Downloaded 605 times


![3/1/2012
2. Basic Algorithm
Decision Tree Algorithms
• ID3 algorithm
• C4.5 algorithm
- A successor of ID3
– Became a benchmark to which newer supervised learning
algorithms are often compared.
– Commercial successor: C5.0
• CART (Classification and Regression Trees) algorithm
– The generation of binary decision trees
– Developed by a group of statisticians
6
Basic Algorithm
• Basic algorithm ,[ID3, C4.5, and CART], (a greedy algorithm)
– Tree is constructed in a top-down recursive divide-and-
conquer manner
– At start, all the training examples are at the root
– Attributes are categorical (if continuous-valued, they are
discretized in advance)
– Examples are partitioned recursively into smaller subsets as
the tree is being built based on selected attributes
– Test attributes are selected on the basis of a statistical
measure (e.g., information gain)
7
3](https://image.slidesharecdn.com/decisiontreelecture3-120301111900-phpapp02/75/Decision-tree-lecture-3-3-2048.jpg)


![3/1/2012
• For example, suppose S is a collection of 25 examples, including 15
positive and 10 negative examples [15+, 10-]. Then the entropy of
S relative to this classification is :
Entropy(S) = - (15/25) log2 (15/25) - (10/25) log2 (10/25) = 0.970
• Notice that the entropy is 0 if all members of S belong to the same
class. For example,
Entropy(S) = -1 log2(1) - 0 log20 = -1 0 - 0 log20 = 0.
• Note the entropy is 1 (at its maximum!) when the collection
contains an equal number of positive and negative examples.
• If the collection contains unequal numbers of positive and
negative examples, the entropy is between 0 and 1. Figure 1
shows the form of the entropy function relative to a binary
classification, as p+ varies between 0 and 1. 12
Figure 1: The entropy function relative to a binary classification, as the proportion of positive
examples pp varies between 0 and 1.
Entropy of S = Info(S)
-The average amount of information needed to identify the class label of an
instance in D.
- A measure of the impurity in a collection of training examples
- The smaller information required, the greater the purity of the partitions.
13
6](https://image.slidesharecdn.com/decisiontreelecture3-120301111900-phpapp02/75/Decision-tree-lecture-3-6-2048.jpg)

![3/1/2012
• In this dataset, there are five categorical attributes outlook, temperature,
humidity, windy, and play.
• We are interested in building a system which will enable us to decide
whether or not to play the game on the basis of the weather conditions, i.e.
we wish to predict the value of play using outlook, temperature, humidity,
and windy.
• We can think of the attribute we wish to predict, i.e. play, as the output
attribute, and the other attributes as input attributes.
• In this problem we have 14 examples in which:
9 examples with play= yes and 5 examples with play = no
So, S={9,5}, and
Entropy(S) = info (S) = info([9,5] ) = Entropy(9/14, 5/14)
= -9/14 log2 9/14 – 5/14 log2 5/14 = 0.940
16
consider splitting on Outlook attribute
Outlook = Sunny
info([2; 3]) = entropy(2/5 ; 3/5 ) = -2/5 log2 2/5
- 3/5 log2 3/5 = 0.971 bits
Outlook = Overcast
info([4; 0]) = entropy(4/4,0/4) = -1 log2 1 - 0 log2 0 = 0 bits
Outlook = Rainy
info([3; 2]) = entropy(3/5,2/5)= - 3/5 log2 3/5 – 2/5 log2 2/5 =0.971 bits
So, the expected information needed to classify objects in all sub trees of the
Outlook attribute is :
info outlook (S) = info([2; 3]; [4; 0]; [3; 2]) = 5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971
= 0.693 bits
information gain = info before split - info after split
gain(Outlook) = info([9; 5]) - info([2; 3]; [4; 0]; [3; 2])
= 0.940 - 0.693 = 0.247 bits
17
8](https://image.slidesharecdn.com/decisiontreelecture3-120301111900-phpapp02/75/Decision-tree-lecture-3-8-2048.jpg)
![3/1/2012
consider splitting on Temperature attribute
temperature = Hot
info([2; 2]) = entropy(2/4 ; 2/4 ) = -2/4 log2 2/4 - 2/4 log2 2/4 =
= 1 bits
temperature = mild
info([4; 2]) = entropy(4/6,2/6) = -4/6 log2 4/6 - 2/6 log2 2/6 =
= 0.918 bits
temperature = cool
info([3; 1]) = entropy(3/4,1/4)= - 3/4 log2 3/4 – 1/4 log2 1/4 =0.881 bits
So, the expected information needed to classify objects in all sub trees of the
temperature attribute is:
info([2; 2]; [4; 2]; [3; 1]) = 4/14 * 1 + 6/14 * 0.981 + 4/14 * 0.881= 0.911 bits
information gain = info before split - info after split
gain(temperature) = 0.940 - 0.911 = 0.029 bits
18
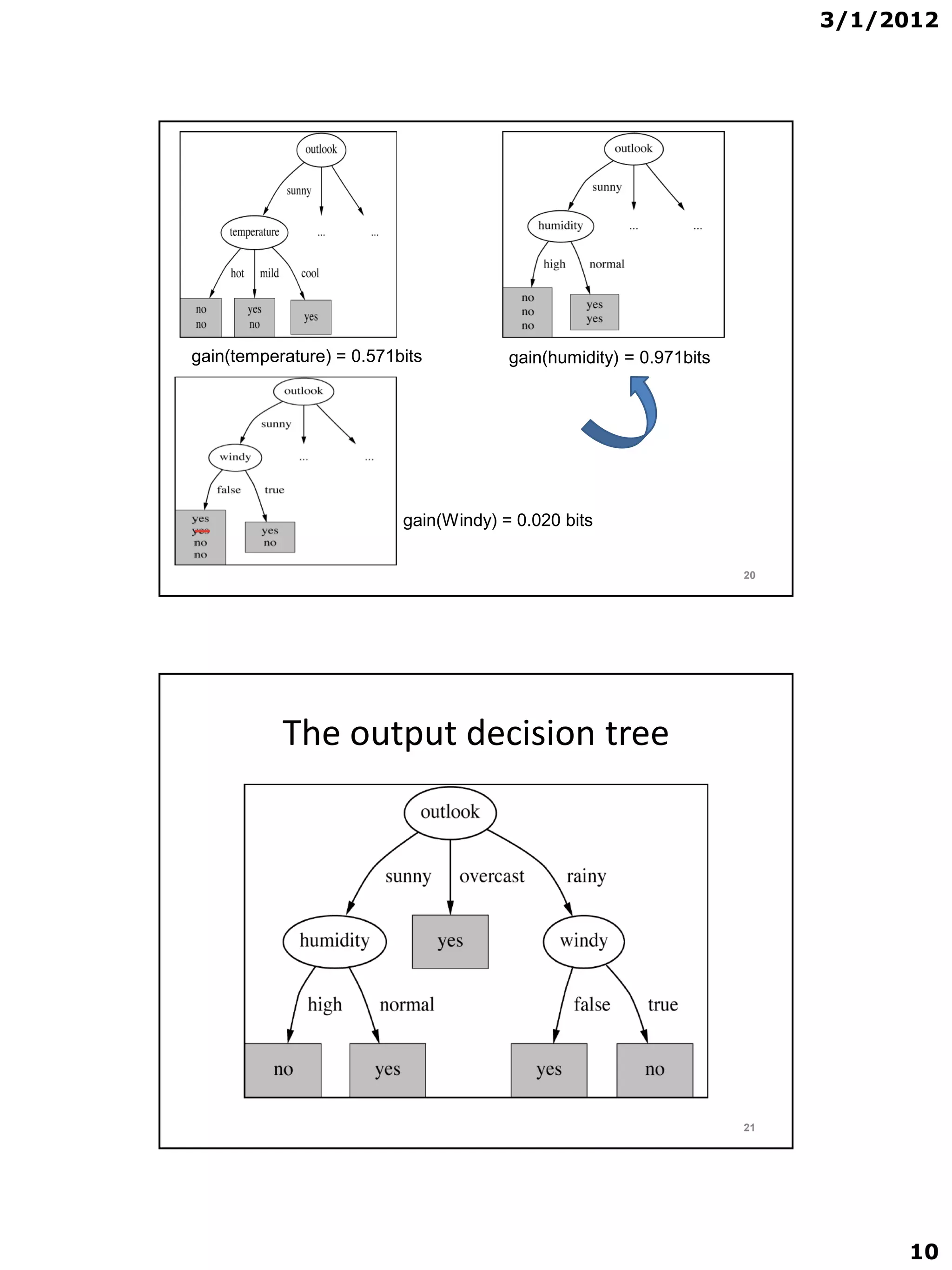
• Complete in the same way we get:
gain(Outlook ) = 0.247 bits
gain(Temperature ) = 0.029 bits
gain(Humidity ) = 0.152 bits
gain(Windy ) = 0.048 bit
• And the selected attribute will be the one with
largest information gain = outlook
• Then Continuing to split …….
19
9](https://image.slidesharecdn.com/decisiontreelecture3-120301111900-phpapp02/75/Decision-tree-lecture-3-9-2048.jpg)


The document discusses decision tree induction algorithms. It begins with an introduction to decision trees, describing their structure and how they are used for classification. It then covers the basic algorithm for constructing decision trees, including the ID3, C4.5, and CART algorithms. Next, it discusses different attribute selection measures that can be used to determine the best attribute to split on at each node, including information gain, gain ratio, and the Gini index. It provides details on how information gain is calculated.










































































