Download to read offline






![GAUSS-JORDAN SOLUTION TO SYSTEMS OF LINEAR EQUATIONS
PURPOSE:
CONVENTION:
SUBROUTINE:
METHOD:
REFERENCE:
SOURCE:
Find the solution to the system of linear
equations given in the form of an augmented
matrix A such that
A = [B I u I]
The coefficients of matrix B, the vector u
and the identity matrix I are given as
arguments to both the programs.
None.
Let the starting array be the n by (n+m)
augmented matrix A, consisting of an n by n
coefficient matrix with m appended columns.
Let k = 1,2, ... ,n be the pivot counter, so
that akk is the pivot element for the kth pa~s
of the reduction. It is understood that the
values of the elements of A will be modified
tluring computation_ by the follow algorithm
ak;
akj + -'-"'L for j = n+m,n+m-1, •.• ,k
akk
aij + aij - aikakj for j = n+m,n+m-1, ••• ,k
and i = 1,2, ••• ,n (i~k) and k = 1,2, •.• ,n
Brice Carnahan, Applied Numerical Methods,
John Wiley and Sons, 1969
FORTRAN, Glen B. Alleman, u.c. Irvine
APL, VEG IB MAT (GENERIC FUNC7'JON)
RUNGA-KUTTA SOLUTION TO ORDINARY DIFFERENTIAL EQUATIONS
PURPOSE:
CONVENTION:
USE:
Integrate a given differential equation
of the form
~ = f(x,y)
using the Runga-Kutta technique.
The ordinary differential equation
~ = f(x,y)
with the initial condition
is solved numerically using the fourth-
order Runga-Kutta integration process.
This is a single step method in which the
value of y at x xn is used to compute
The equation to be integrated must be provided
by the user along with the initial conditions
and the step increment.
SUBROUTINES: FORTRAN, FUN - user defined function containing
the function to be integrated.
APL, FUN - same as above.
METHOD: Given the formula
where for a given step size h
12](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-7-320.jpg)




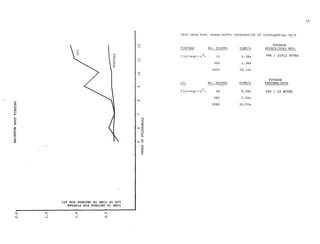
![0
""
z0
H
E-t
(.)
::::>
n
!il
~p:;
0,..,
I
CJ)
CJ)
::::>
(]
SGN0;)3:S NI :iIWI.L
0
rl
"'.-4
""'rl
N
.-4
0
rl
x
H
p:;
8
~CX)
I><
0
~
N
H
CJ)
"'
17
TEST DATA FOR: BAIRSTOW ROOT FINDING METHOD
STORAGE
FORTRAN DEGREE OF POLY. TIME/s SOURCE/LOAD MOD.
5th 0.36s 10118 I 23040 BYTES
6th 0.37s
7th 0.35s
8th 0.37s
9th 0.40s
!10th 0.40s
11th 0.44s
12th 0.45s
STORAGE
APL DEGREE OF POLY. TIME/s PROGRAM/DATA
5th l. 93s 2436 / 4*0RDER BYTES
6th 2.BOs
7th 2.25s
8th 2.53s
9th 7.28s
10th 4.!0s
11th l0.60s
12th 12.27s](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-12-320.jpg)




![implementation is called for to provide faster
execution of programs requiring looping structures.
3) Although APL provides a fast, easy to code, means
of solving scientific problems, its ease of use and
code density are traded for execution time in
"number-crunching" problems found in physics and
engineering. For example the solid state physicist
solving 150 x 150 eigenvalue problems on an every-
day basis.
Although these tests point out that APL, in its present
form, is not competitive with .a c.ompilec;l _FORTRAN program,
there are indications that it could be. With the addition
of a differential equation function, an increase in work-
space size (maybe even virtual workspaces), and a speed up
in execution time for looping structures, the language will
be able to provide cost effective solutions to the types of
problems to whieh its notation is so well suited.
APL LISTING FOR LAPLACE'S EQUATION
'lLAP((J]'l
'V Z+F LAP A;C
[1] C+(Z+A)x-F
[2] ~2•E<f/I ,A-Z+C+0.25xFx(1~A)+(1eA)+-1eA+Z
v](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-18-320.jpg)
![APL LISTING FOR ROMBERG INTEGRATION OF FOURIER COEFFICIENTS
"lFOURIER[J] V
V F'OURIER;Q;A;B;SW;N;/l
[ l] A+B+( 11+M+SW+O )p0><6IO ,O
[ 2 J SW<- IxA[M]+RHO/.! 8
[3] ->(10"11+S:t<-OxB[M+N+1]+RHOl1 $)p2
[4] lpLF
[SJ N+xpP.-11pO
[6] 'FOURIER ANALYSIS USING RHOMBERG INTEGRATION' ,(2+N+1)pLF
(7] '1!lA( 0) = l!l,M'.H!lF12.8' llF!O A[O]
[8) '1!lA[l!l,I2,i!JJ = l!l,M!l-l!!P12,8,[!] B[i!J,12,!l) = !'.l,M.!l-i!JF12.B' AFMl'(N;A[N];N
;B[N])
[9] +(10~N+N+1)p8
[10] '1!JA[10] = l!l,M!l-l!!F12.8' liFMr A[10]
[11] Q+SJ:0,1
v
APL LISTING FOR FOURIER COEFFICIENTS CONTINUED
VRHOl!('J]V
'I Z+PJIOM ll;Q..;NAT;I;//
[ 1] IJAT+( 2p/l)pK+OxJ.-1,0p6IO ,1
[2] M4T[1;I]+(2•I) TRAP2 &.~
[3] +{l/<:I+I+l )p2
[4] I<-1
[SJ MAT[I+1; 1pK]+K+( ( ( 4•I)x( H( ·I-1 ).1-MAT[I;]} )-CH( -I-1 )HIAT[I;]) )t
-1+4•I
[6) -+SX/l>I+l+l
[7) Q<-5I0,0,0pZ+i1AT[N;l]
v
VTRAP2[0JV
V .Z+N T!MP2 L;DX
(1) X+L(l]+O,(IN)xDX+(•/L(2 1])tll,Op6I0,1
(2) +3+(SW=1),0p6I0,1
[3] +O,Z+(DXt2)><(1,((ll-1)p2),1)+.xrA
(II J Z+(DXt2)><( 1,((11·1)p2),1 )+, ><ri!
v
2](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-19-320.jpg)
![APL LISTING FOR FOURIER COEFFICIENTS CONTINUED
V£'.A[O]V
V Z+lA
[1] Z+((Q X)x(loMxX))+ol
v
Vl/:l[OJV
v Z+l/:1
[1] Z+((g X)x(2oMxX))to1
v
11 {i IS THE FUNCTION USED TO GENERATE THE FUNCTIONAL POINTS
11 USED IN THE FOURIER ANALYSIS
APL LISTING FOR SOLUTIONS TO LINEAR SYSTEMS OF EQUATIONS
RESULT,,.VEC'l'OF~HATRIX](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-20-320.jpg)
![26
APL LISTING FOR HUNGE-KUTTA DIFFERENTIAL EQUA1'IONS APL LISTING FOR JACOBI 1
S EIGENVALUE METHOD
7~'IC1L])17
[2] /+,V[c]
[3] I;.JOP:.':1+V[3]x(Y. "'U.c' Y) C3] P<-I
[4] '.'.2+V[3]x((;'.i-V[3)t2) FV:V(YtJ'.H2))
[SJ K3+V[3Jx((XtVl3]t2) I'Uil(Yi-K2t2))
K4<-;r[3]x((X+V[3]t2} !"Vi.'(Y+K3)} [ 5] V+F+ .. xP
[7] Y+Y+(:'.H(2xX2 h( 2xY..2 )-+K4 )IC
(6} -•((C[2]~,'/+l/+1),v/E[1]<, JTxA+(IS/I')+,xA<t.<I')/ 0 2
[8] ~('l[4]<X+X+V[3])/0
~7] ;;+V,(1] 1 1 ~
[g] X,[1.5) J
[10] ->LOOP
[il) A X+!t1); y+V(2); INCRE/iE?'!'i'+'f.3]; FINIAL VALU.0<-'[4]](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-21-320.jpg)
![APL LISTING FOR BAIRSTOW'S ROOT FINDING METHOD
VBAIR[J)V
V A BAIR Z;//;E:;l-:;P;U;!J
[1] -. o 5 4 2[1++/ O 1 2 <l/+pA+HAt1pA,E+1pZ,P+-(1+11<-0)+Z]
[2) -+( ( 100=M+U+1) ,E<+l IUxppP+PTU+C2tB )[fl 2 2 pl<j>(Jt<j>P S -HB )-3t1t-2+B+
2+P 3 A)/ 6 2
[3) ->((1=l/),%1/+N-2)/5,pP+HZ,OpA+-2fB,1/J+;JlJ+P[1] Q P[2]
[4] ->p[}+-A[1] Q A[2]
[SJ --0,p[}+- 1 1 p-A[1]
[6] 'SLOW OR NOll·CONVERGENCE'
"
REFERENCES
(l] Breed, L.M. and Lathwell, R.H., "The Implementation of
APL360" Interactive Systems for Applied Mathematics,
1968, Academic Press, New York, pp. 390-399.
(2] Foster, G.H., "Some Cost Comparsions Between APL and
FOR'l'RAN", Share XXXIX Conference, Toronto, Canada,
August 10, 1972](https://image.slidesharecdn.com/atimestudyinnumericalmethodsprogramming-170227013355/85/A-time-study-in-numerical-methods-programming-22-320.jpg)

This document evaluates the effectiveness of APL and Fortran programming languages in solving numerical analysis problems via a comparative study. It addresses several key questions regarding execution speed, code density, usability for novice programmers, and cost-effectiveness of both languages in scientific programming. The study's findings suggest distinct performance trends, though results remain inconclusive and warrant further exploration in numerical computing.








































































































