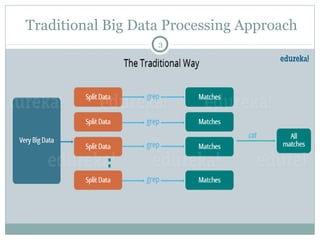
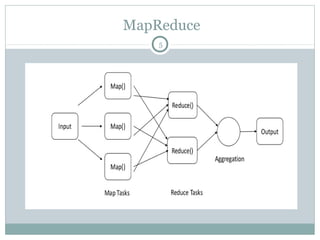
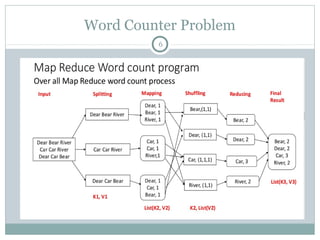
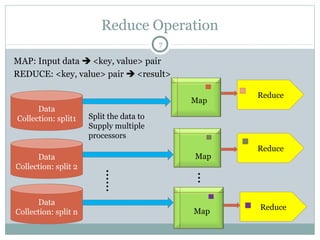
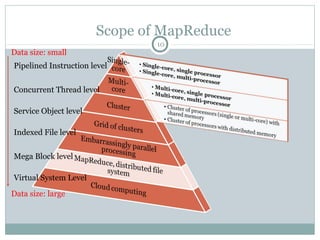
MapReduce is a programming framework that allows for distributed and parallel processing of large datasets. It consists of a map step that processes key-value pairs in parallel, and a reduce step that aggregates the outputs of the map step. As an example, a word counting problem is presented where words are counted by mapping each word to a key-value pair of the word and 1, and then reducing by summing the counts of each unique word. MapReduce jobs are executed on a cluster in a reliable way using YARN to schedule tasks across nodes, restarting failed tasks when needed.