Downloaded 30 times







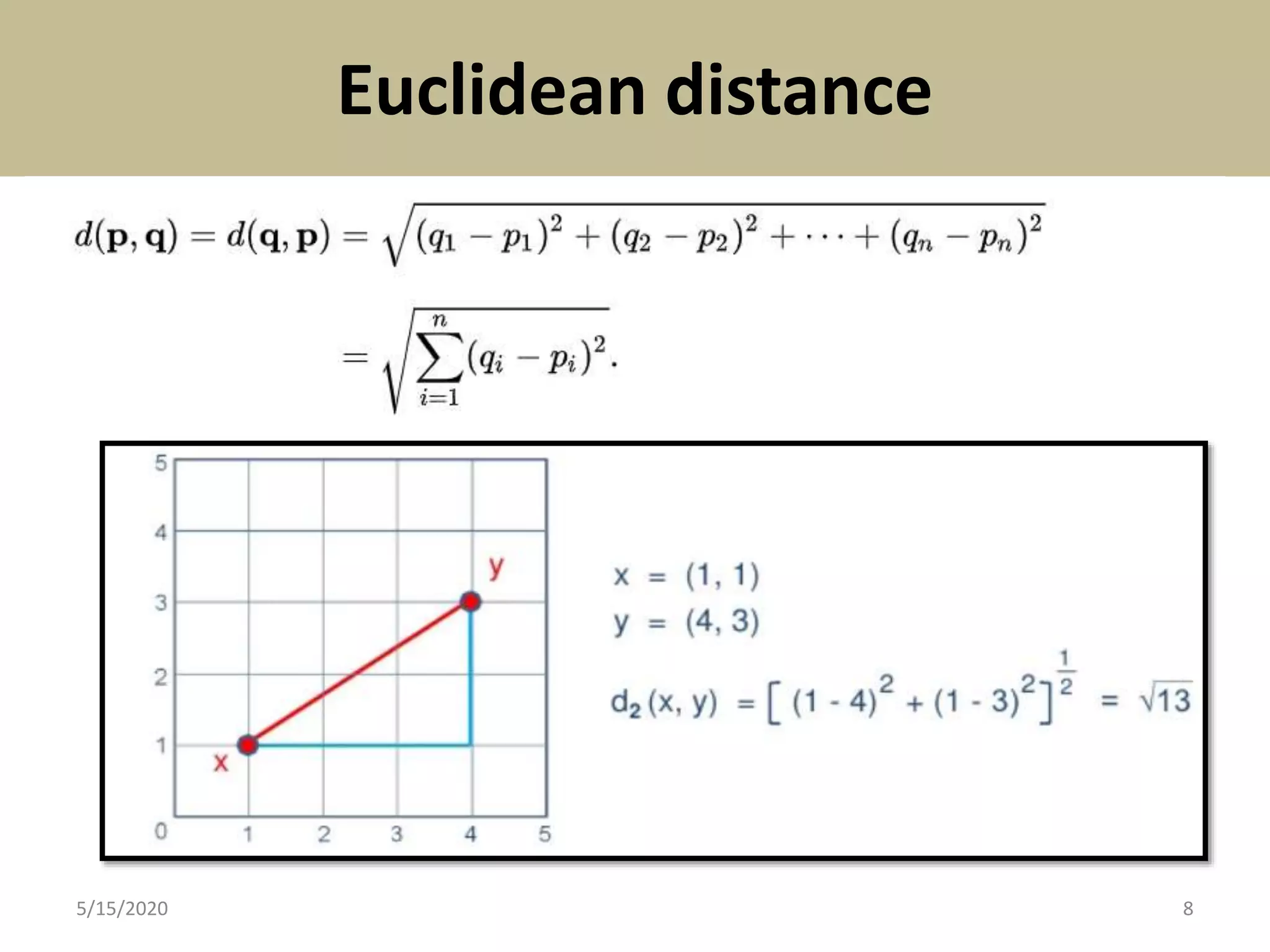
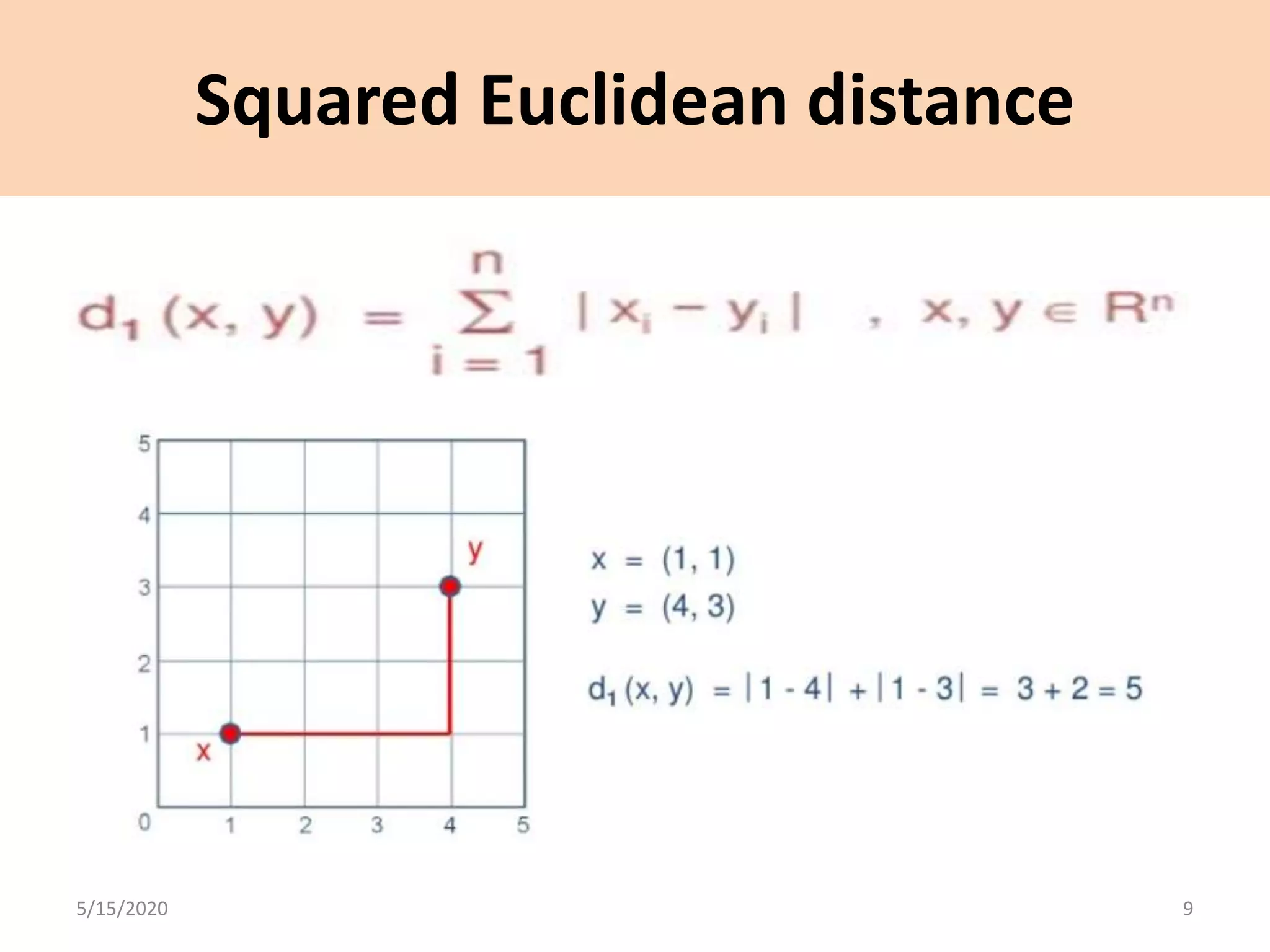
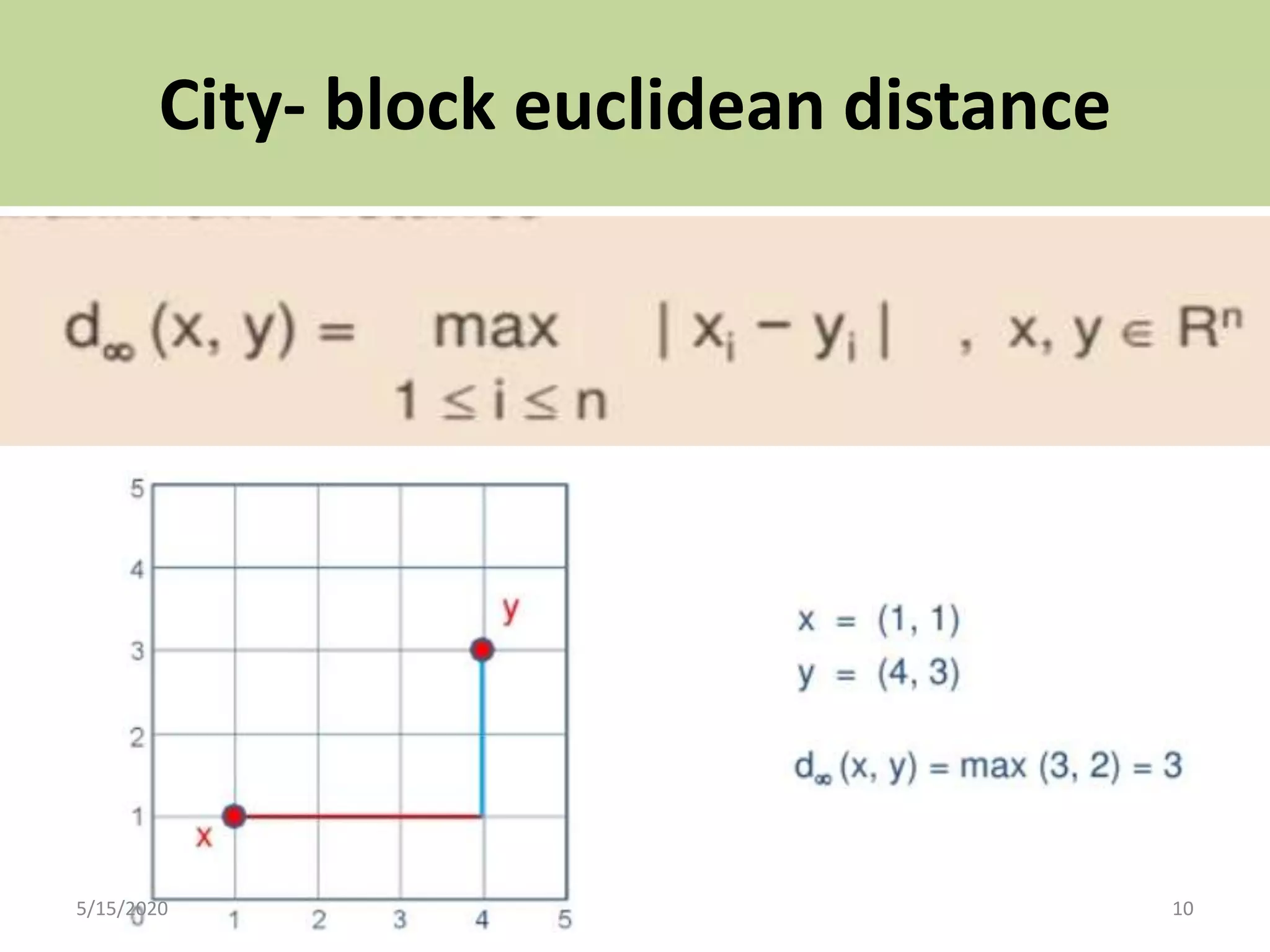


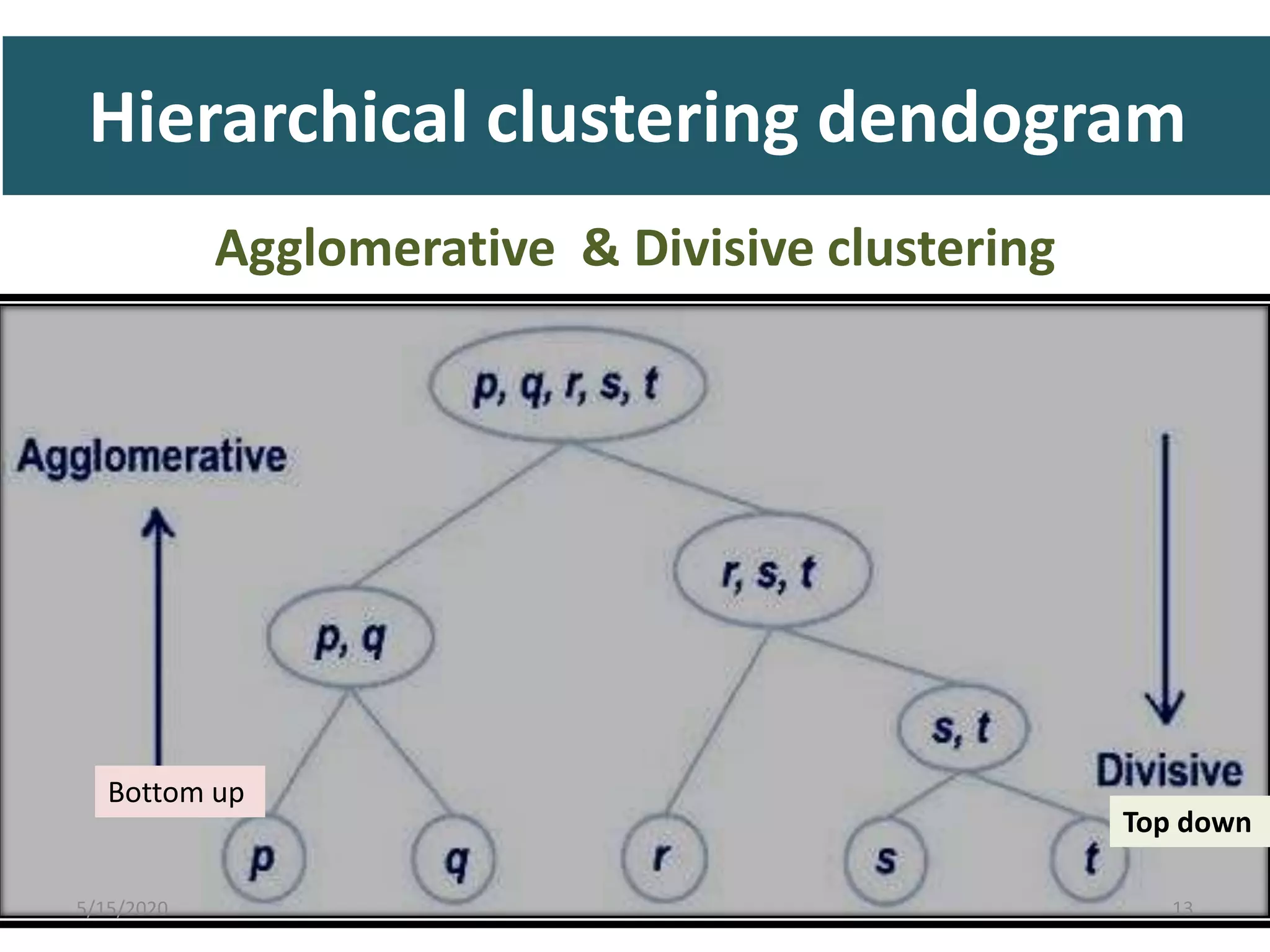
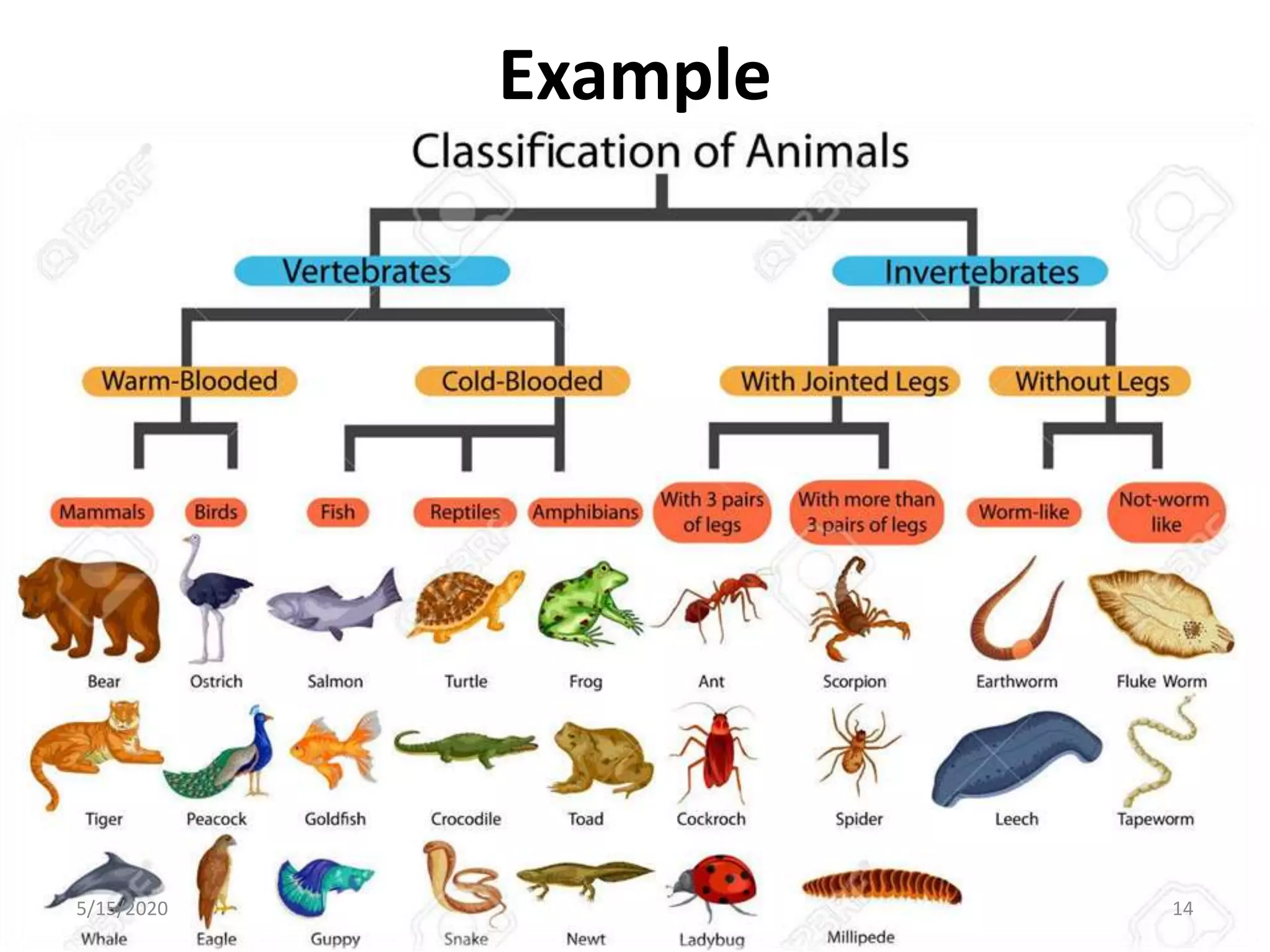


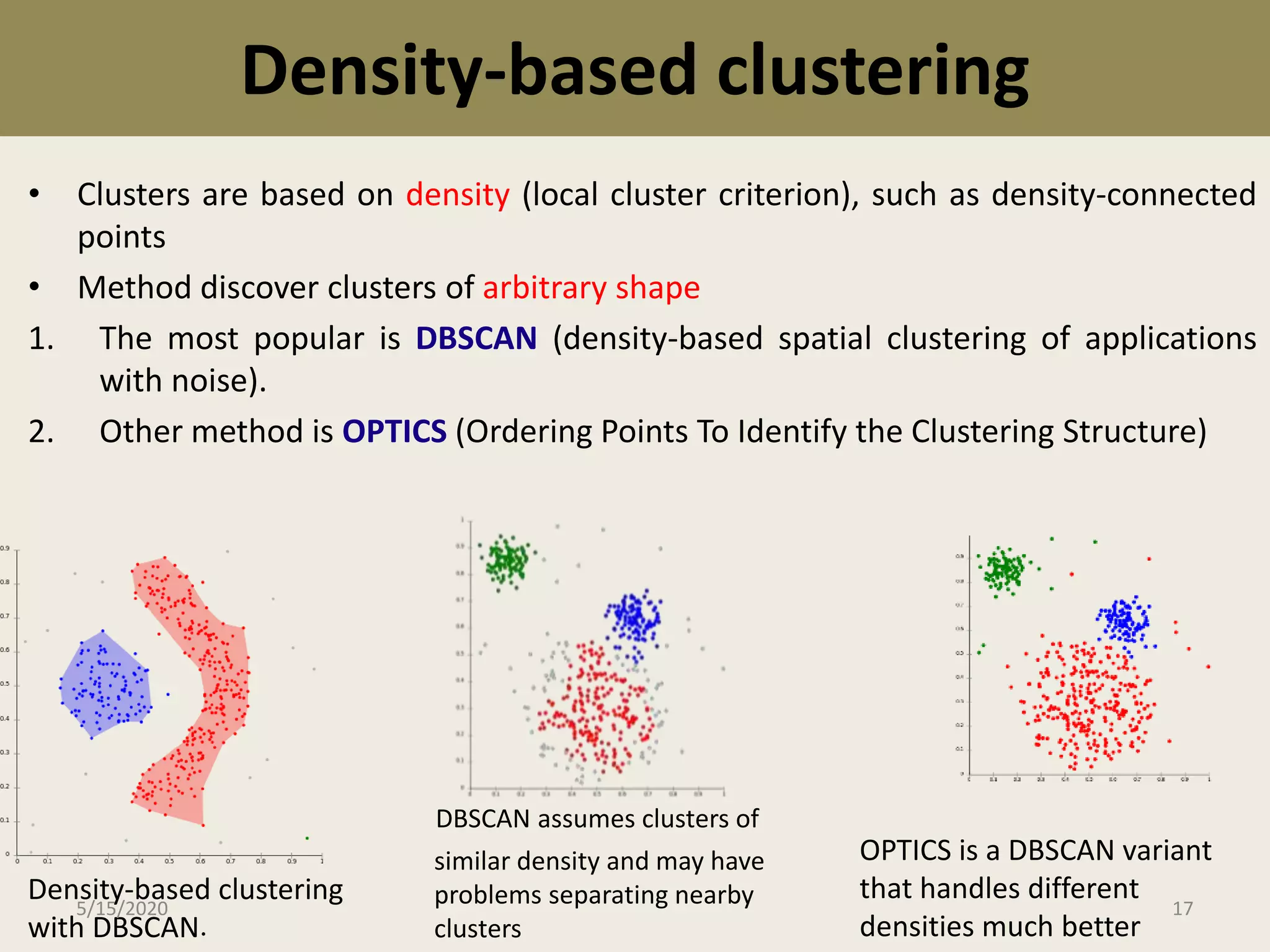

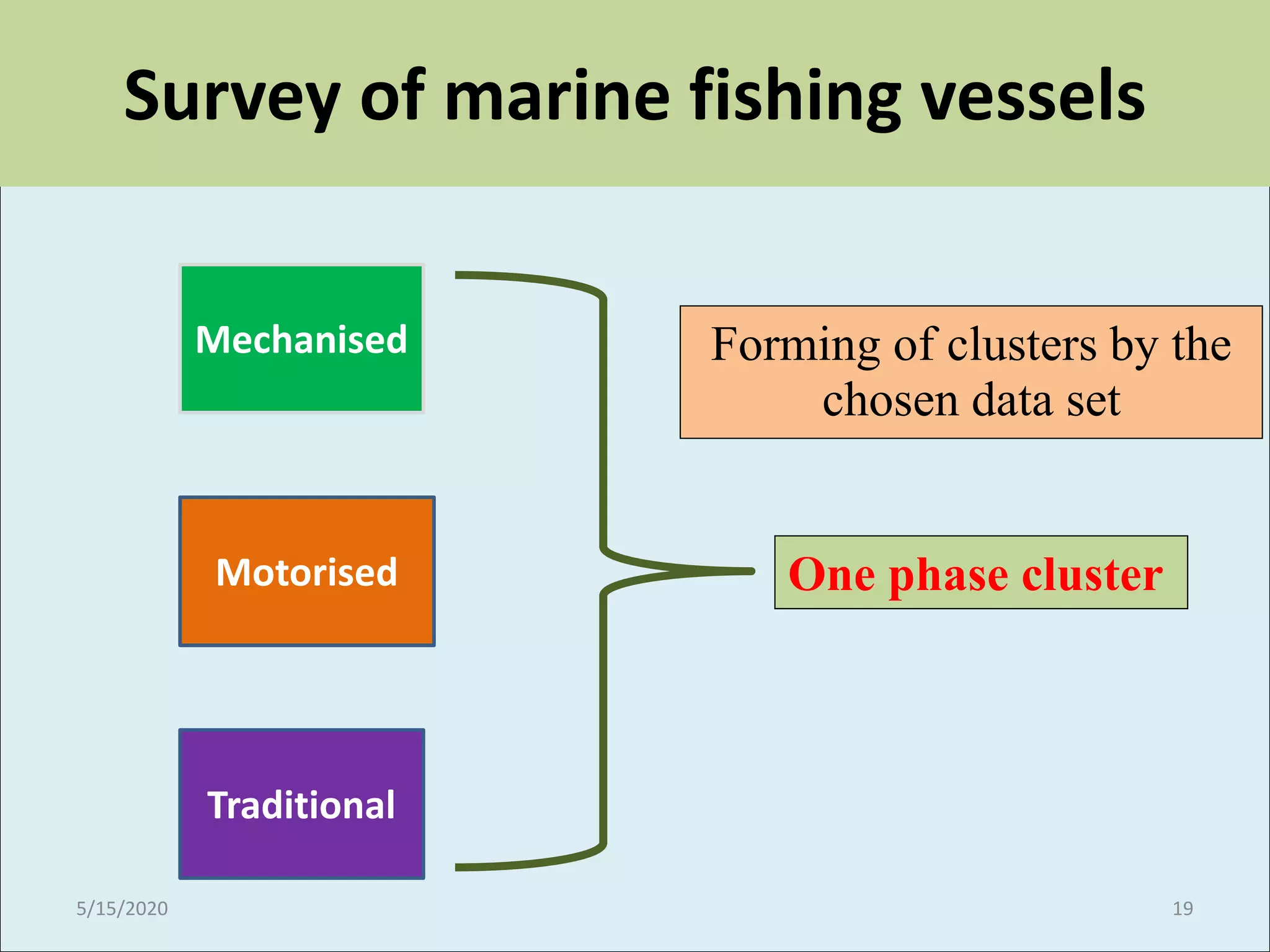
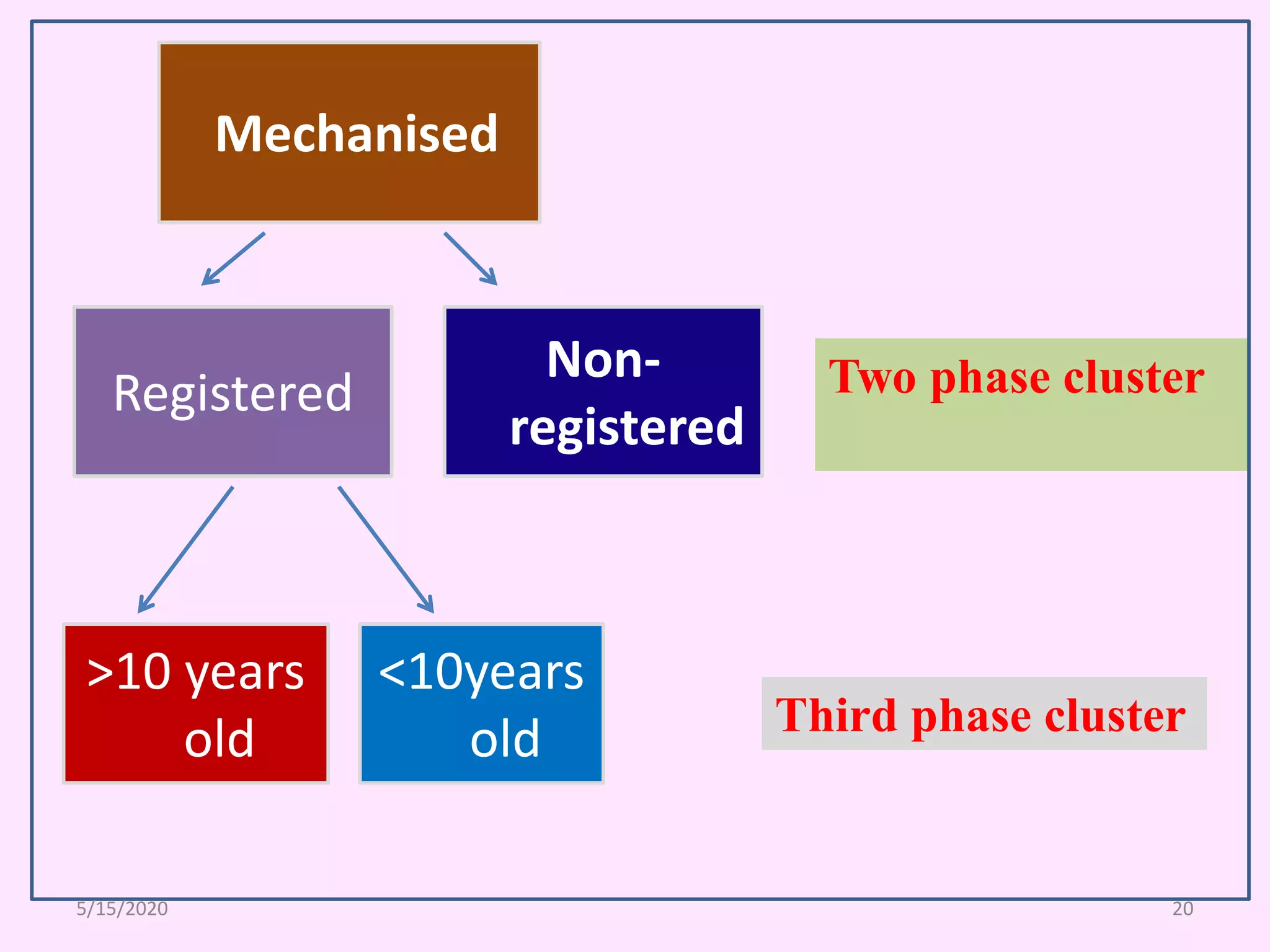



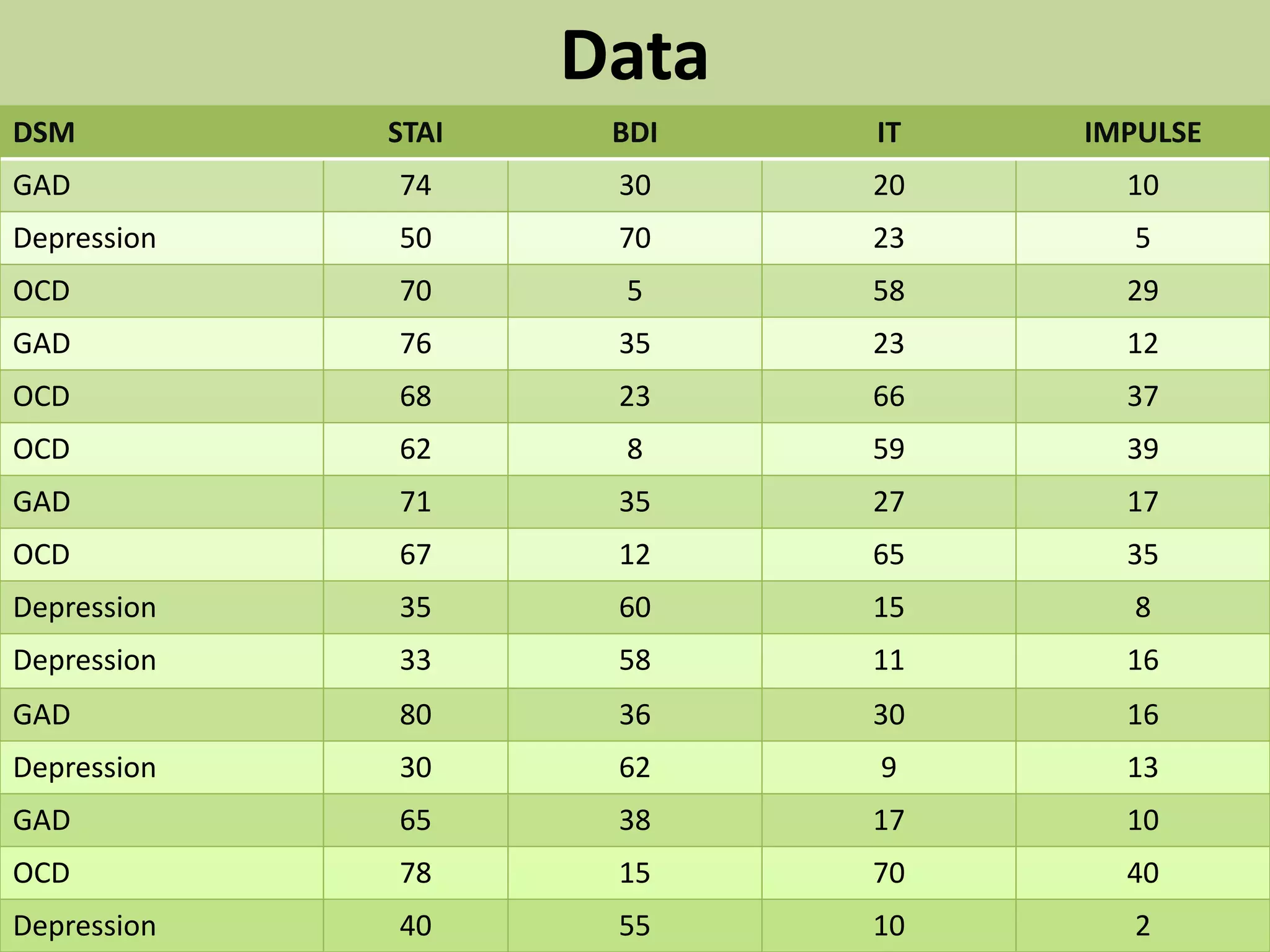

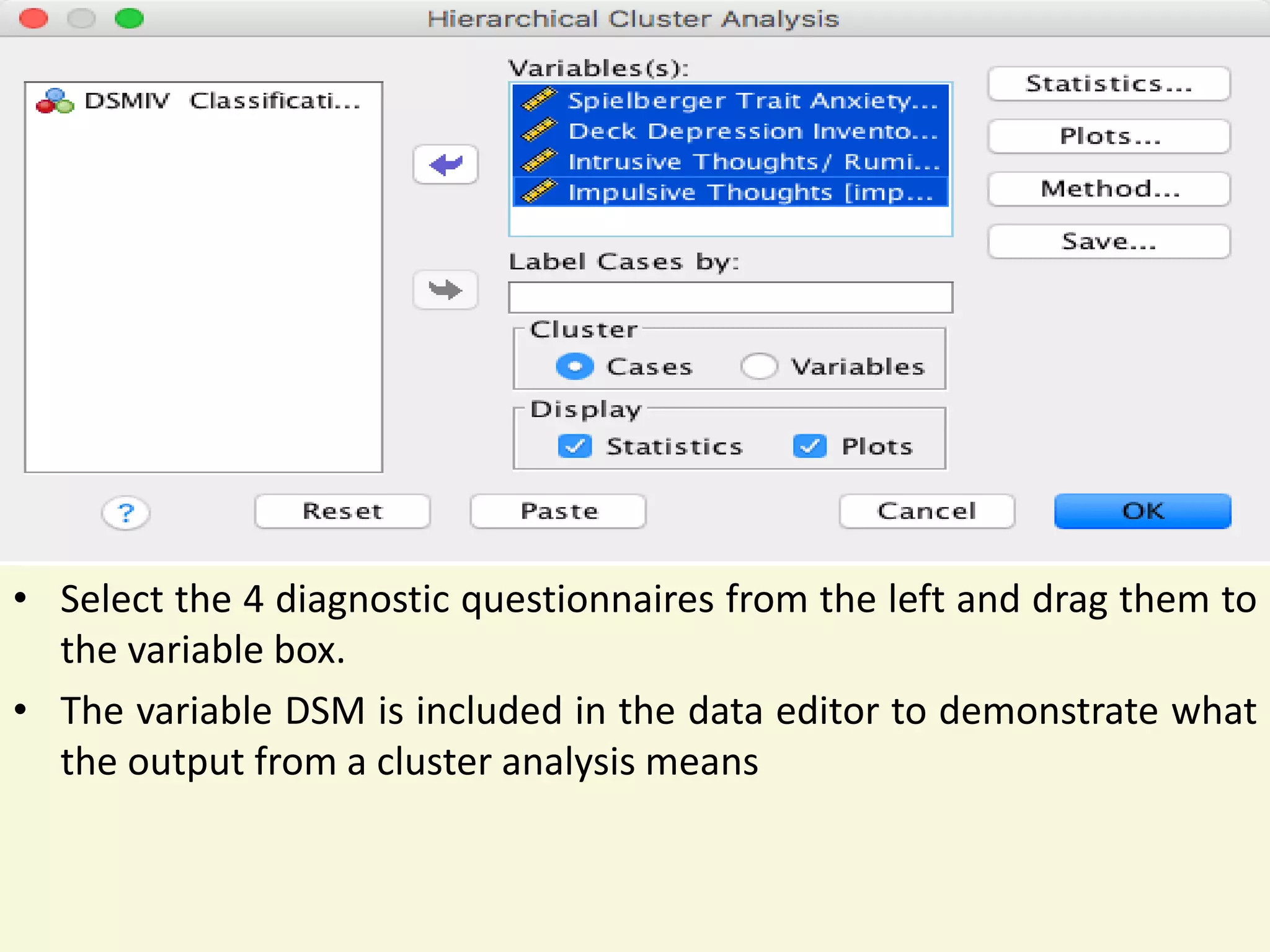
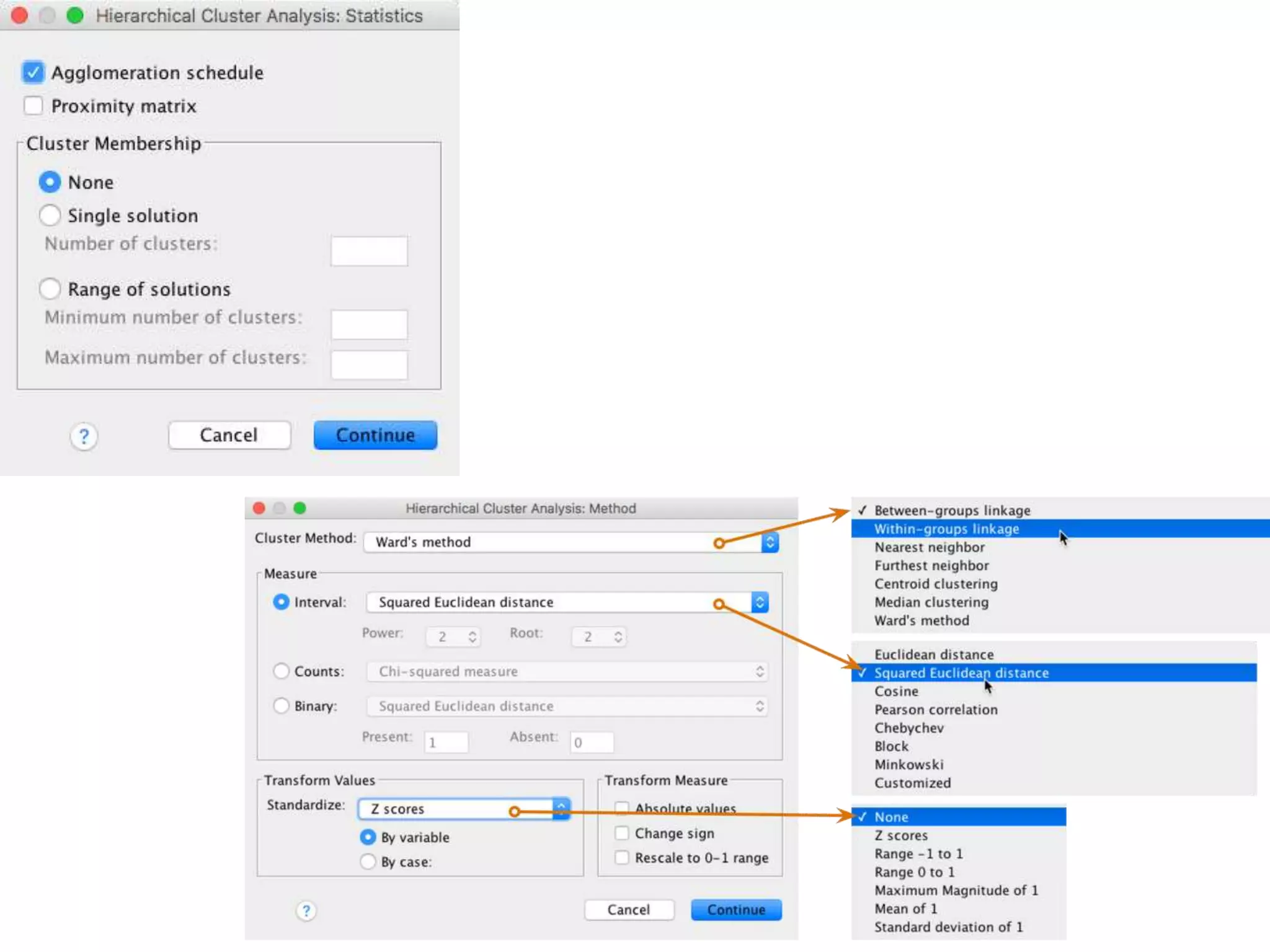


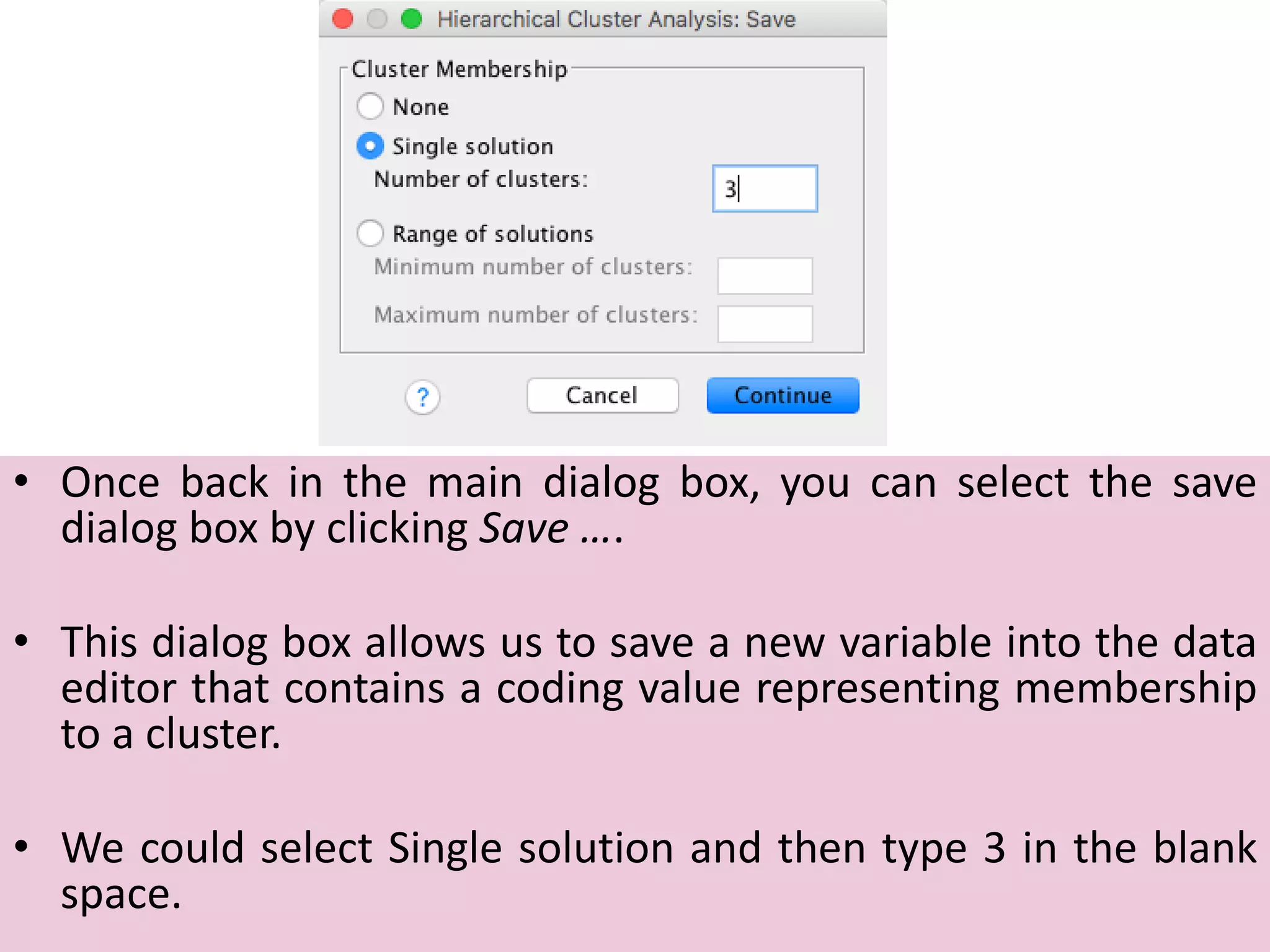





The document explains cluster analysis, a multivariate statistical technique that groups objects based on their homogeneity of characteristics, ultimately aiding in data classification and resource savings. It outlines various clustering methods such as hierarchical, centroid-based, distribution-based, and density-based clustering, alongside their applications in fields like healthcare, marketing, and environmental studies. Additionally, it describes the assumptions, advantages, and disadvantages of cluster analysis, highlighting its effectiveness in generating meaningful patterns from complex datasets.



































































