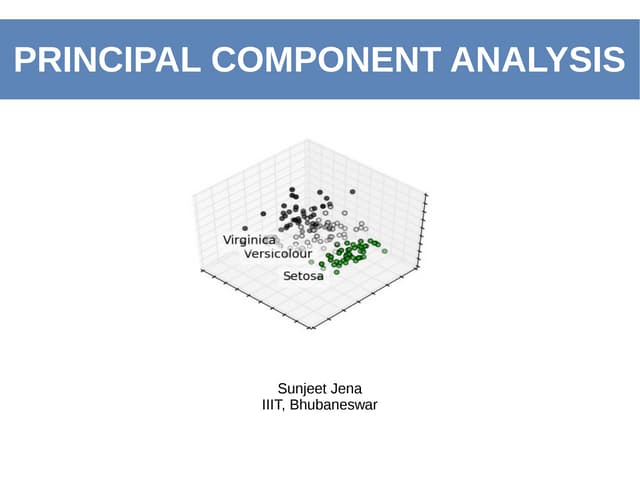
Cluster analysis is an unsupervised machine learning technique that groups unlabeled data points into clusters based on similarities. It aims to divide data into meaningful groups (clusters) where items in the same cluster are more similar to each other than items in different clusters. The document discusses different types of cluster analysis methods including hierarchical agglomerative clustering which starts with each data point as its own cluster and merges them together based on similarity, and k-means clustering which partitions data into k mutually exclusive clusters where each observation belongs to the cluster with the nearest mean. It also covers topics like distance measures, selecting the optimal number of clusters, and limitations of cluster analysis techniques.