Download to read offline





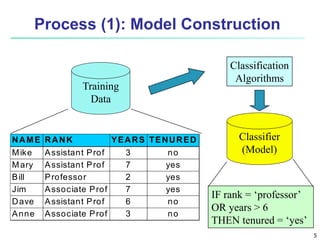
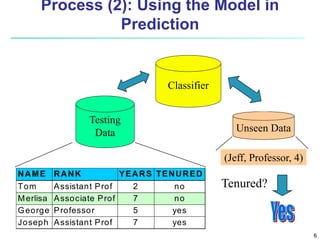

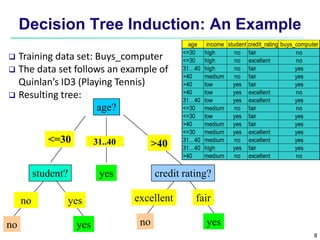



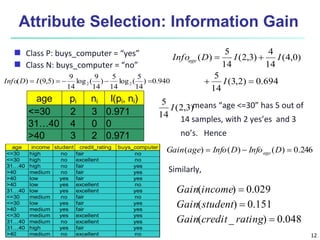






















This document provides an overview of classification techniques in machine learning. It discusses: - The process of classification involves model construction using a training set and then applying the model to classify new data. - Supervised learning aims to predict categorical labels while unsupervised learning groups data without labels. - Popular classification algorithms covered include decision trees, Bayesian classification, and rule-based methods. Attribute selection measures, model evaluation, overfitting, and tree pruning are also discussed.


























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







