Downloaded 40 times











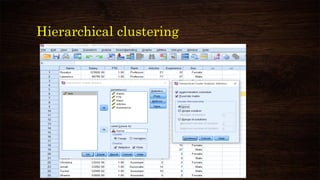
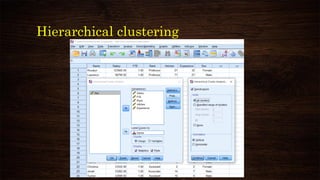
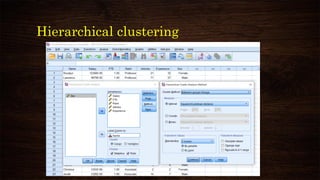
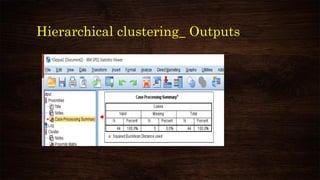

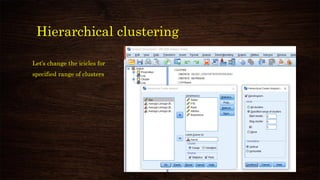

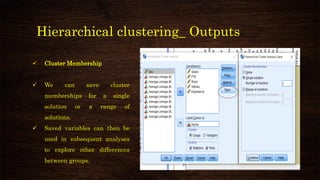
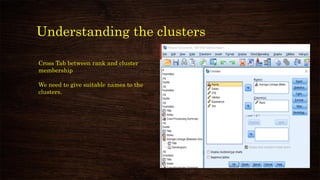

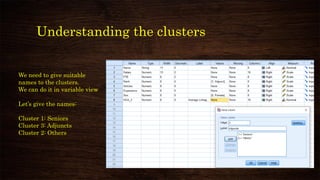
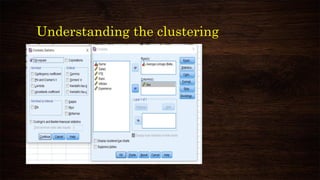


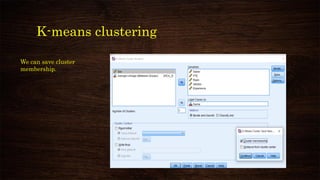
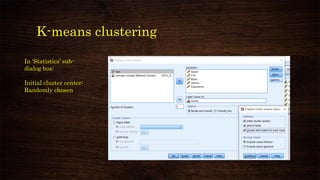
![K-means clustering
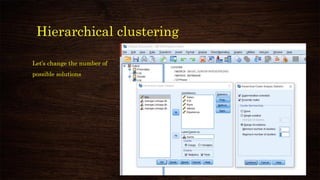
Number of Cluster:
Ideally between 2 to 5
[Subjective]
Number of iteration:
10/20 should be enough](https://image.slidesharecdn.com/clusteranalysisusingspss-210314015734/85/Cluster-analysis-using-spss-37-320.jpg)
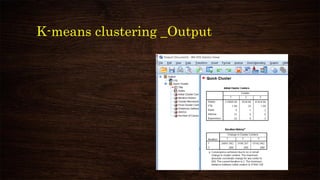
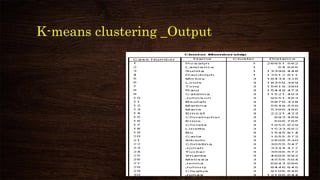
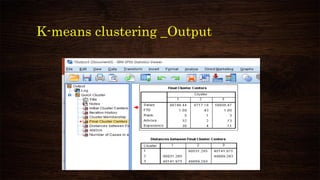
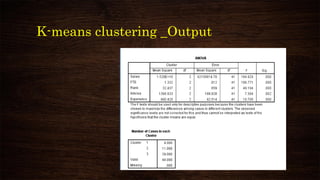
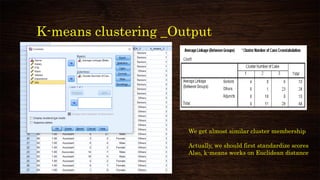
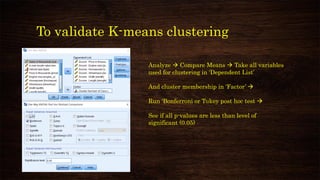
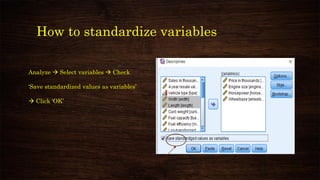

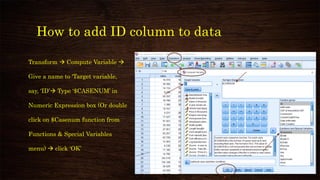


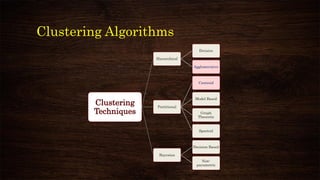
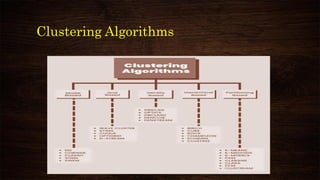
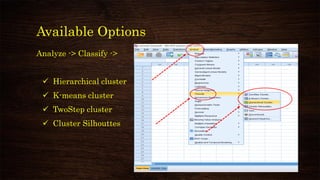
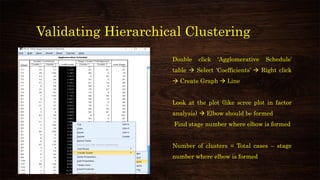
This document provides an overview and agenda for a presentation on multivariate analysis. It introduces the presenter, Dr. Nisha Arora, and lists her qualifications and areas of expertise, which include statistics, data analysis, machine learning, and online teaching. The presentation agenda covers topics like cluster analysis using SPSS, including different clustering algorithms, applications of cluster analysis, and how to interpret and validate clustering outputs and solutions.