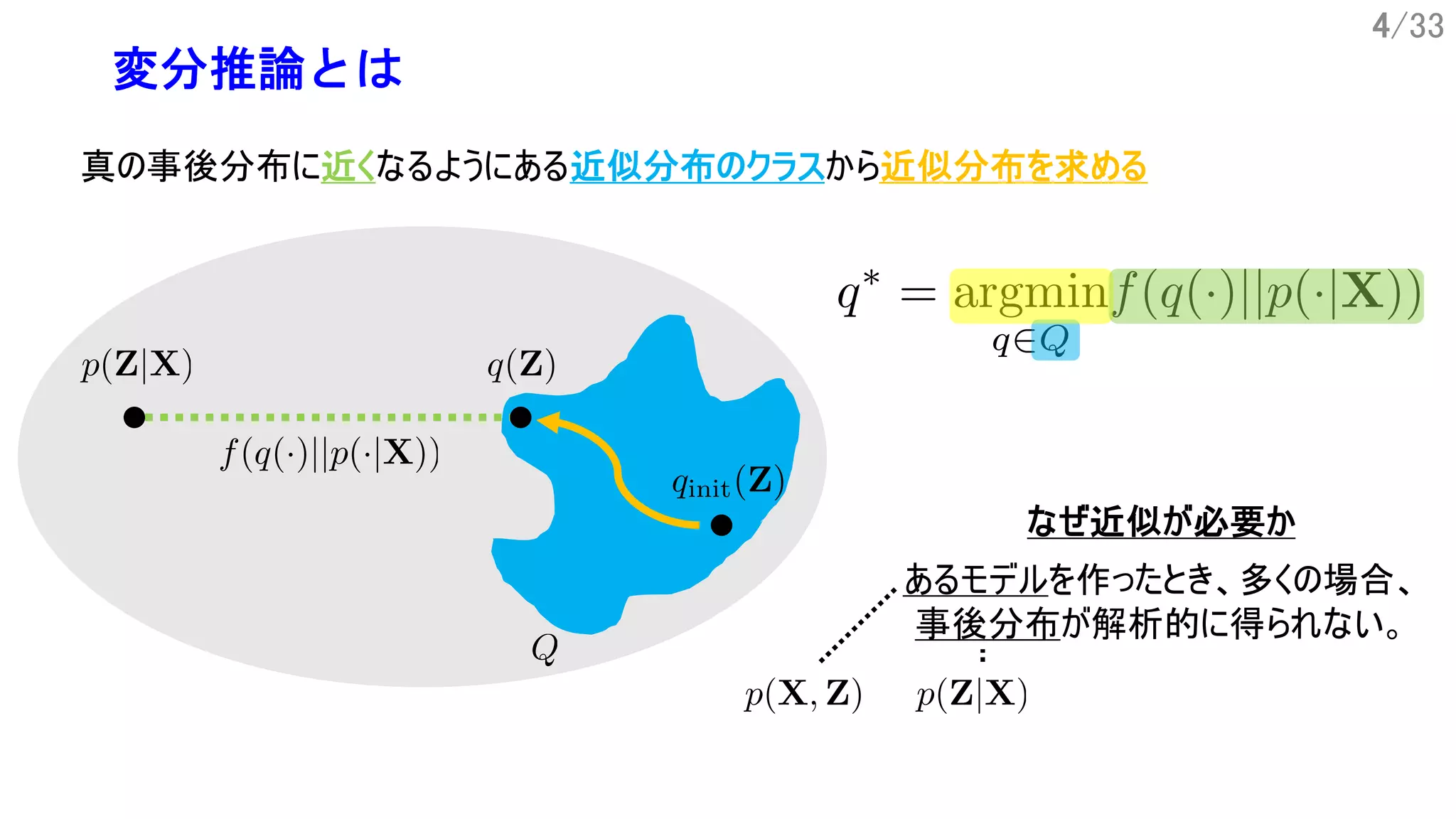
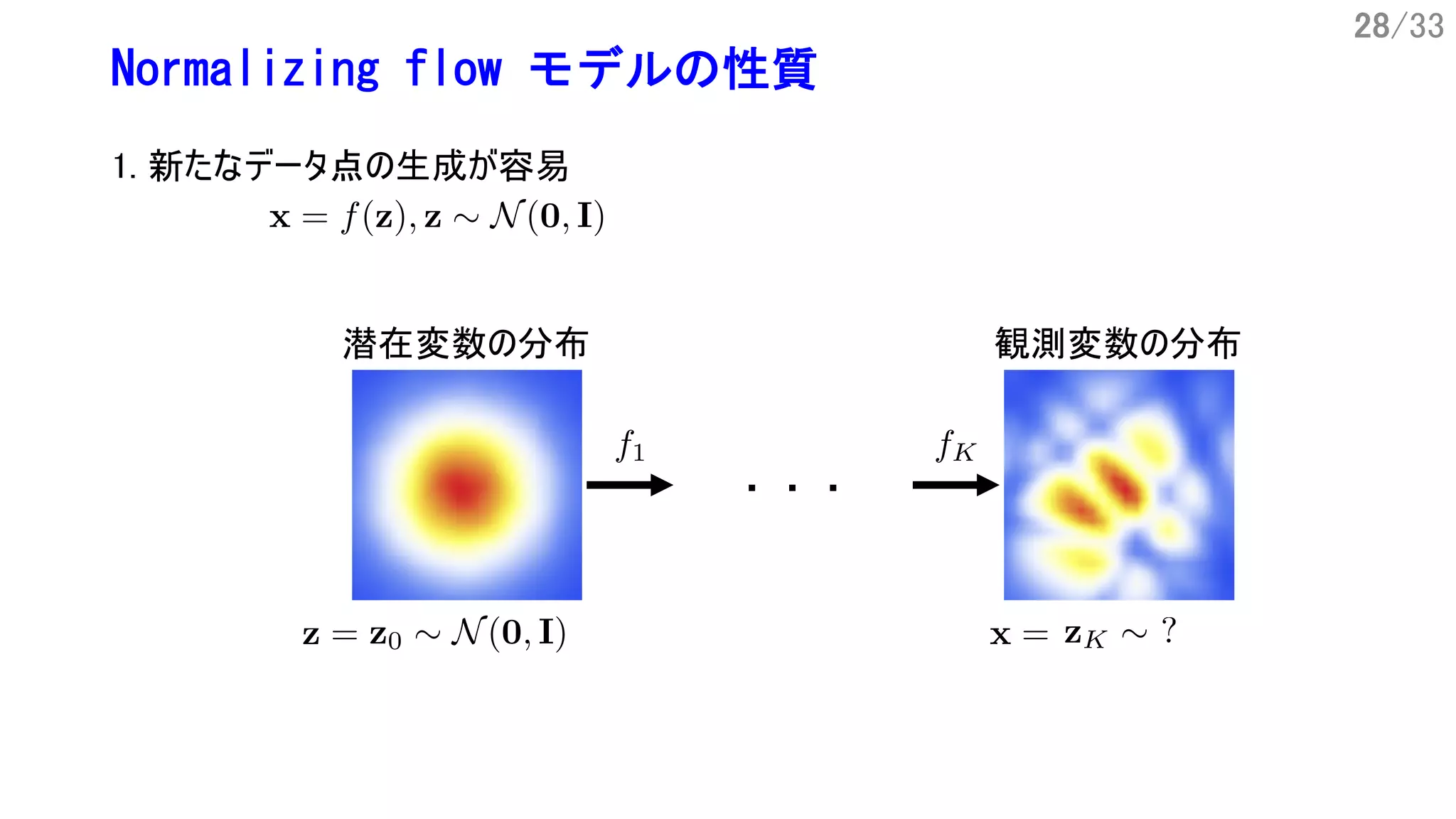
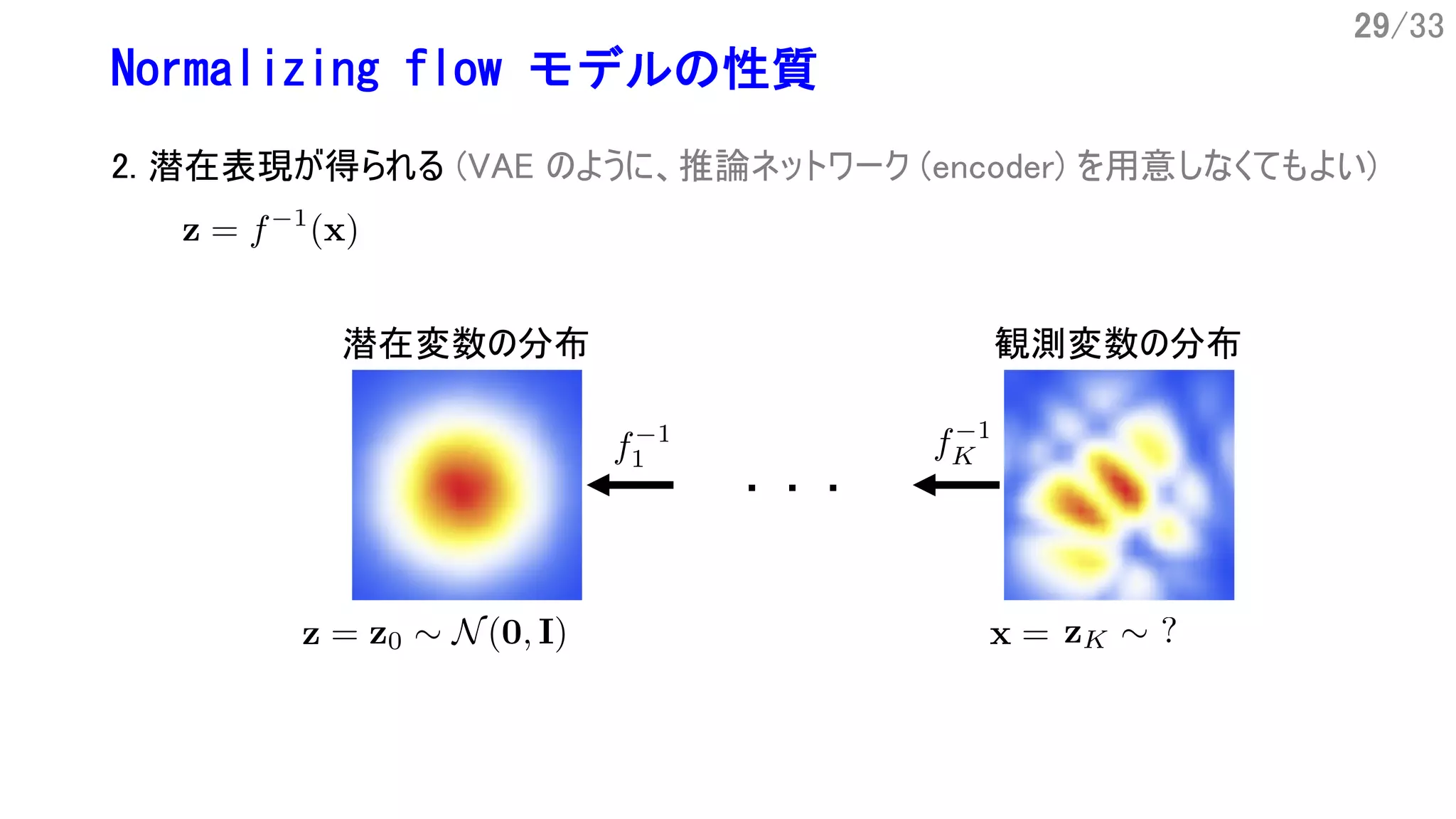
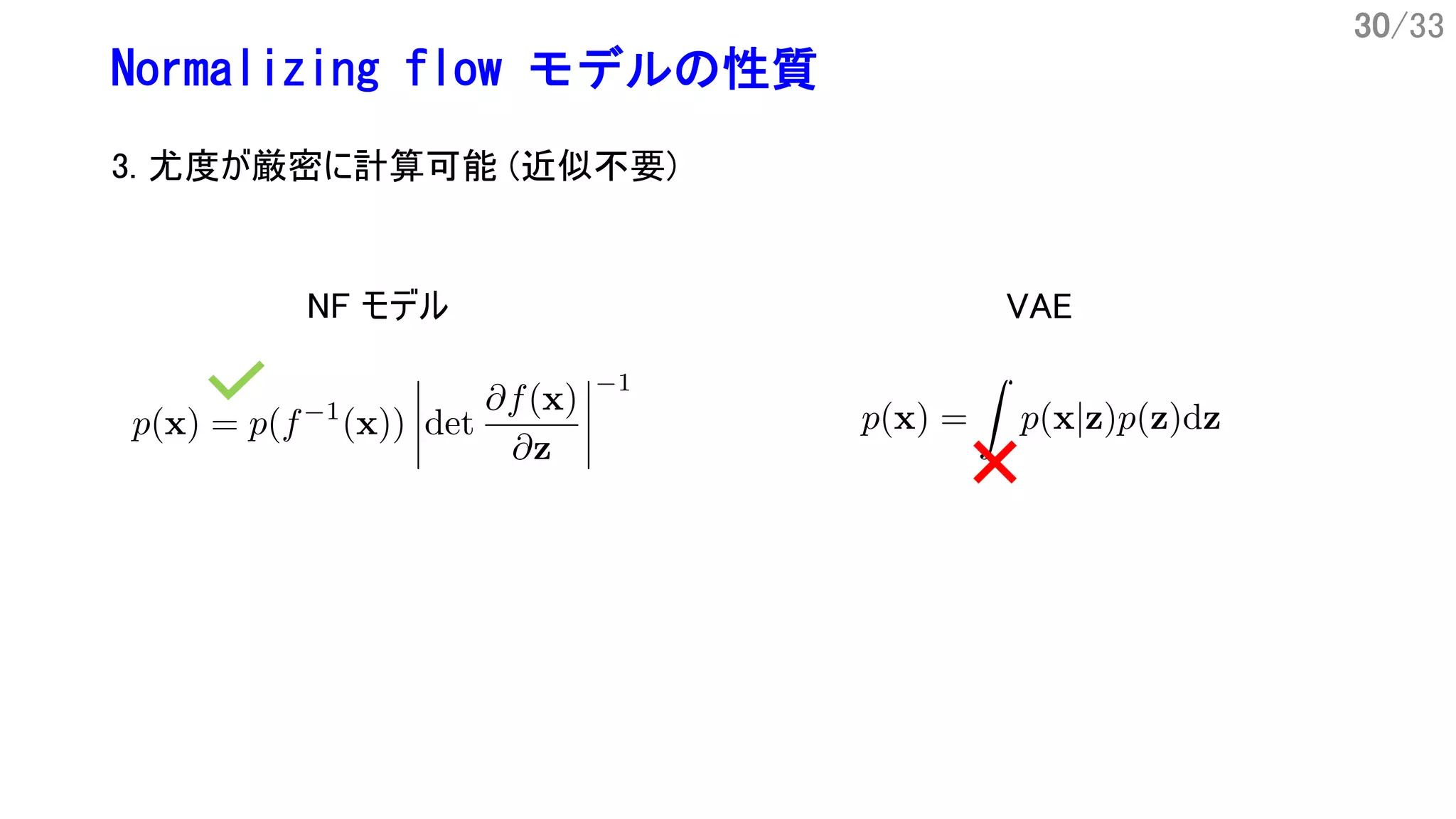
6/33
変分推論の課題 2. 近似分布の柔軟性/表現力
ØMean Field VI
Ø Amortized VI [Kingma+ ICLR14]
Ø VI with Normalizing Flows [Rezende+ ICML15]
分解仮定
パラメータ共有
真の事後分布を十分に近似できる柔軟性を持つのか
32/33
参考文献
• [Bishop 06]Bishop, C. M. (2006). Pattern recognition and machine learning. springer.
• [Dieng+ NIPS17] Dieng, A. B., Tran, D., Ranganath, R., Paisley, J., & Blei, D. (2017).
Variational Inference via χ Upper Bound Minimization. In Advances in Neural
Information Processing Systems (pp. 2732-2741).
• [Ermon+ 18] Ermon S. & Grover A. (2018). Normalizing flow models (CS236 course
notes). https://deepgenerativemodels.github.io/notes/flow/.
• [Grover+ AAAI18] Grover, A., Dhar, M., & Ermon, S. (2018, April). Flow-GAN:
Combining maximum likelihood and adversarial learning in generative models. In Thirty-
Second AAAI Conference on Artificial Intelligence.
• [Kingma+ ICLR14] Kingma, D. P., & Welling, M. (2014). Auto-encoding variational
Bayes. arXiv preprint arXiv:1312.6114.
• [Li+ NIPS16] Li, Y., & Turner, R. E. (2016). Rényi divergence variational inference. In
Advances in Neural Information Processing Systems (pp. 1073-1081).
• [Rezende+ ICML15] Rezende, D. J., & Mohamed, S. (2015). Variational inference with
normalizing flows. arXiv preprint arXiv:1505.05770.
• [Rumbos 08] Rumbos A. J. (2008). Probability lecture notes.
https://pages.pomona.edu/~ajr04747/Spring2008/Math151/Math151NotesSpring08.pd
f.
33.
33/33
その他資料
• おすすめ (変分ベイズ/深層生成モデルのチュートリアル)
•Variational Bayes and beyond: Bayesian inference for big data (ICML2018),
http://www.tamarabroderick.com/tutorial_2018_icml.html
• Variational Inference: Foundations and Innovations,
http://www.cs.columbia.edu/~blei/talks/Blei_VI_tutorial.pdf
• Tutorial on Deep Generative Models (IJCAI-ECAI 2018),
https://drive.google.com/file/d/1uwvXkKfrOjYsRKLO7RK4KbvpWmu_YPN_/view?usp=shari
ng
• Tutorial on Deep Generative Models (UAI 2017),
https://www.shakirm.com/slides/DeepGenModelsTutorial.pdf
• その他
• Normalizing Flows Tutorial, Part 1: Distributions and Determinants,
https://blog.evjang.com/2018/01/nf1.html
• Flow-based Deep Generative Models, https://lilianweng.github.io/lil-log/2018/10/13/flow-
based-deep-generative-models.html
• Variational Inference with Normalizing Flowsを読んだのでメモ,
http://peluigi.hatenablog.com/entry/2018/07/12/140528
• Up to GLOW, https://www.slideshare.net/ShunsukeNAKATSUKA1/up-to-glow
• DL輪読会 Flow-based Deep Generative Models,
https://www.slideshare.net/DeepLearningJP2016/dlflowbased-deep-generative-models




![5/33
変分推論の課題 1. 分布間の「距離」
Ø alpha-divergence [Li+ NIPS16]
Ø Kullbuck-Leibler divergence (多くの場合)
Ø Chi-divergence [Dieng+ NIPS17]
分布の近さが ”正しく” 測れているのか](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-5-2048.jpg)
![6/33
変分推論の課題 2. 近似分布の柔軟性/表現力
Ø Mean Field VI
Ø Amortized VI [Kingma+ ICLR14]
Ø VI with Normalizing Flows [Rezende+ ICML15]
分解仮定
パラメータ共有
真の事後分布を十分に近似できる柔軟性を持つのか](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-6-2048.jpg)
![7/33
変分推論の課題 3. 最適化
Ø Coordinate descent
[Bishop 06, Chap. 10]
Ø Stochastic VI [Hoffman+ 13]
Ø 勾配ベースの最適化法
(SGD, Adam, etc.)
(近似分布のクラスの中で)
良い近似が得られるのか](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-7-2048.jpg)

![9/33
Normalizing flow の概要
目的: 変分推論の近似分布のクラスを広くすること
アイデア: 単純な分布に従う確率変数を非線形変換を繰り返して、複雑な分布を表現
単純な分布 複雑な分布
[Rezende+ ICML15, Figure 1]
・ ・ ・](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-9-2048.jpg)
![10/33
Normalizing flow の概要
目的: 変分推論の近似分布のクラスを広くすること
アイデア: 単純な分布に従う確率変数を非線形変換を繰り返して、複雑な分布を表現
単純な分布 複雑な分布
[Rezende+ ICML15, Figure 1]
・ ・ ・
具体的にどんな分布になるのか =>
ポイント: 変換は可逆](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-10-2048.jpg)




![16/33
特徴
Ø O(D) でヤコビ行列の行列式が計算可
Ø h とパラメータの値によっては非可逆
Planar flow
ヤコビ行列の行列式の計算コストが低い、変数変換を採用したい。
変数変換
学習するパラメータ
ヤコビ行列の行列式
ただし、
ただし、 は非線形関数
詳細は [Rezende+ ICML15, A.1.]](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-16-2048.jpg)

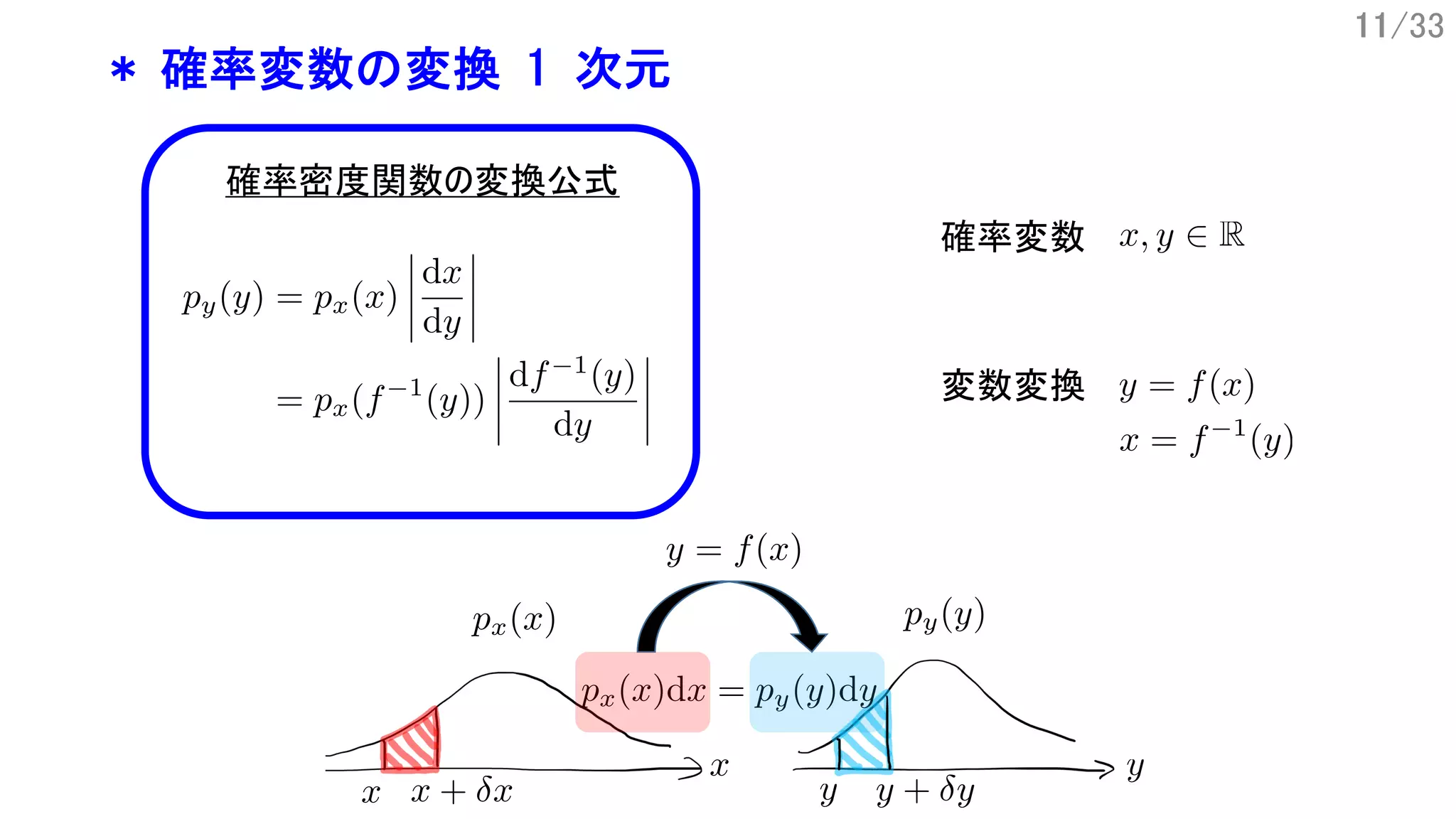
![18/33
* Law of the Unconscious Statistician (LOTUS)
変数変換後の分布を知らなくても、期待値が計算できる という性質、定理
証明は [Rumbos 08]
例](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-18-2048.jpg)
![19/33
Normalizing flow による分布近似 1/2
K=2 K=8 K=32真
1
2
3
4
変数変換の回数 (K) が増えると、
近似分布の表現力が上がる。
[Rezende+ ICML15, Figure 3 (a) (b)]](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-19-2048.jpg)
![20/33
Normalizing flow による分布近似 2/2
変数変換の回数 (K) が増えると、良い近似が得られている (KL が小さいという意味で)
[Rezende+ ICML15, Figure 3 (d)]](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-20-2048.jpg)
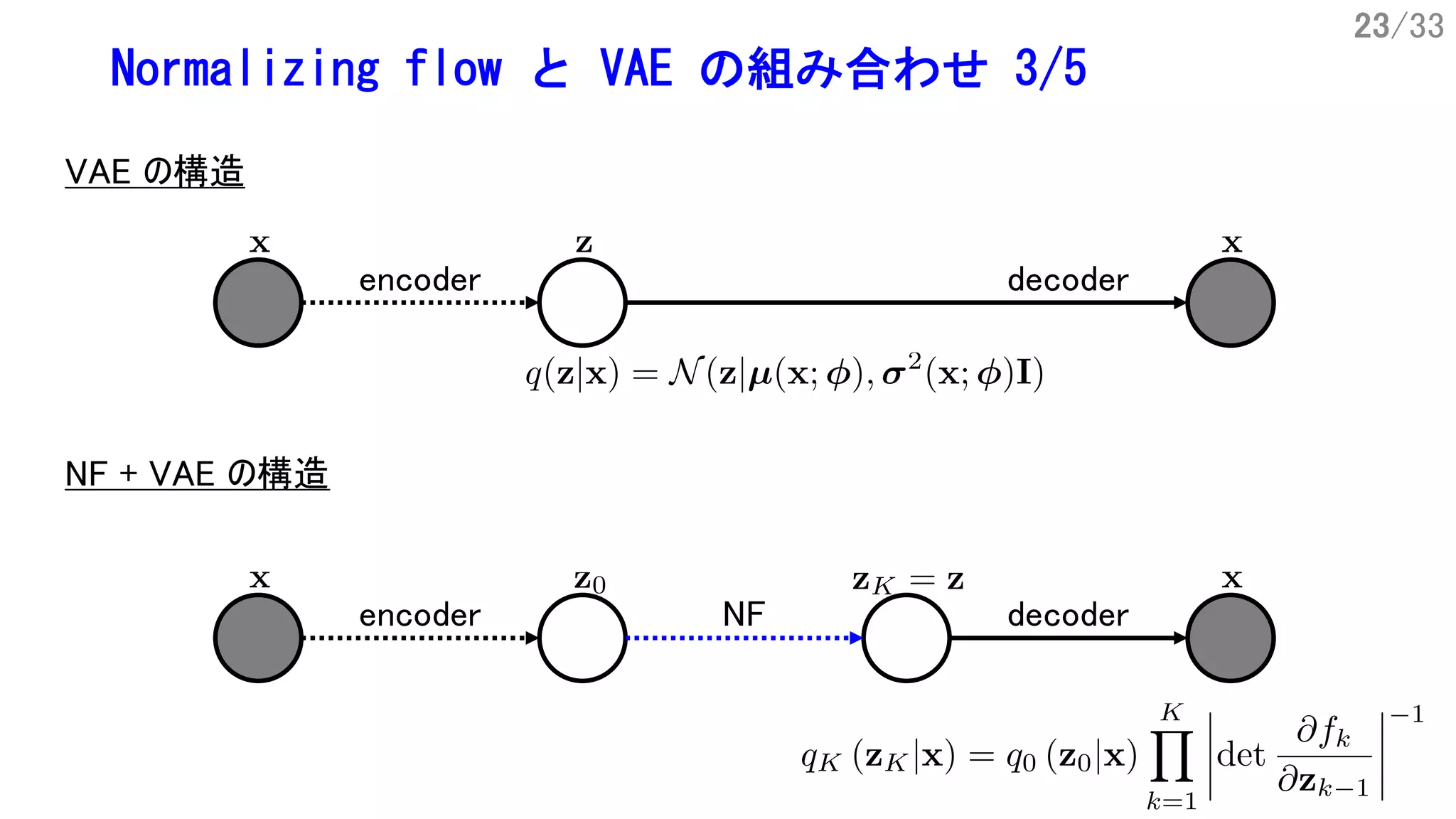
![21/33
Normalizing flow と VAE の組み合わせ 1/5
encoder decoder
VAE の構造
(amortized variational inference)
[Rezende+ ICML15, Figure 2] を一部改変](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-21-2048.jpg)
![22/33
Normalizing flow と VAE の組み合わせ 2/5
encoder decoder
normalizing flowNF + VAE の構造
[Rezende+ ICML15, Figure 2] を一部改変](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-22-2048.jpg)

![25/33
Normalizing flow と VAE の組み合わせ 5/5
2. 近似事後分布からサンプリング
1. ミニバッチ用意
3. ELBO 計算 (ELBO をサンプルで近似)
4. 変分/モデルパラメータに関して微分し、更新
“The resulting algorithm is a simple modification of amortized inference algorithm for DLGMs”
[Rezende+ ICML15, Algorithm 1]](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-25-2048.jpg)
![26/33
Normalizing Flow を用いた生成モデル
[Ermon+ 18]](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-26-2048.jpg)

![32/33
参考文献
• [Bishop 06] Bishop, C. M. (2006). Pattern recognition and machine learning. springer.
• [Dieng+ NIPS17] Dieng, A. B., Tran, D., Ranganath, R., Paisley, J., & Blei, D. (2017).
Variational Inference via χ Upper Bound Minimization. In Advances in Neural
Information Processing Systems (pp. 2732-2741).
• [Ermon+ 18] Ermon S. & Grover A. (2018). Normalizing flow models (CS236 course
notes). https://deepgenerativemodels.github.io/notes/flow/.
• [Grover+ AAAI18] Grover, A., Dhar, M., & Ermon, S. (2018, April). Flow-GAN:
Combining maximum likelihood and adversarial learning in generative models. In Thirty-
Second AAAI Conference on Artificial Intelligence.
• [Kingma+ ICLR14] Kingma, D. P., & Welling, M. (2014). Auto-encoding variational
Bayes. arXiv preprint arXiv:1312.6114.
• [Li+ NIPS16] Li, Y., & Turner, R. E. (2016). Rényi divergence variational inference. In
Advances in Neural Information Processing Systems (pp. 1073-1081).
• [Rezende+ ICML15] Rezende, D. J., & Mohamed, S. (2015). Variational inference with
normalizing flows. arXiv preprint arXiv:1505.05770.
• [Rumbos 08] Rumbos A. J. (2008). Probability lecture notes.
https://pages.pomona.edu/~ajr04747/Spring2008/Math151/Math151NotesSpring08.pd
f.](https://image.slidesharecdn.com/tutorial-flow-nitta-190714163524/75/Normalizing-Flow-32-2048.jpg)

![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)




























