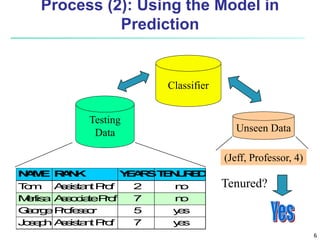
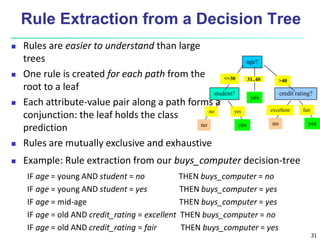
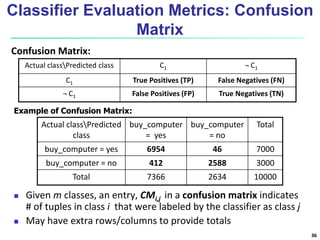
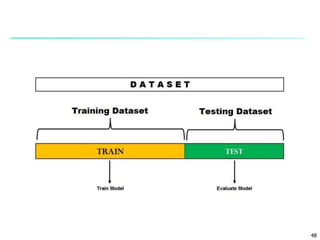
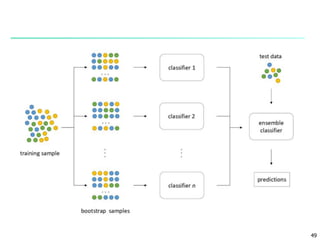
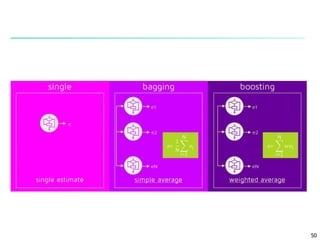
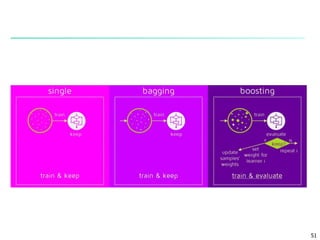
The document discusses classification techniques for supervised learning problems. It describes classification as predicting categorical class labels based on a training set of labeled data. The classification process involves constructing a model from the training set and then using the model to classify new unlabeled data. Common classification techniques discussed include decision tree induction, Bayesian classification methods, and rule-based classification. Model evaluation and techniques for improving accuracy, such as ensemble methods, are also covered.