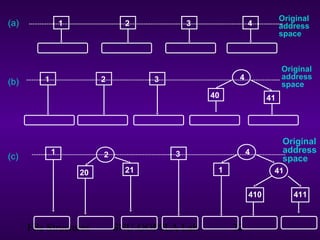
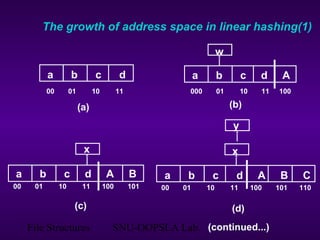
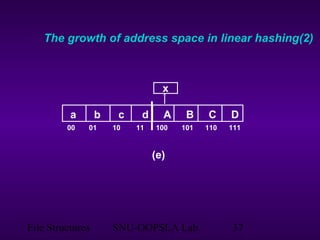
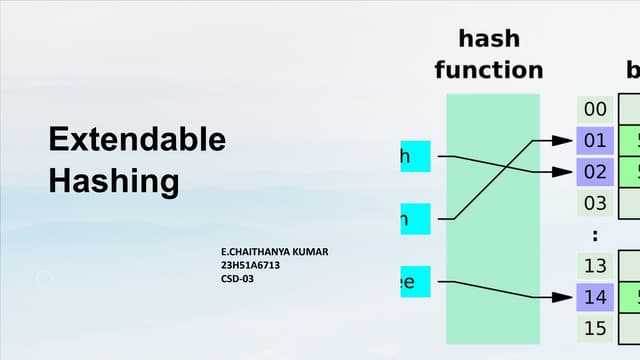
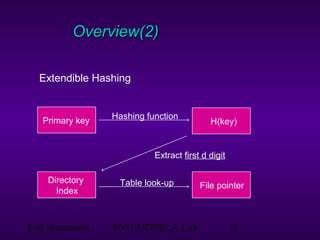
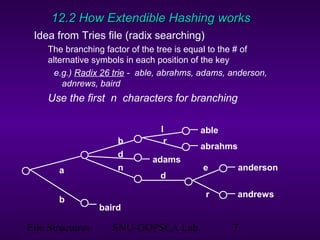
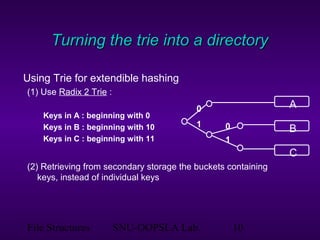
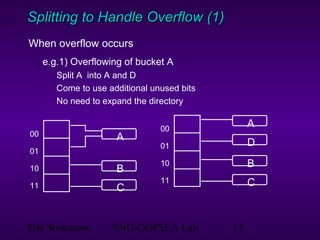
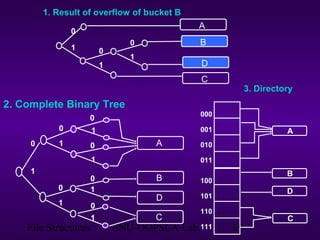
This document discusses extendible hashing, which is a hashing technique for dynamic files that allows efficient insertion and deletion of records. It works by using a directory to map hash values to buckets, and dynamically expanding the directory size and number of buckets as needed to accommodate new records. When a bucket overflows, it is split into two buckets, and the directory is expanded to distinguish them. The directory size can also be contracted when buckets can be combined due to deletions. Alternative approaches like dynamic hashing and linear hashing that address the same problem of dynamic files are also overviewed.
















![File Structures SNU-OOPSLA Lab. 21
Int Hash (char * key)
{
int sum = 0;
int len = strlen(key);
if (len % 2 == 1) len ++; // make len even
for (int j = 0; j < len; j+2)
sum = (sum + 100 * key[j] + key[j+1]) % 19937;
return sum;
}
Figure 12.7 Function Hash (key) returns an integer hash value for key
for a 15 bit](https://image.slidesharecdn.com/4-150507102003-lva1-app6891/85/4-4-external-hashing-21-320.jpg)