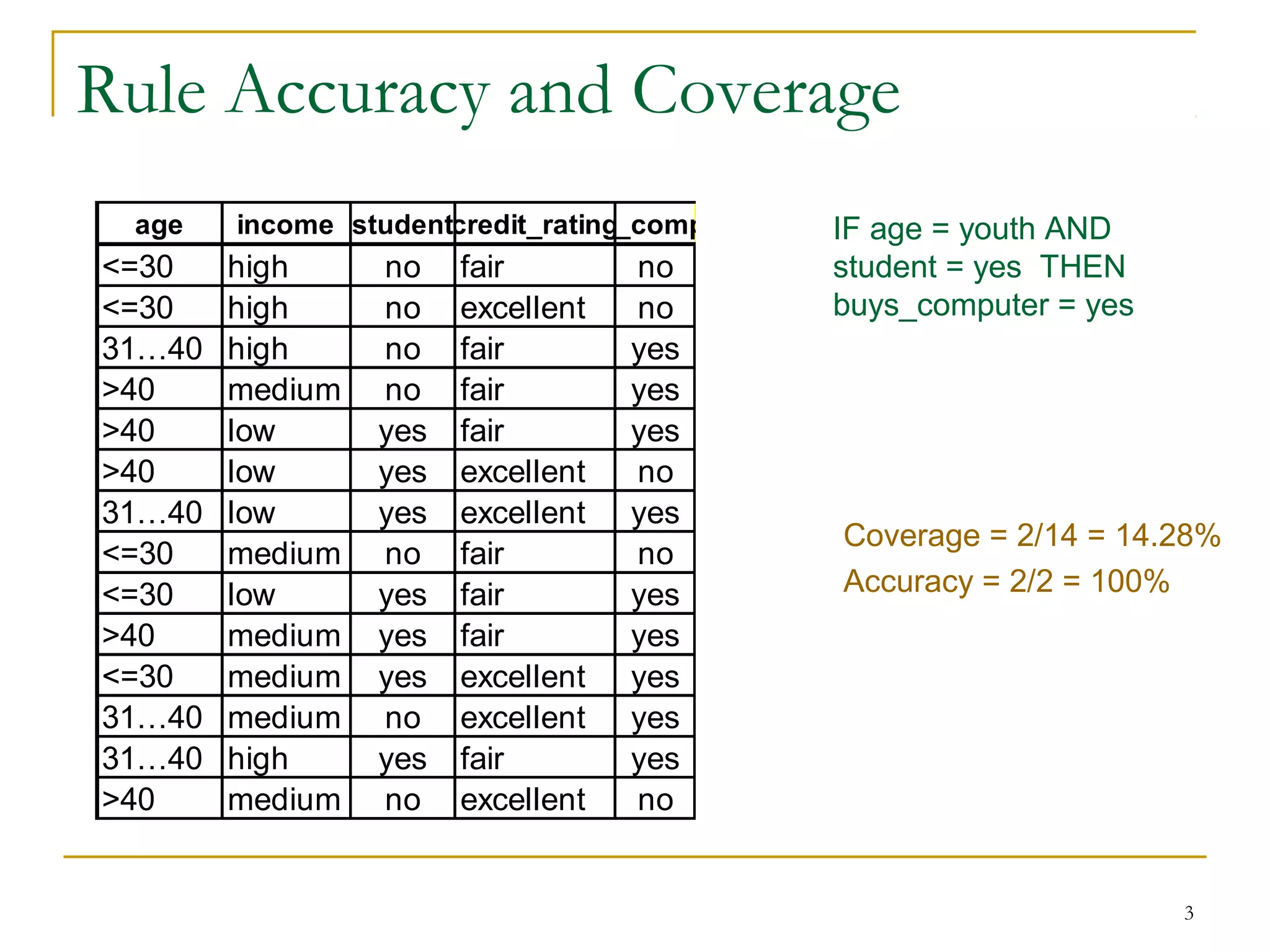
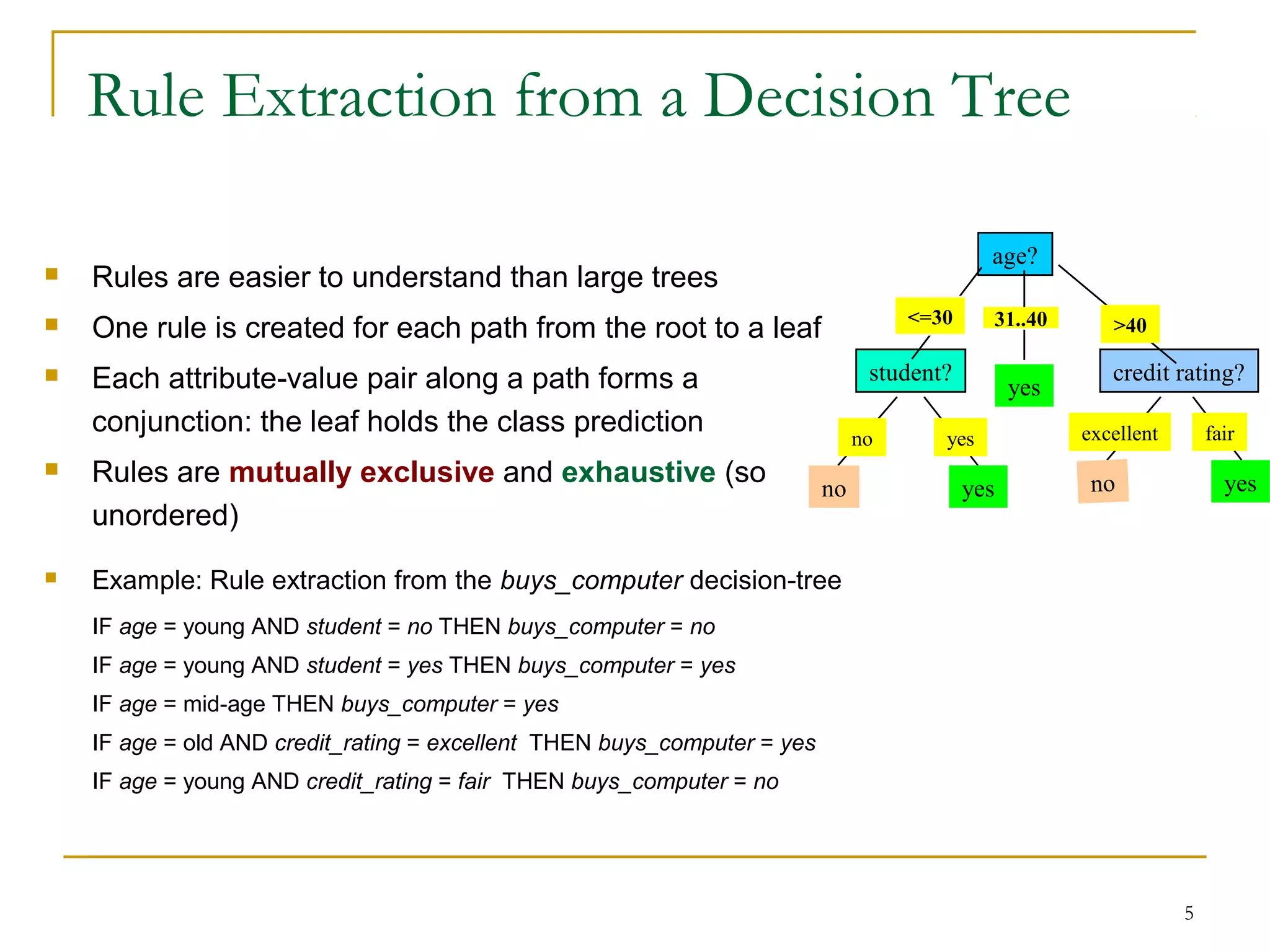
This document discusses rule-based classification. It describes how rule-based classification models use if-then rules to classify data. It covers extracting rules from decision trees and directly from training data. Key points include using sequential covering algorithms to iteratively learn rules that each cover positive examples of a class, and measuring rule quality based on both coverage and accuracy to determine the best rules.