Downloaded 12 times









![Similarity and Dis-similarity measure (cont.)
• Measures of distance
• .1) Euclidean Distance
• The distance between two p dimensional observations (items) x’ = [x1, x2,x3 ….xp] and y’ = [y1, y2,y3 ….yp ]
• 𝑑 𝑥, 𝑦 = (𝑥1−𝑦1)2 + (𝑥2−𝑦2)2+. . . +(𝑥 𝑝−𝑦𝑝)2
• 2) Minkowski Metric
• 𝑑 𝑥, 𝑦 = 𝑖=1
𝑝
𝑥𝑖 − 𝑦𝑖
𝑚
1
𝑚
• m=1, it becomes city block distance
• m=2, it becomes Euclidean distance
3) Canberra metric :-
𝑑 𝑥, 𝑦 =
𝑖=1
𝑝
𝑥𝑖 − 𝑦𝑖
(𝑥𝑖 + 𝑦𝑖)
4) Czekanowski Coefficient
𝑑 𝑥, 𝑦 = 1 − 𝑖=1
𝑝
min( 𝑥 𝑖,𝑦 𝑖)
𝑖=1
𝑝
(𝑥 𝑖+𝑦 𝑖)](https://image.slidesharecdn.com/cluster1-180411134247/85/Cluster-Analysis-11-320.jpg)

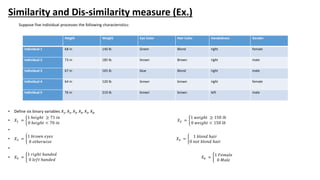


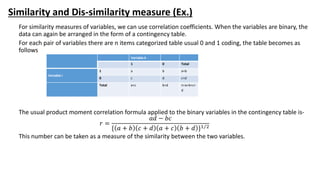





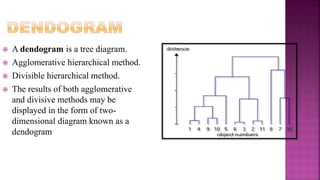

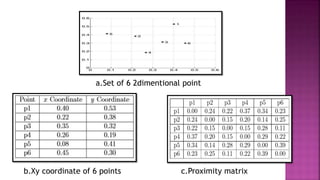
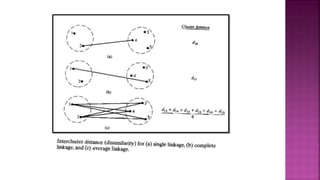




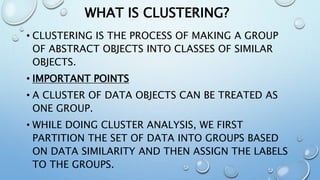
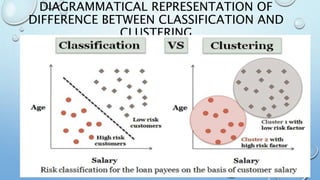
The document outlines key concepts in data analysis, including clustering, factor analysis, and data classification. It explains different types of clustering methods, such as hierarchical and k-means clustering, and emphasizes the importance of similarity and dissimilarity measures for classification tasks. Additionally, it discusses various distance measures used in these analyses and provides examples of how data can be clustered based on certain characteristics.























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











