Downloaded 48 times















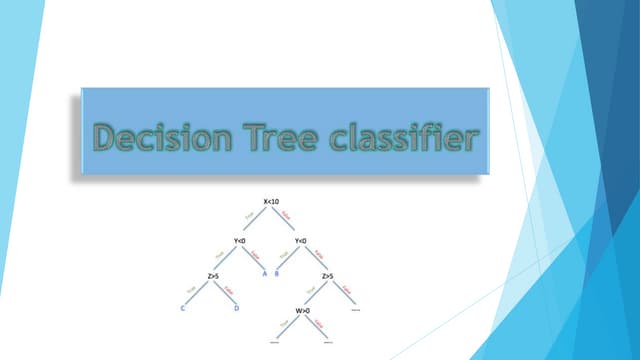
Decision trees use a tree structure to show possible consequences of decisions. A decision tree has internal nodes that represent tests of attributes, branches that represent test outcomes, and leaf nodes that represent class labels. Entropy is a measure of uncertainty in a random variable. Information gain is used to calculate the difference between entropy before and after splitting on an attribute, to determine which attribute provides the most information about the class. The attribute with the highest information gain is selected as the root node of the decision tree.