Download to read offline



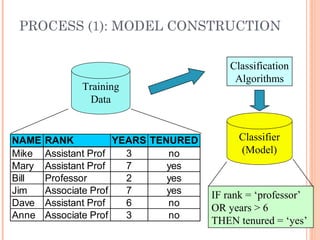



























This document discusses classification and prediction in machine learning. It defines classification as predicting categorical class labels, while prediction models continuous values. The key steps of classification are constructing a model from a training set and using the model to classify new data. Decision trees and rule-based classifiers are described as common classification methods. Attribute selection measures like information gain and gini index are explained for decision tree induction. The document also covers issues in data preparation and model evaluation for classification tasks.



















































































