Downloaded 16 times

















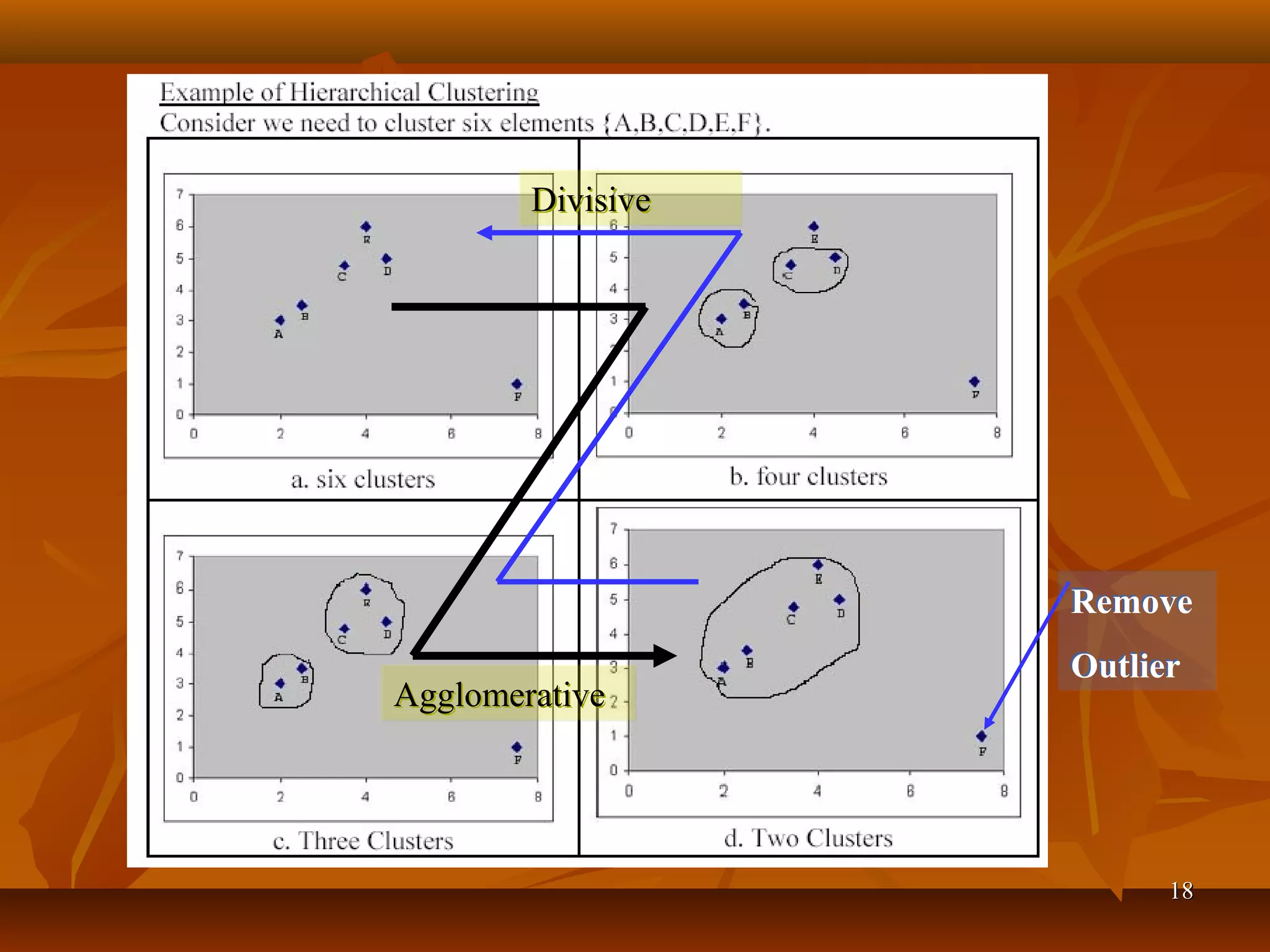















Clustering is the process of grouping similar data objects into clusters based on defined characteristics. Various clustering methods exist, including partition-based, hierarchical, density-based, grid-based, and model-based approaches, each with specific algorithms and applications in fields like marketing and city planning. Additionally, outlier detection techniques are essential for tasks such as fraud detection, leveraging statistical and distance-based approaches.



































































