Downloaded 2,169 times










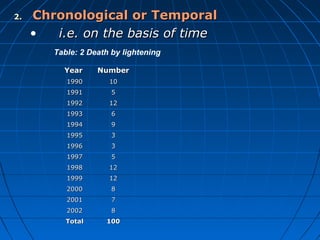

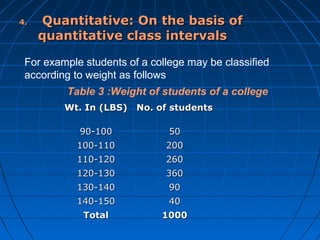
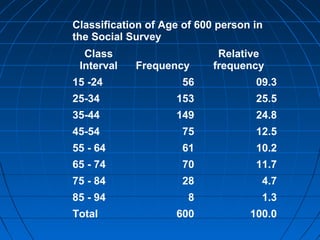


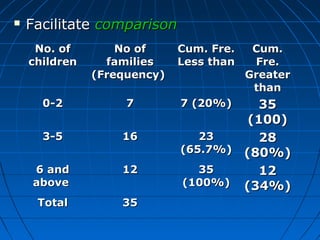




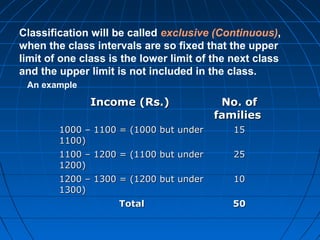
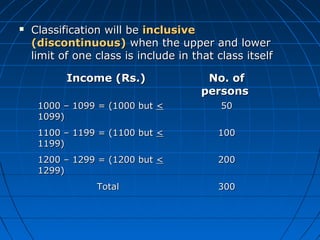





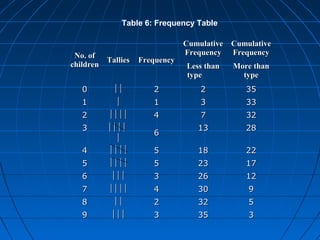

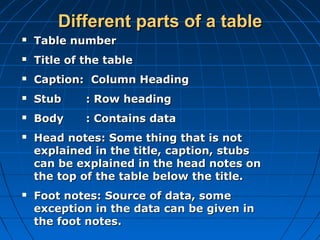

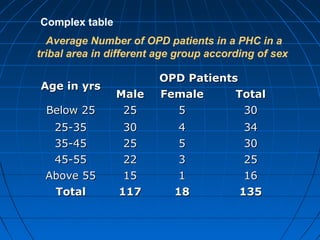
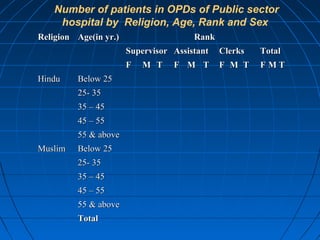




This document provides an overview of classifying and tabulating data. It discusses concepts like variables, frequency distributions, and principles of data classification. The objectives of classification are to condense large amounts of data to reveal patterns and enable statistical analysis. Different parts of tables and types of tables are also described. Frequency distributions summarize how observations are distributed across classes.





























































































