Downloaded 810 times



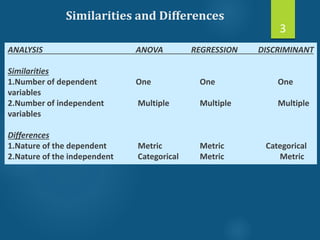









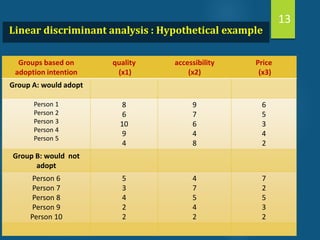
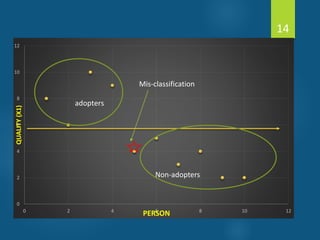
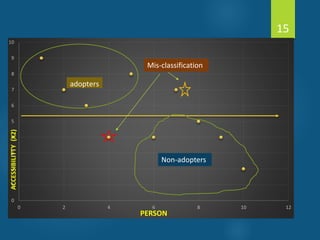
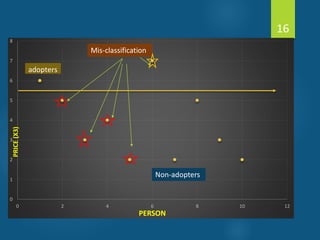
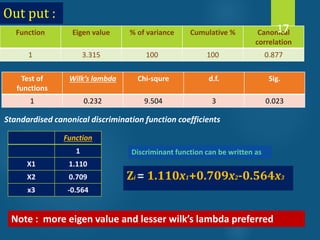




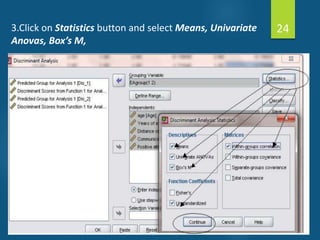
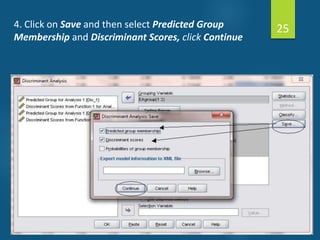
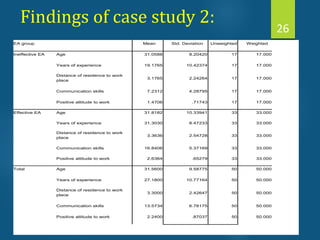
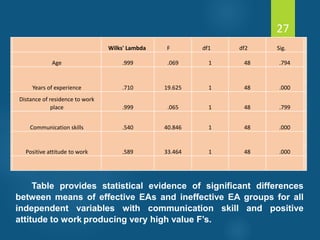



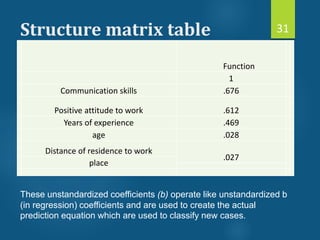








- Discriminant analysis is a statistical technique used to discriminate between two or more groups based on multiple predictor variables. - A study analyzed data on effective and ineffective extension agents to identify variables that best discriminate between the two groups. Variables like years of experience, communication skills, and positive attitude to work significantly differed between the groups. - Discriminant analysis generated a function to maximize differences between the groups based on predictor variables. The function was statistically significant based on a small Wilks' lambda value, indicating most variability was explained.










































































