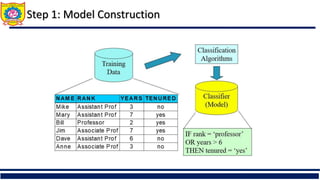
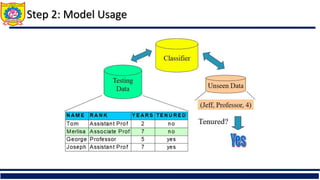
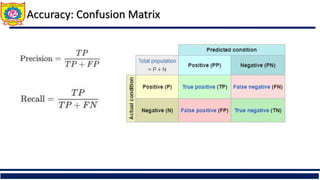
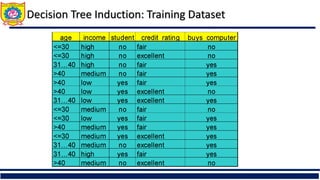
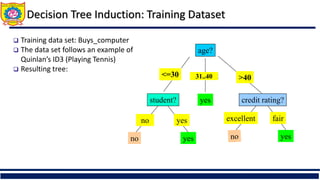
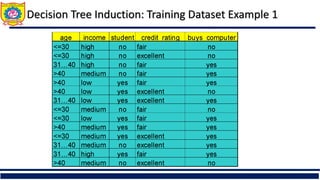
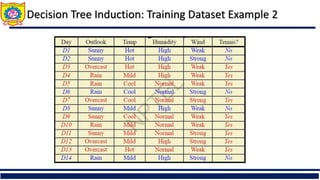
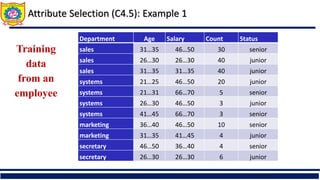
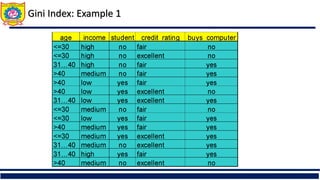
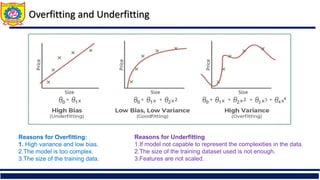
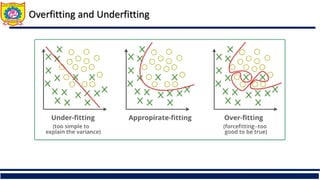
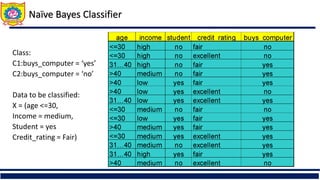
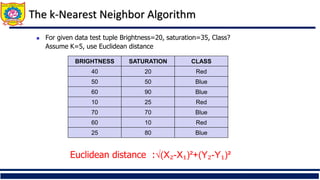
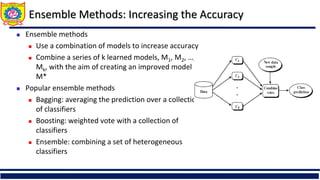
The document discusses the principles of classification in data mining and warehousing, focusing on supervised learning methods including decision trees, naive Bayesian classification, and ensemble methods. It outlines processes for model construction and usage, evaluates classification methods based on accuracy, and addresses issues of overfitting and underfitting in decision trees. It also highlights various attribute selection measures and their application in constructing effective classification models.