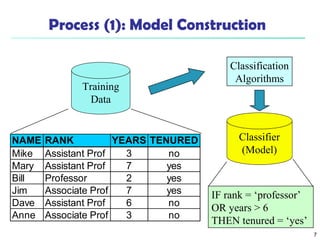
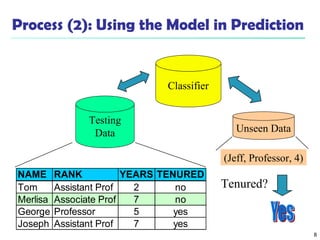
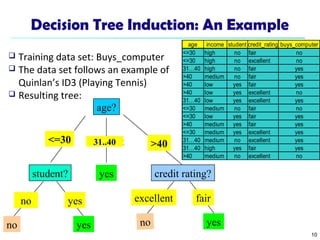
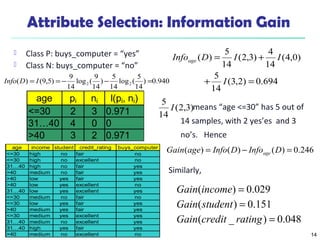
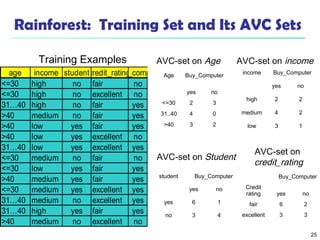
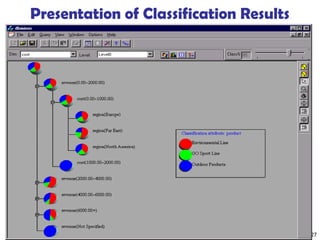
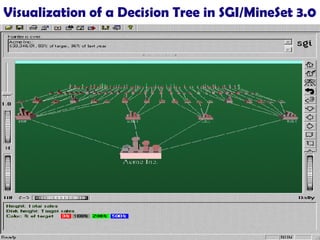
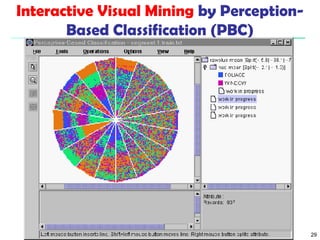
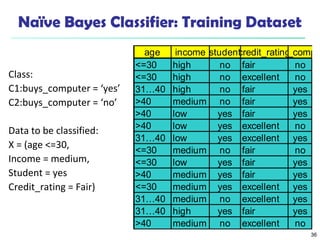
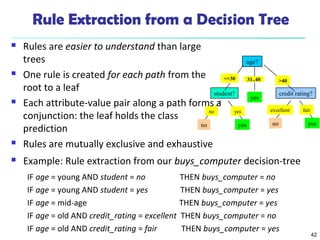
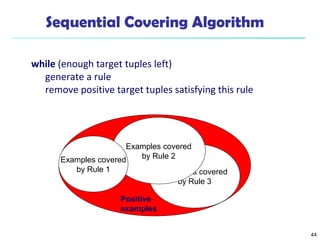
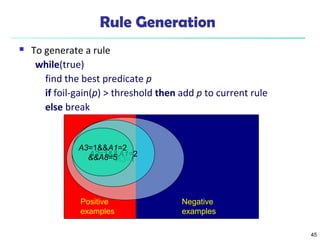
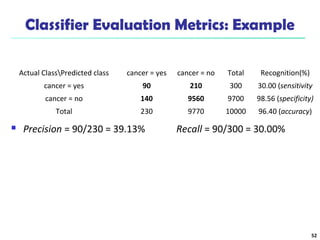
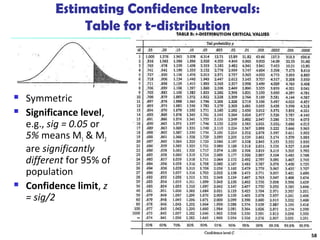
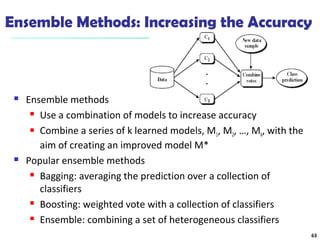
The document summarizes key concepts in classification and decision tree induction. It discusses supervised vs unsupervised learning, the two-step classification process of model construction and usage, and decision tree induction basics including attribute selection measures like information gain, gain ratio, and Gini index. It also covers overfitting and techniques like prepruning and postpruning decision trees.