Downloaded 10 times





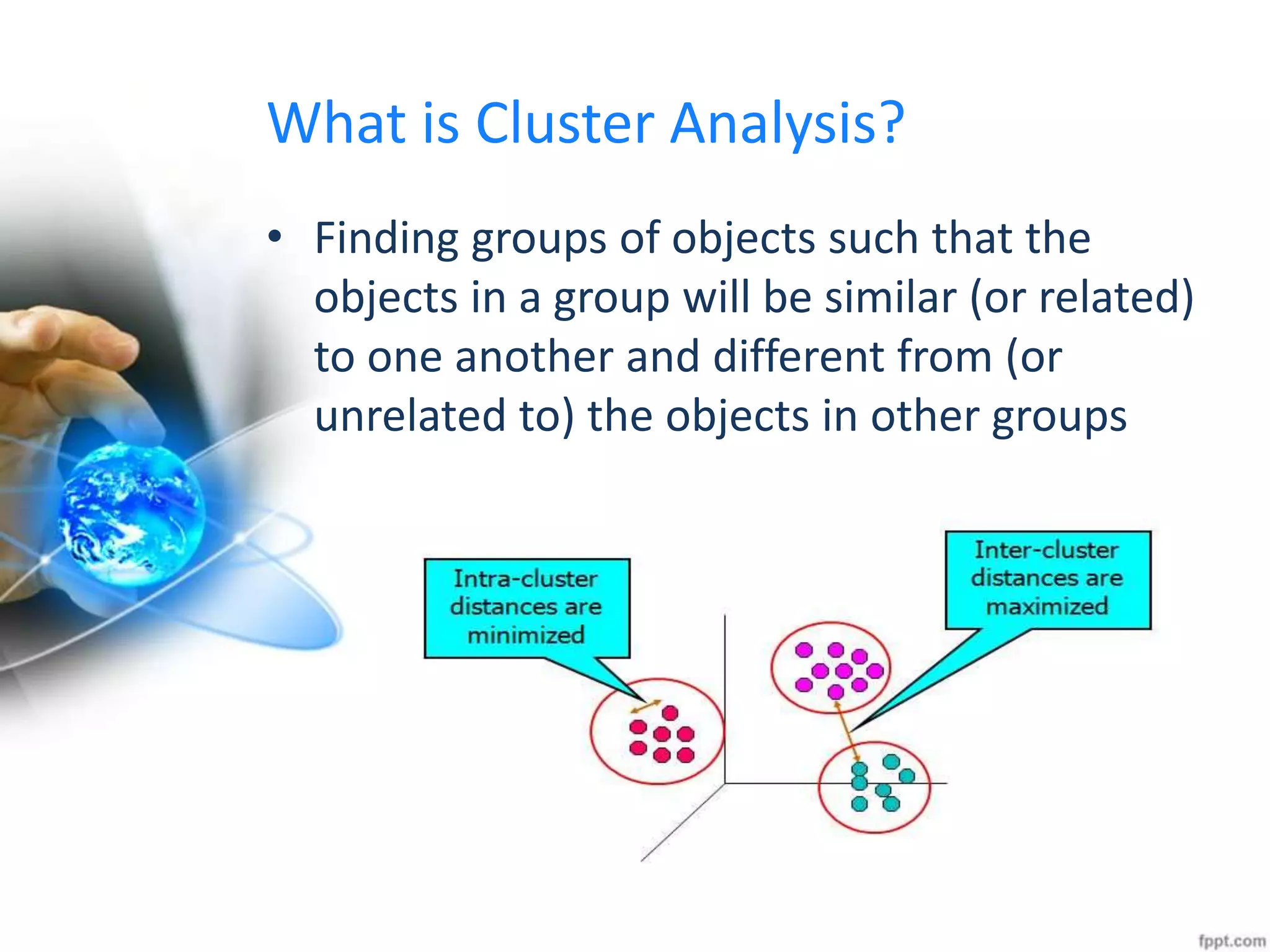
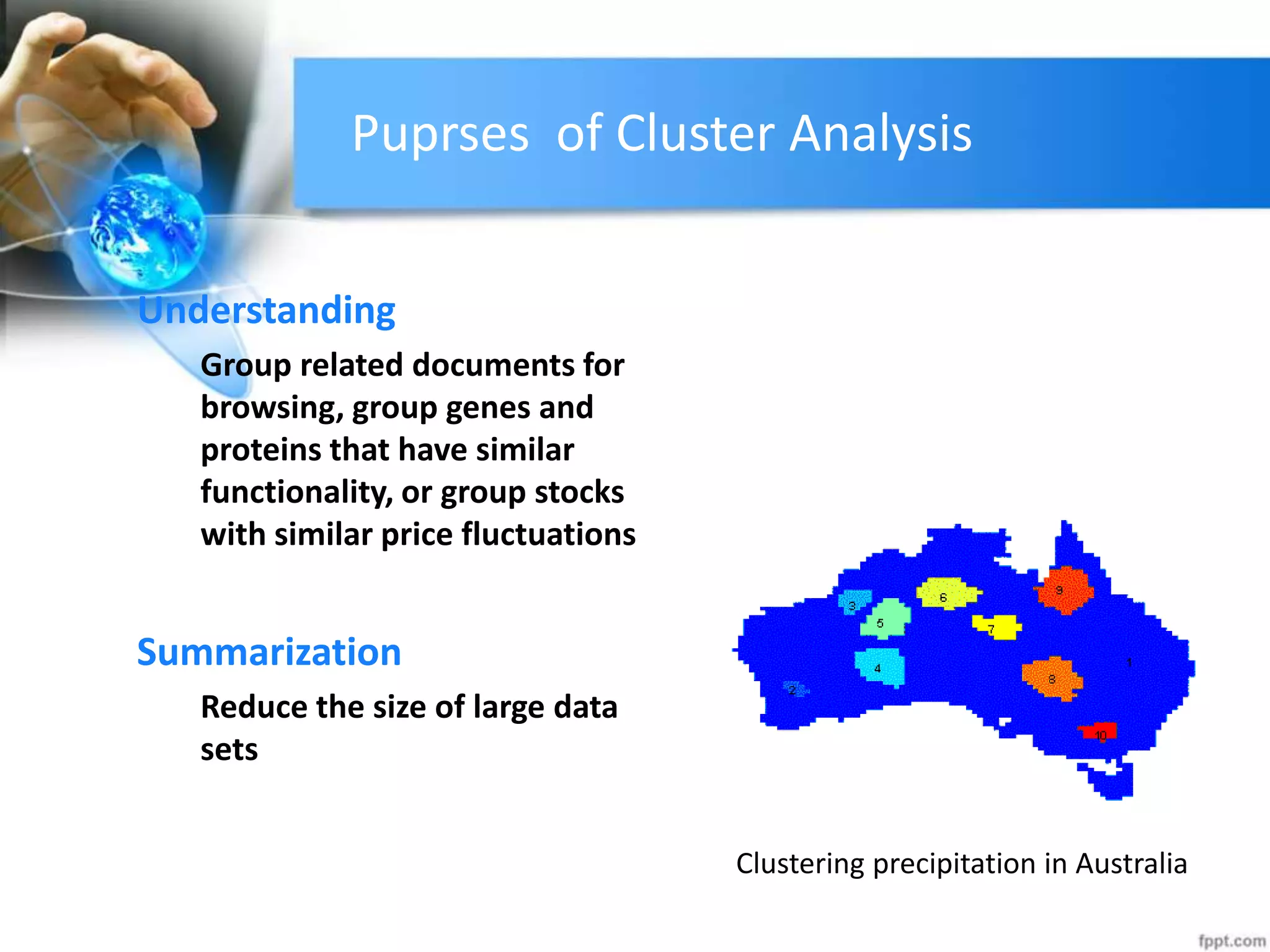





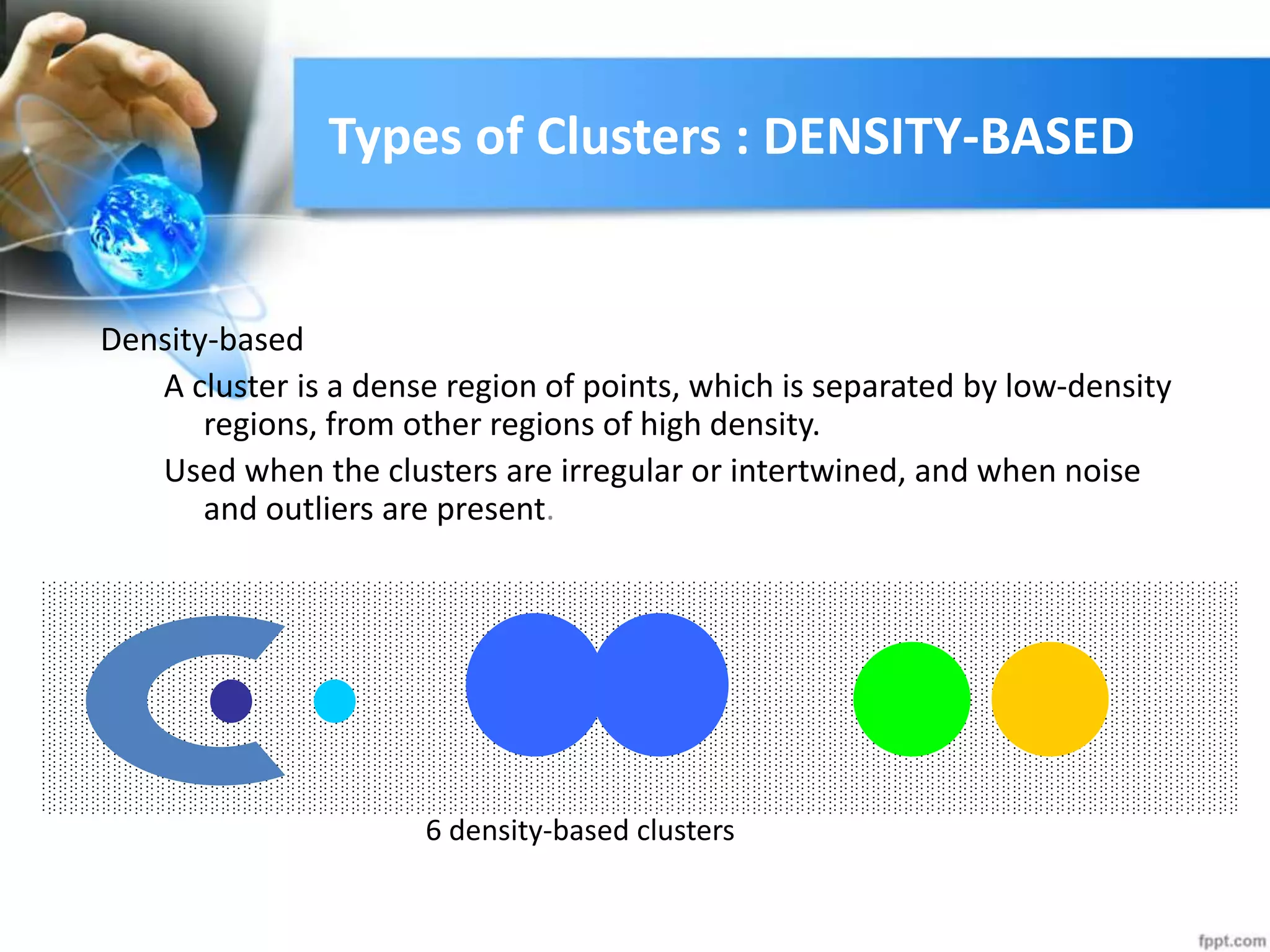


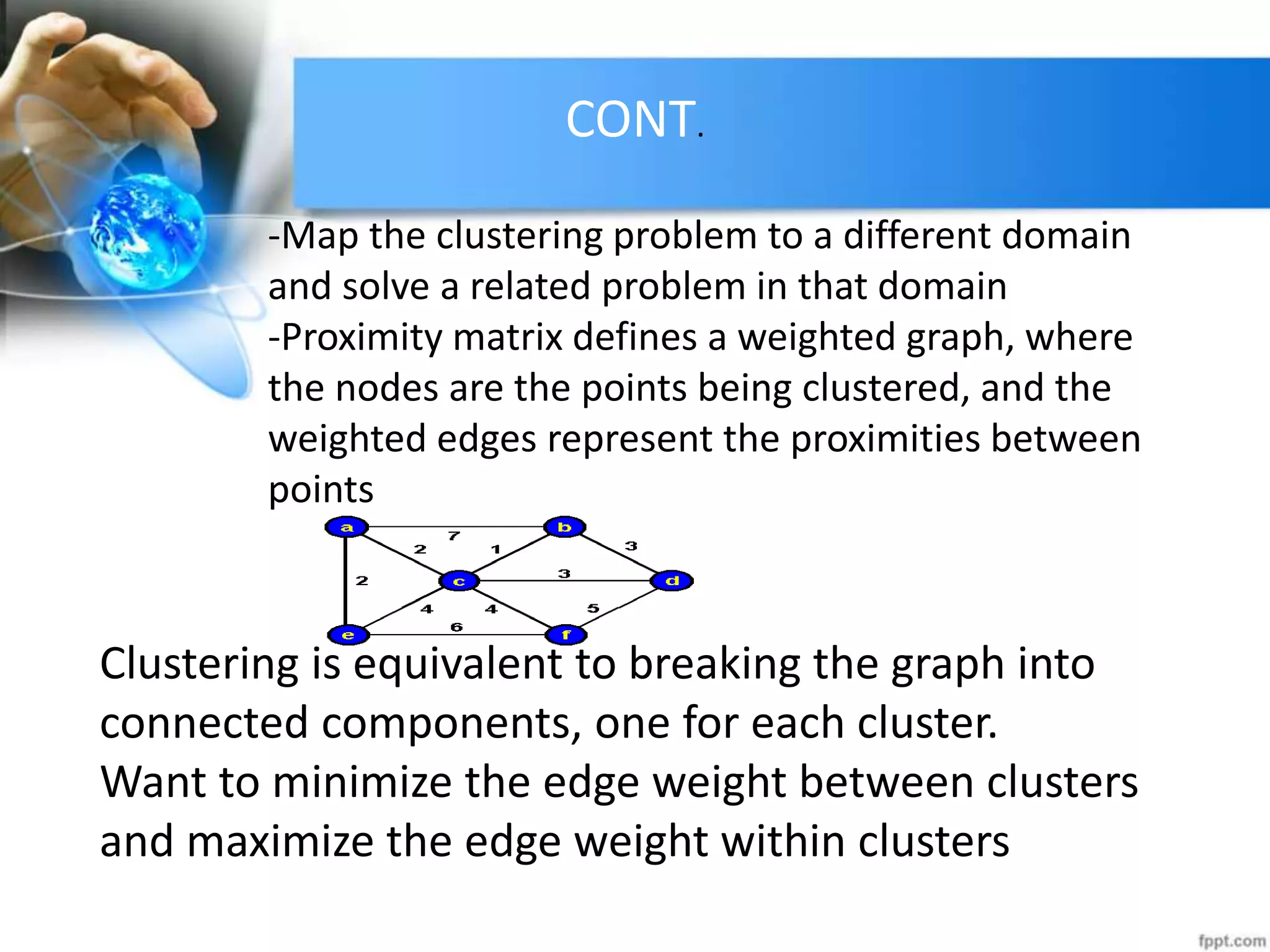


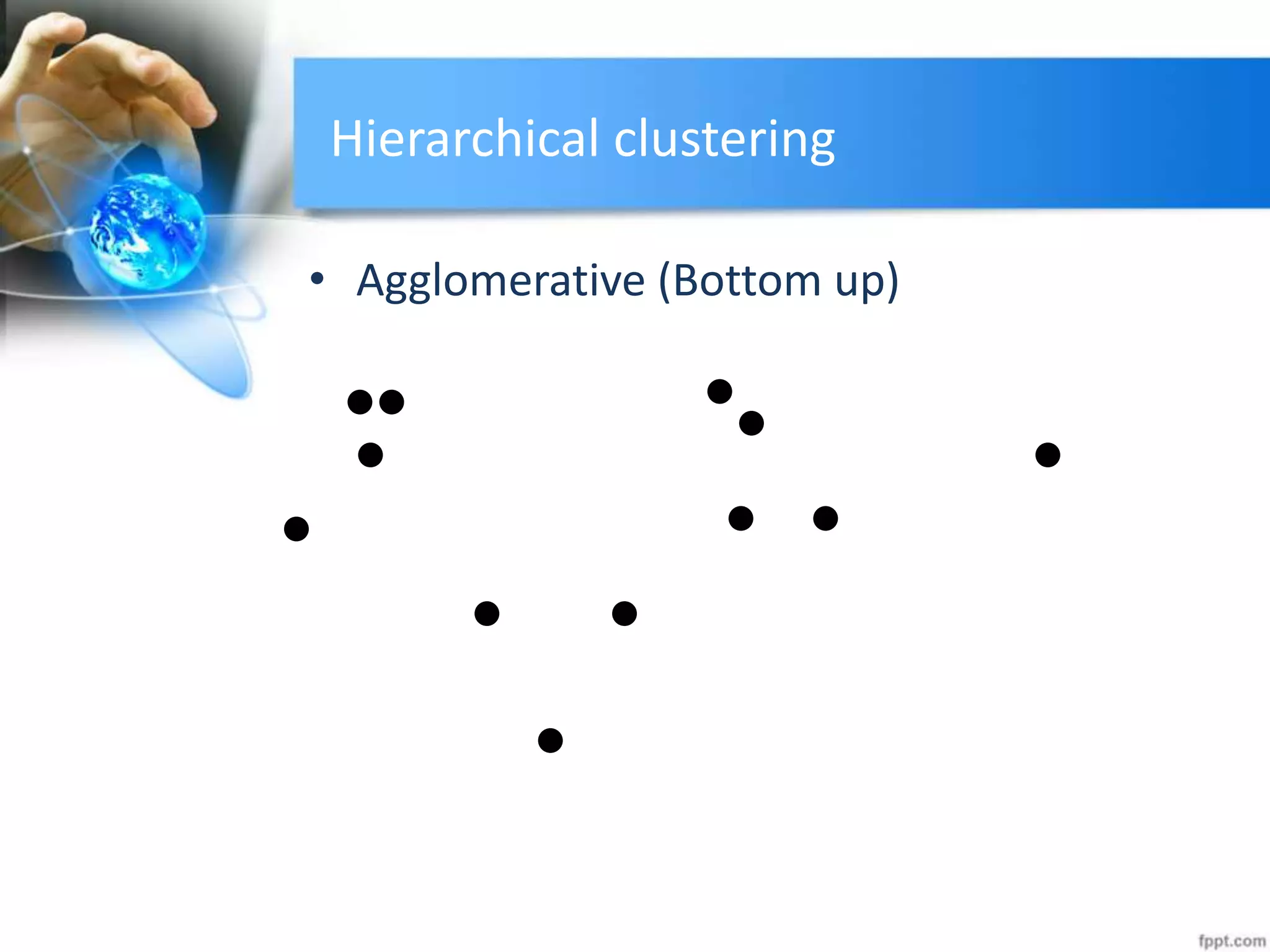

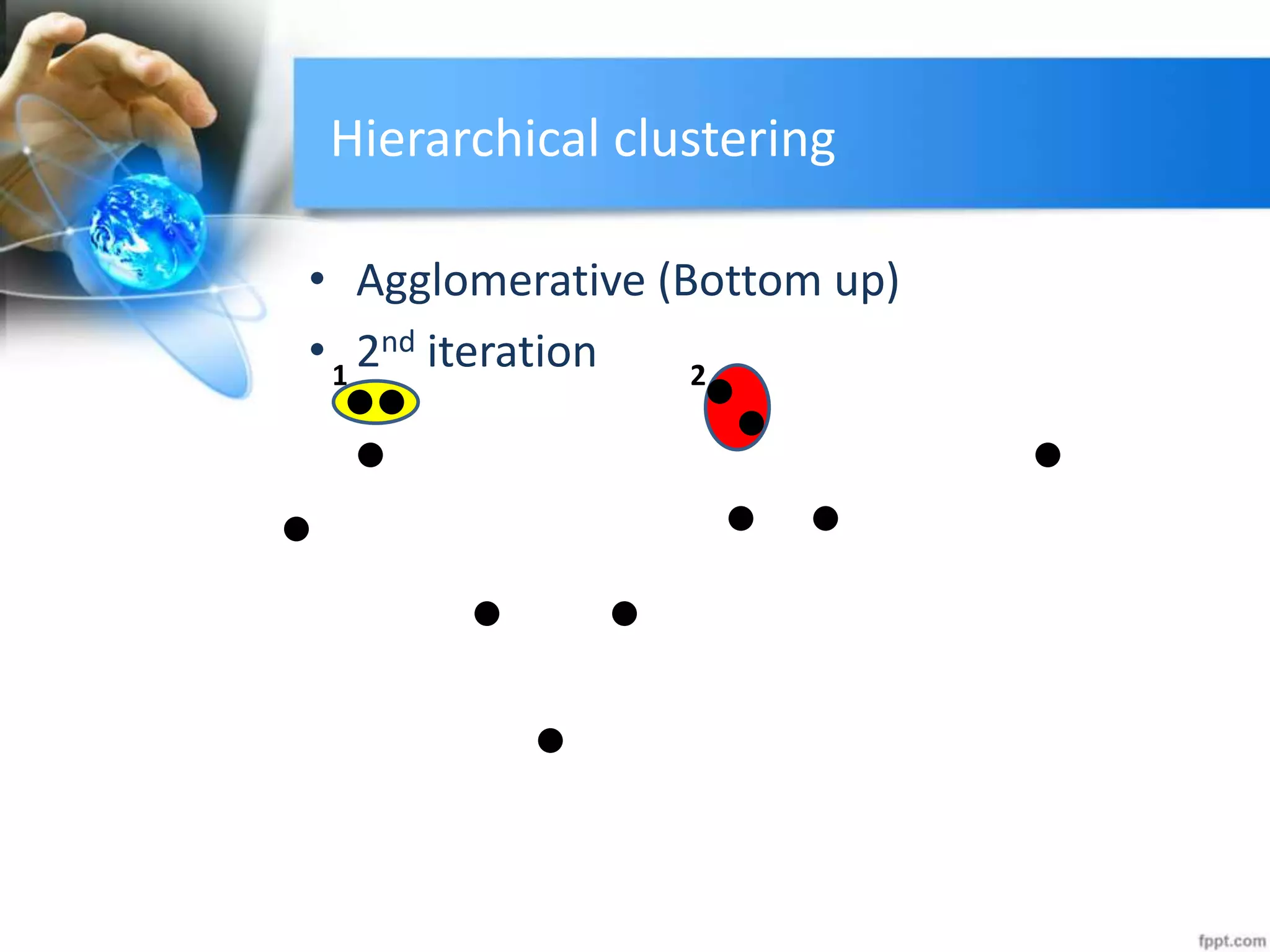







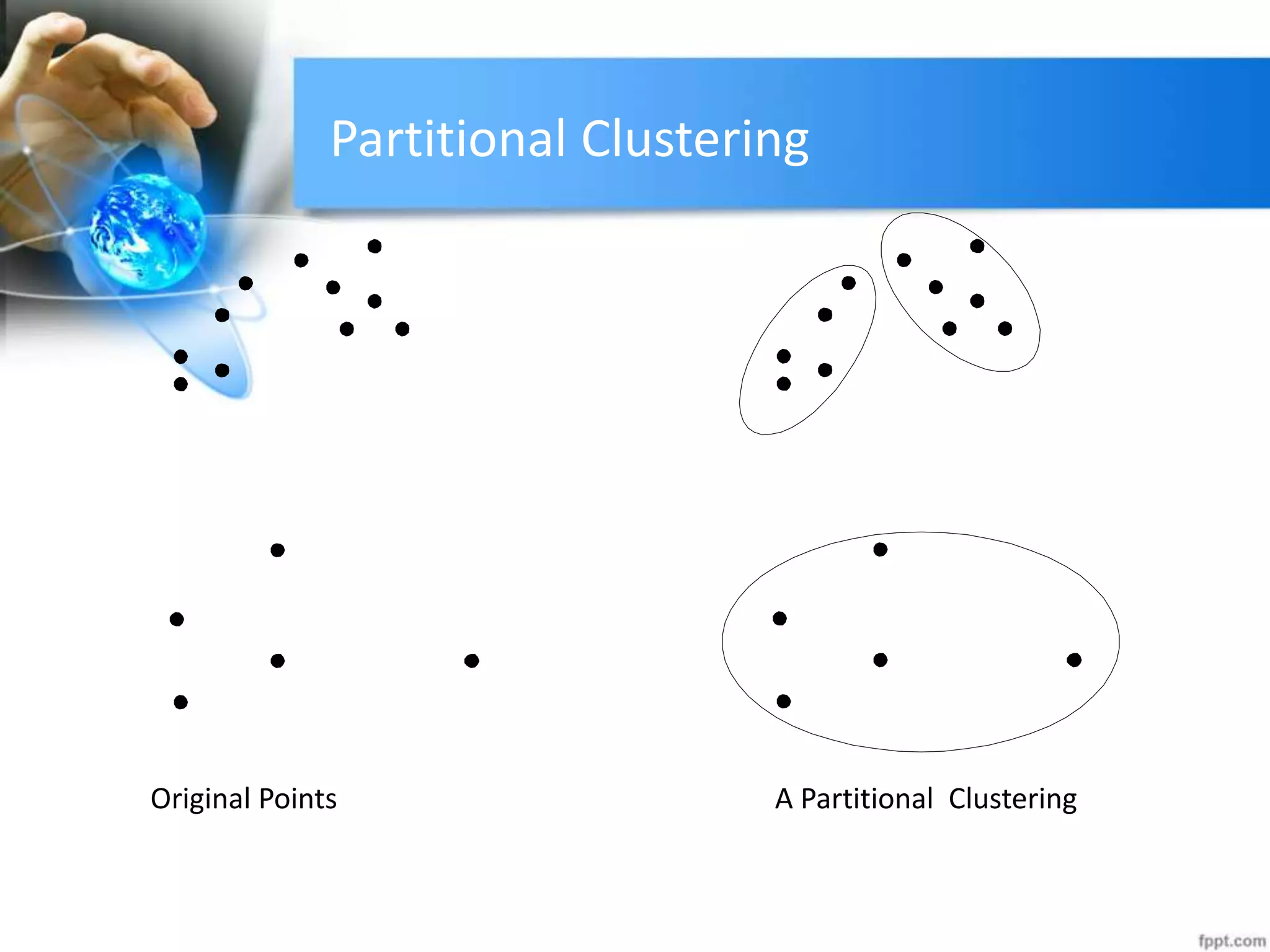










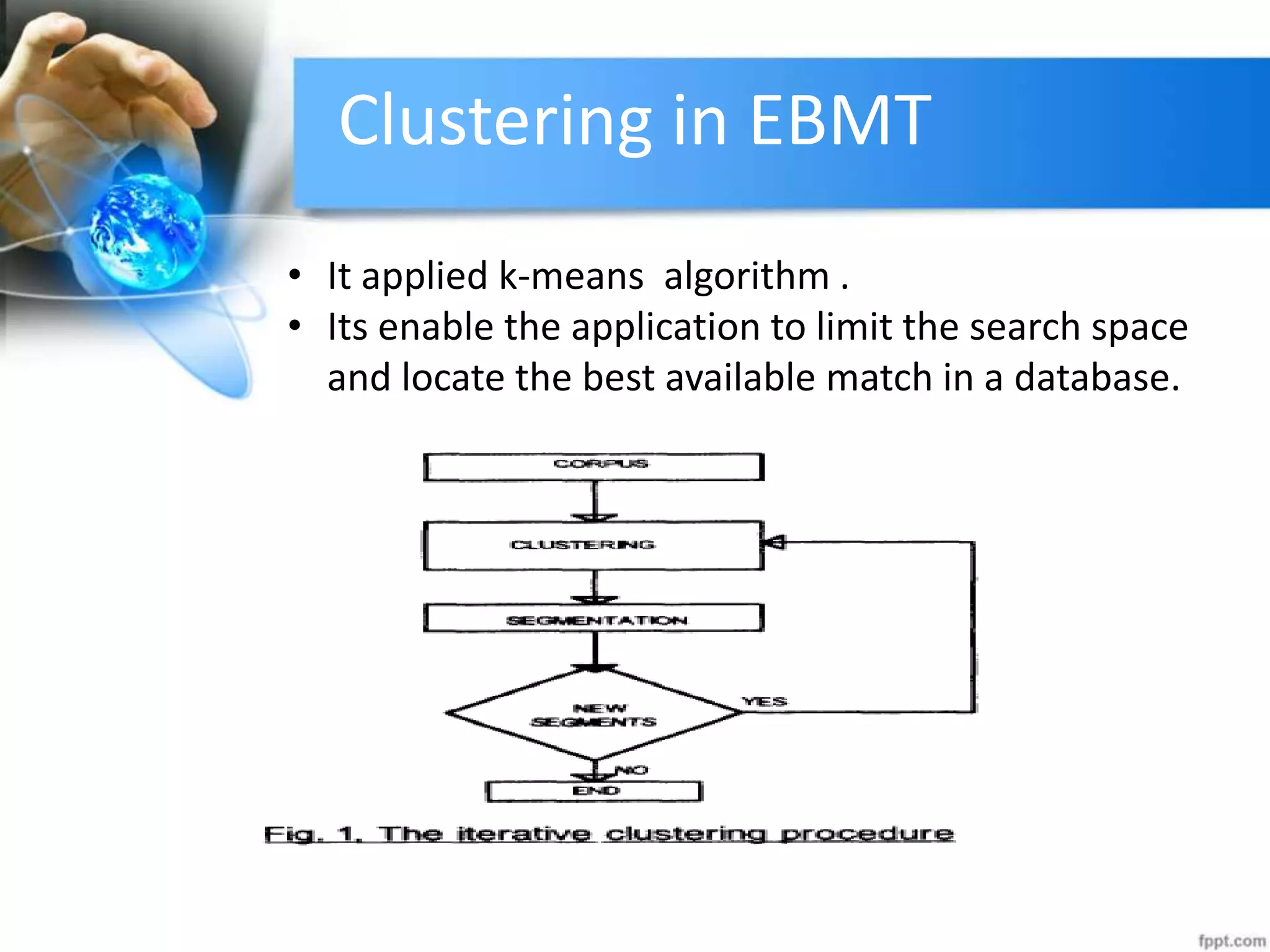




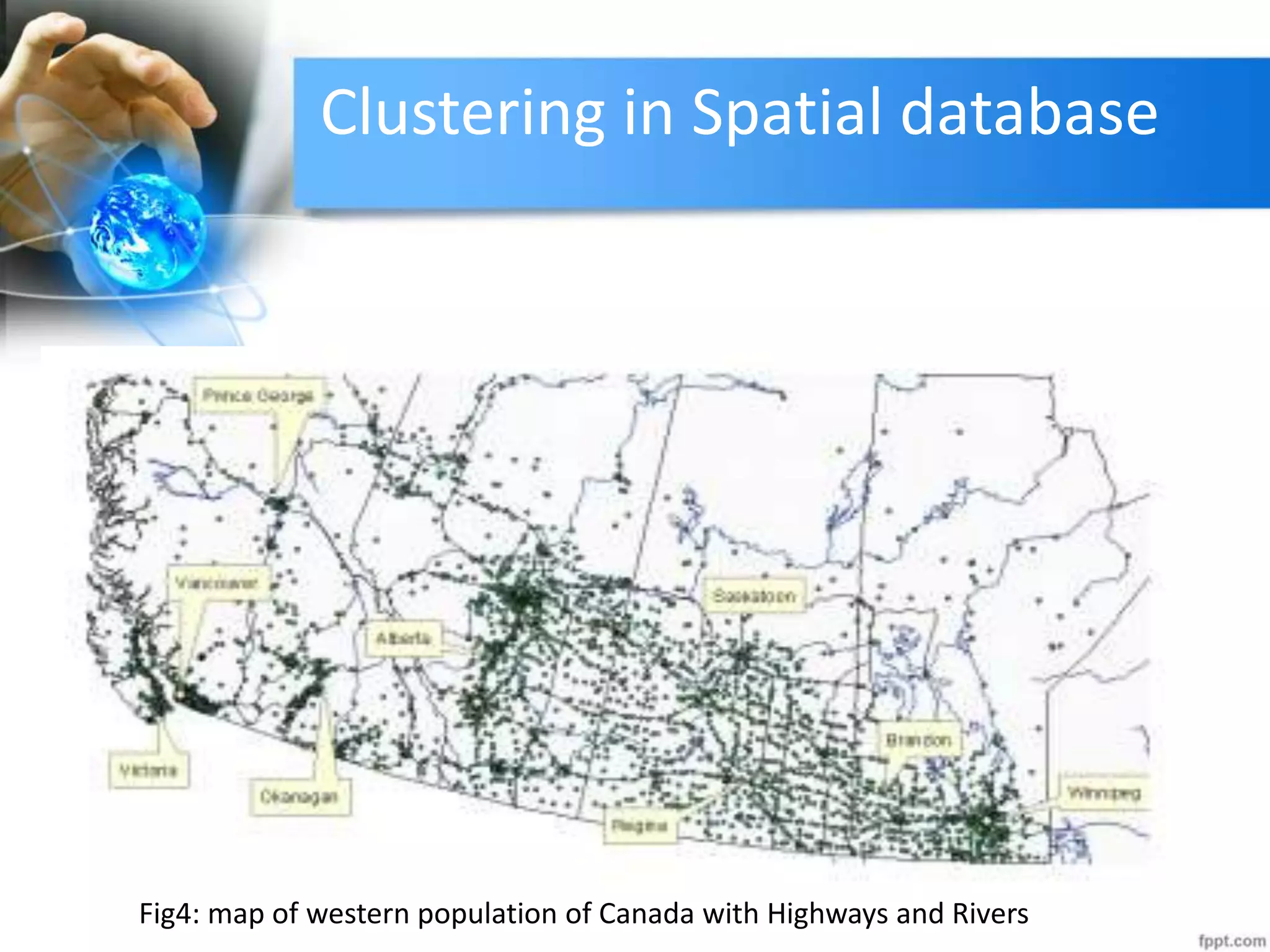






The document discusses clustering analysis for data mining. It begins by outlining the importance and purposes of cluster analysis, including grouping related data and reducing large datasets. It then describes different types of clustering like hierarchical, partitional, density-based, and grid-based clustering. Specific clustering algorithms like k-means, hierarchical clustering, and DBSCAN are also covered. Finally, applications of clustering are mentioned, such as for machine translation, online shopping recommendations, and spatial databases.



















































































