Download as PDF, PPTX

![Taro L. Saito @taroleo
• 2007 University of Tokyo. Ph.D.
– XML DBMS, Transaction Processing
• Relational-Style XML Query [SIGMOD 2008]
• ~ 2014 Assistant Professor at University of Tokyo
– Genome Science Research
• Distributed Computing, Personal Genome Analysis
• March 2014 ~ Treasure Data
– Software Engineer, MPP Team Leader
• Open source projects at GitHub
– snappy-java, msgpack-java, sqlite-jdbc
– sbt-pack, sbt-sonatype, larray
– silk
• Distributed workflow engine
2](https://image.slidesharecdn.com/2015-03-11-tdtechtalk-internalsofprestoservice-150315233656-conversion-gate01/75/Internals-of-Presto-Service-2-2048.jpg)


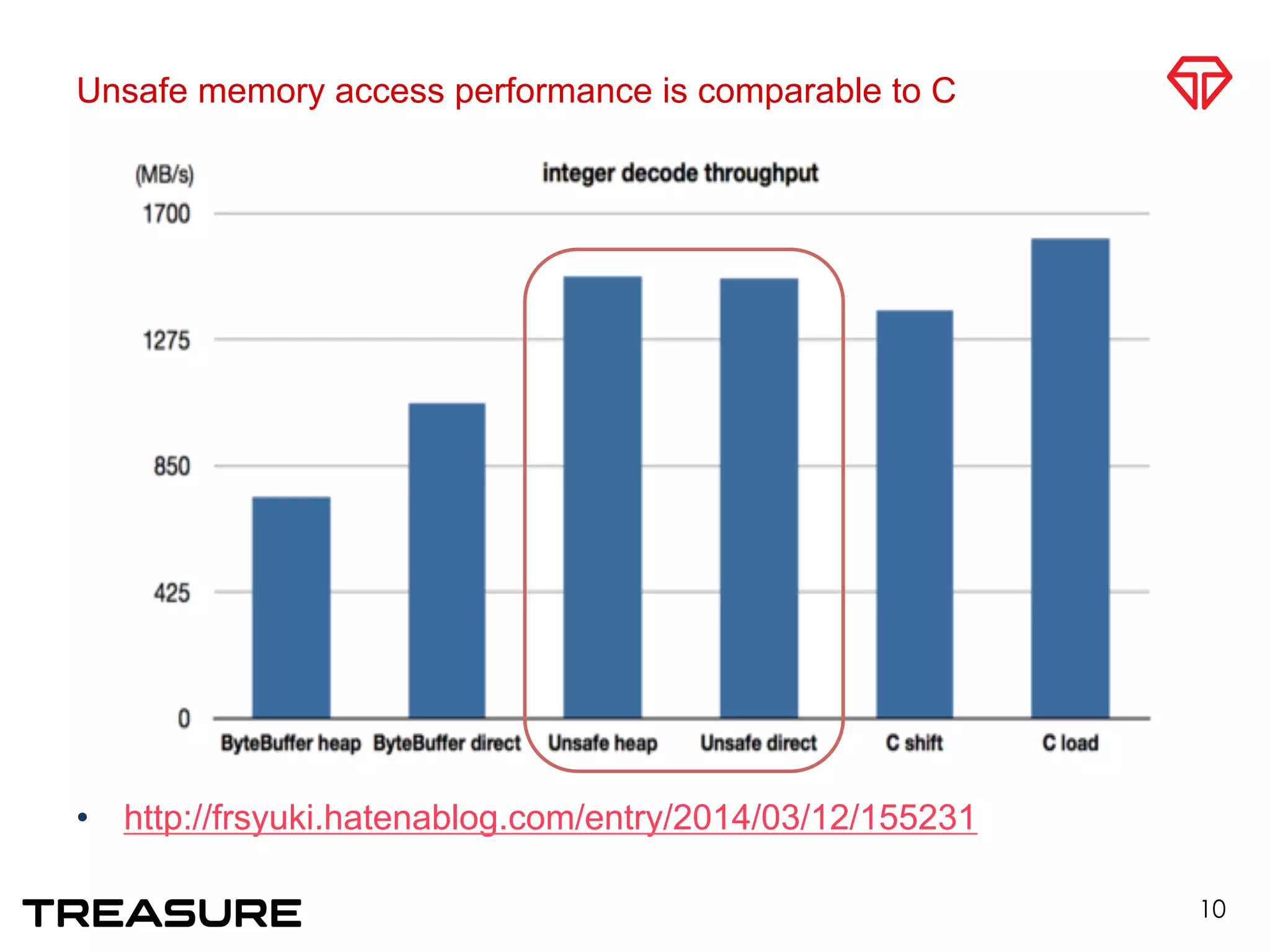
![MessageBuffer
• msgpack-java v06 was the bottleneck
– Inefficient buffer access
• v07
• Fast memory access
• sun.misc.Unsafe
• Direct access to heap memory
• extract primitive type value from byte[]
• cast
• No boxing
9](https://image.slidesharecdn.com/2015-03-11-tdtechtalk-internalsofprestoservice-150315233656-conversion-gate01/75/Internals-of-Presto-Service-9-2048.jpg)






![Challenges in Database as a Service
• Tradeoffs
– Cost and service level objectives (SLOs)
• Reference
– Workload Management for Big Data Analytics. A. Aboulnaga
[SIGMOD2013 Tutorial]
19
Run each query set
on an independent
cluster
Run all queries
together on the
smallest possible
cluster
Fast
$$$
Limited performance guarantee
Reasonable price](https://image.slidesharecdn.com/2015-03-11-tdtechtalk-internalsofprestoservice-150315233656-conversion-gate01/75/Internals-of-Presto-Service-19-2048.jpg)


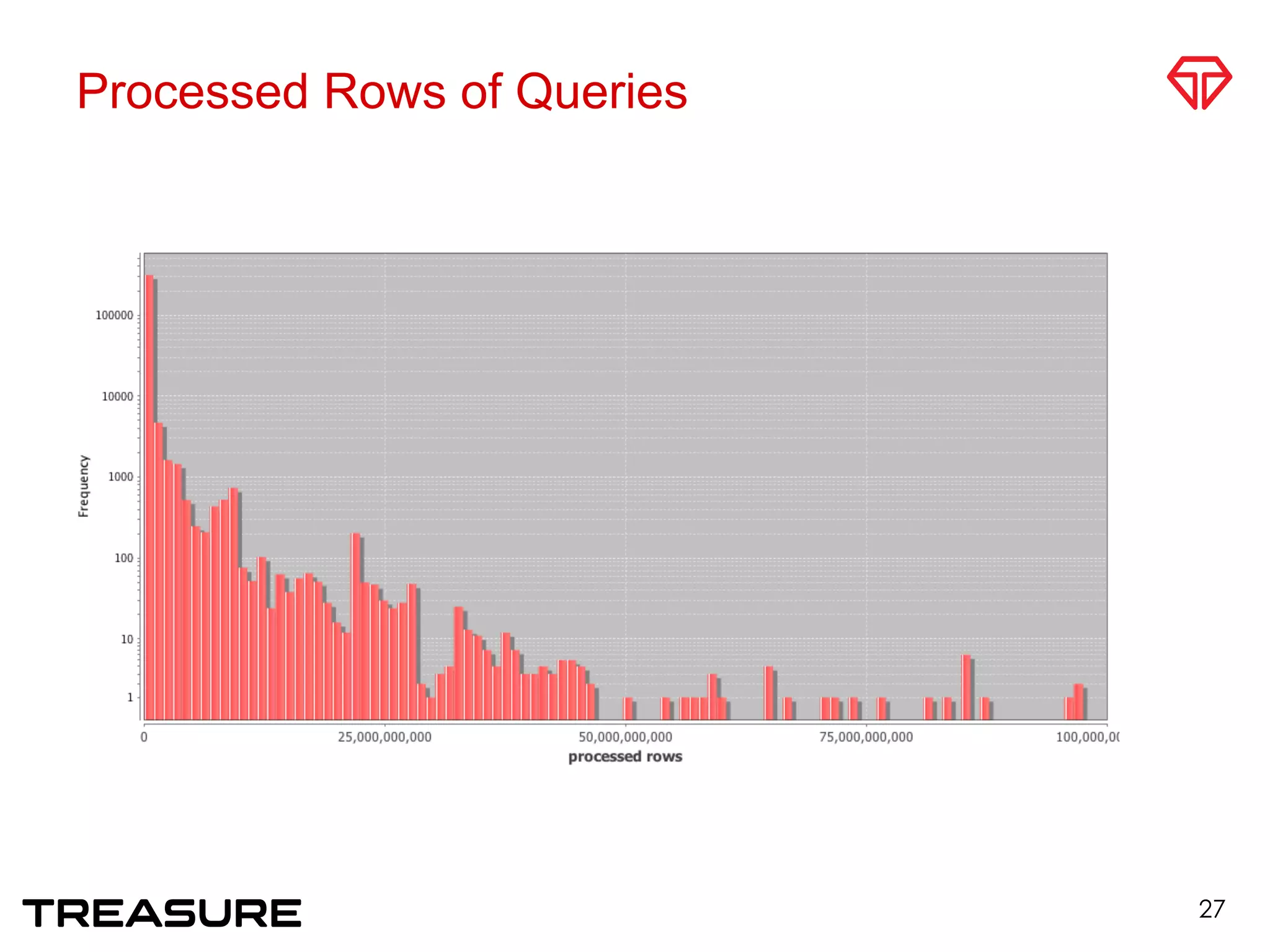
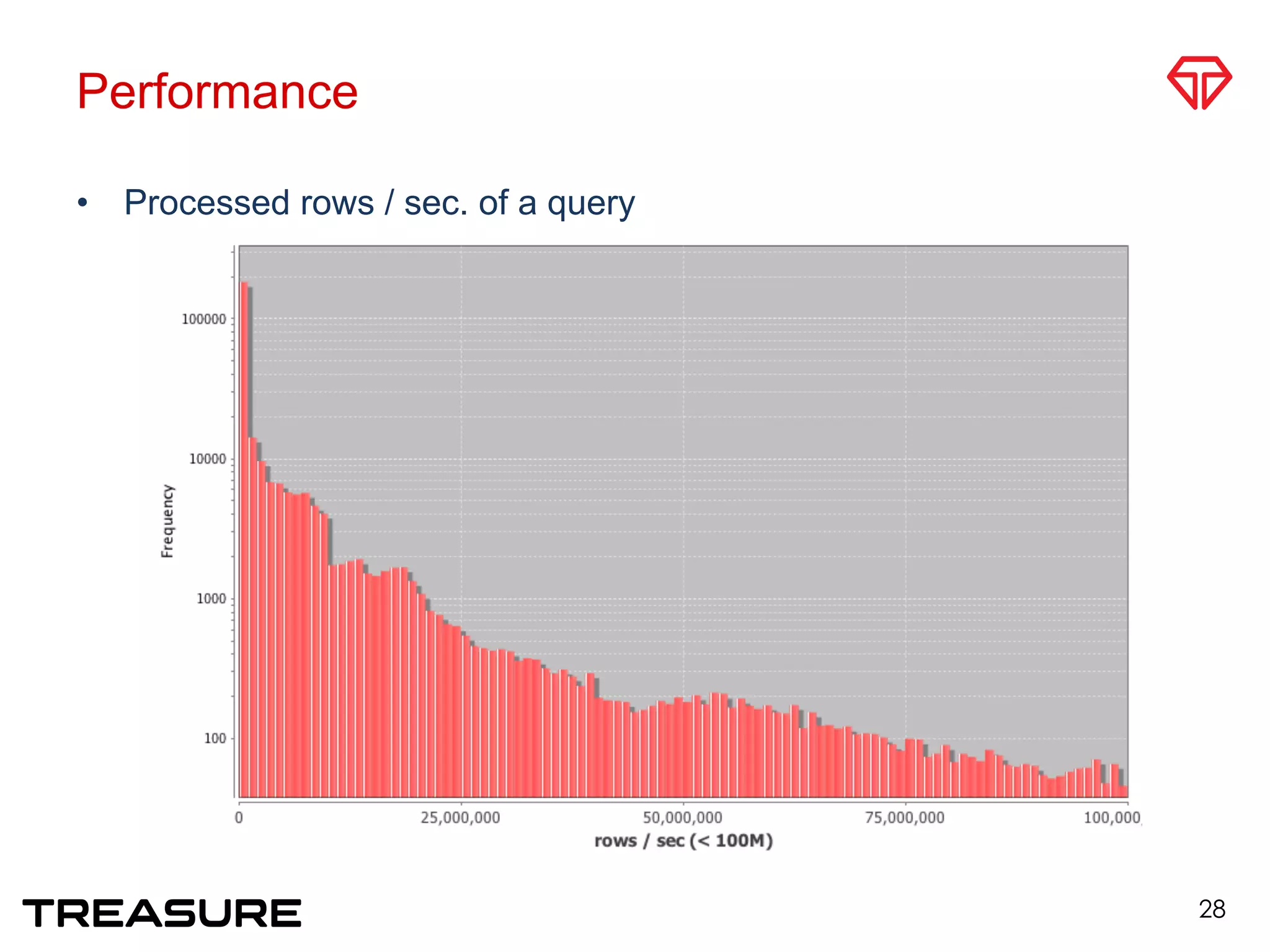
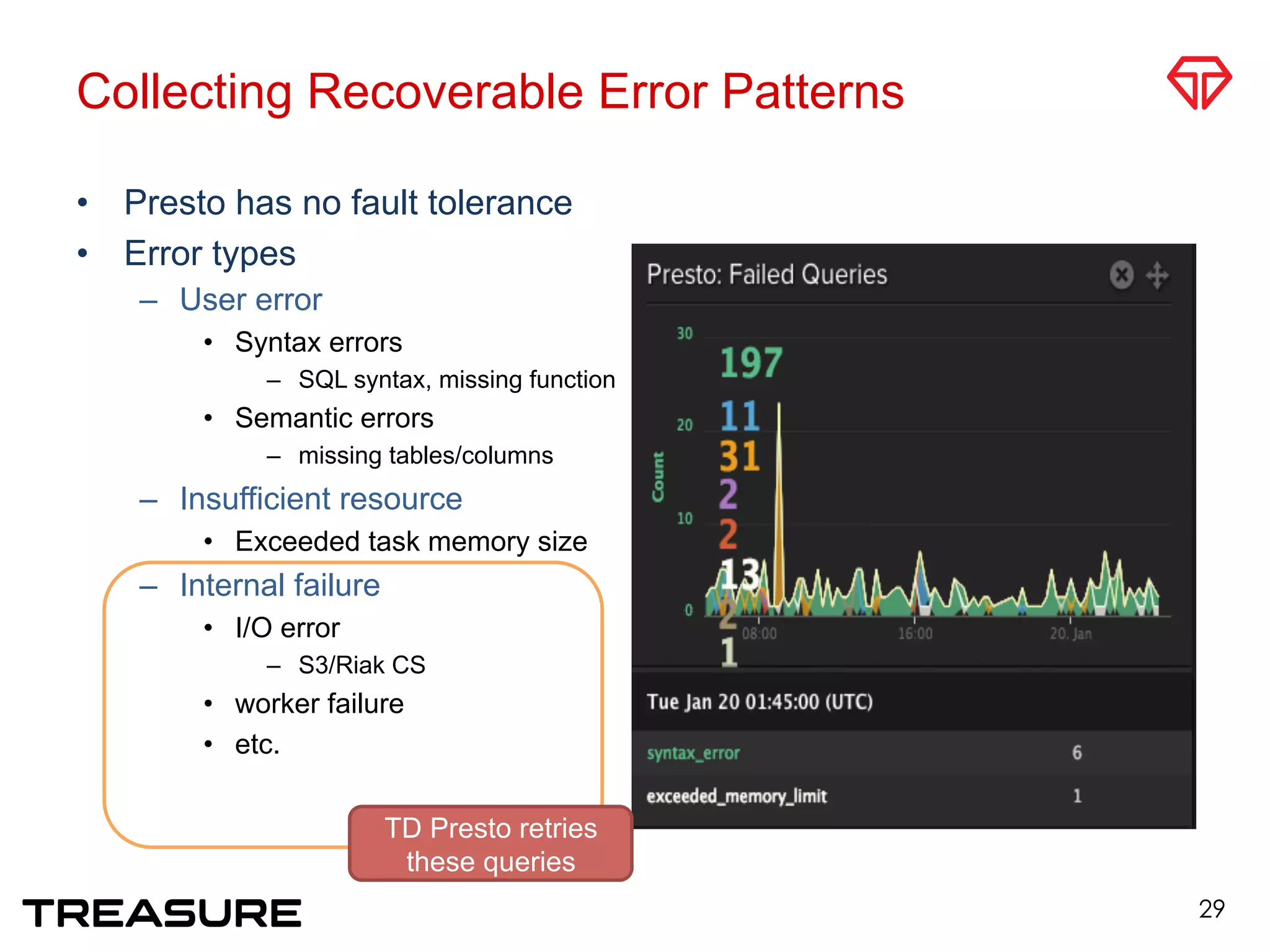
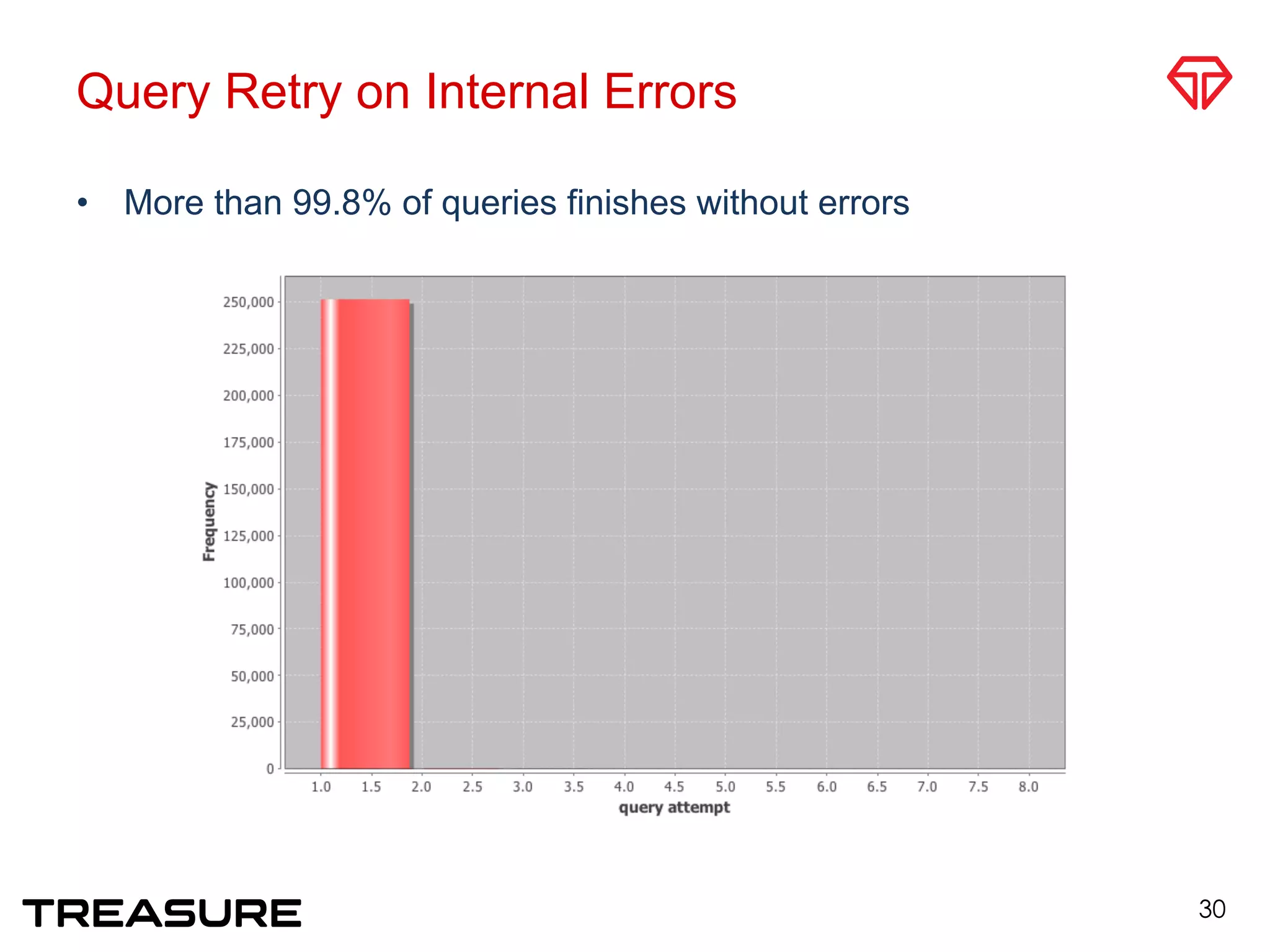



![Typical Query Patterns [Li Juang]
• Q: What are typical queries of a customer?
– Customer feels some queries are slow
– But we don’t know what to compare with, except scheduled queries
• Approach: Clustering Customer SQLs
• TF/IDF measure: TF x IDF vector
– Split SQL statements into tokens
– Term frequency (TF) = the number of each term in a query
– Inverse document frequency (IDF) = log (# of queries / # of queries that
have a token)
• k-means clustering
– TF/IDF vector
– Generates clusters of similar queries
• x-means clustering for deciding number of clusters automatically
– D. Pelleg [ICML2000]
37](https://image.slidesharecdn.com/2015-03-11-tdtechtalk-internalsofprestoservice-150315233656-conversion-gate01/75/Internals-of-Presto-Service-37-2048.jpg)

![Hog Query
• Queries consuming a lot of CPU/memory resources
– Coined in S. Krompass et al. [EDBT2009]
• Example:
– select 1 as day, count(…) from … where time <= current_date - interval 1 day
union all
select 2 as day, count(…) from … where time <= current_date - interval 2 day
union all
– …
– (up to 190 days)
• More than 1000 query stages.
• Presto tries to run all of the stages at once.
– High CPU usage at coordinator
40](https://image.slidesharecdn.com/2015-03-11-tdtechtalk-internalsofprestoservice-150315233656-conversion-gate01/75/Internals-of-Presto-Service-40-2048.jpg)
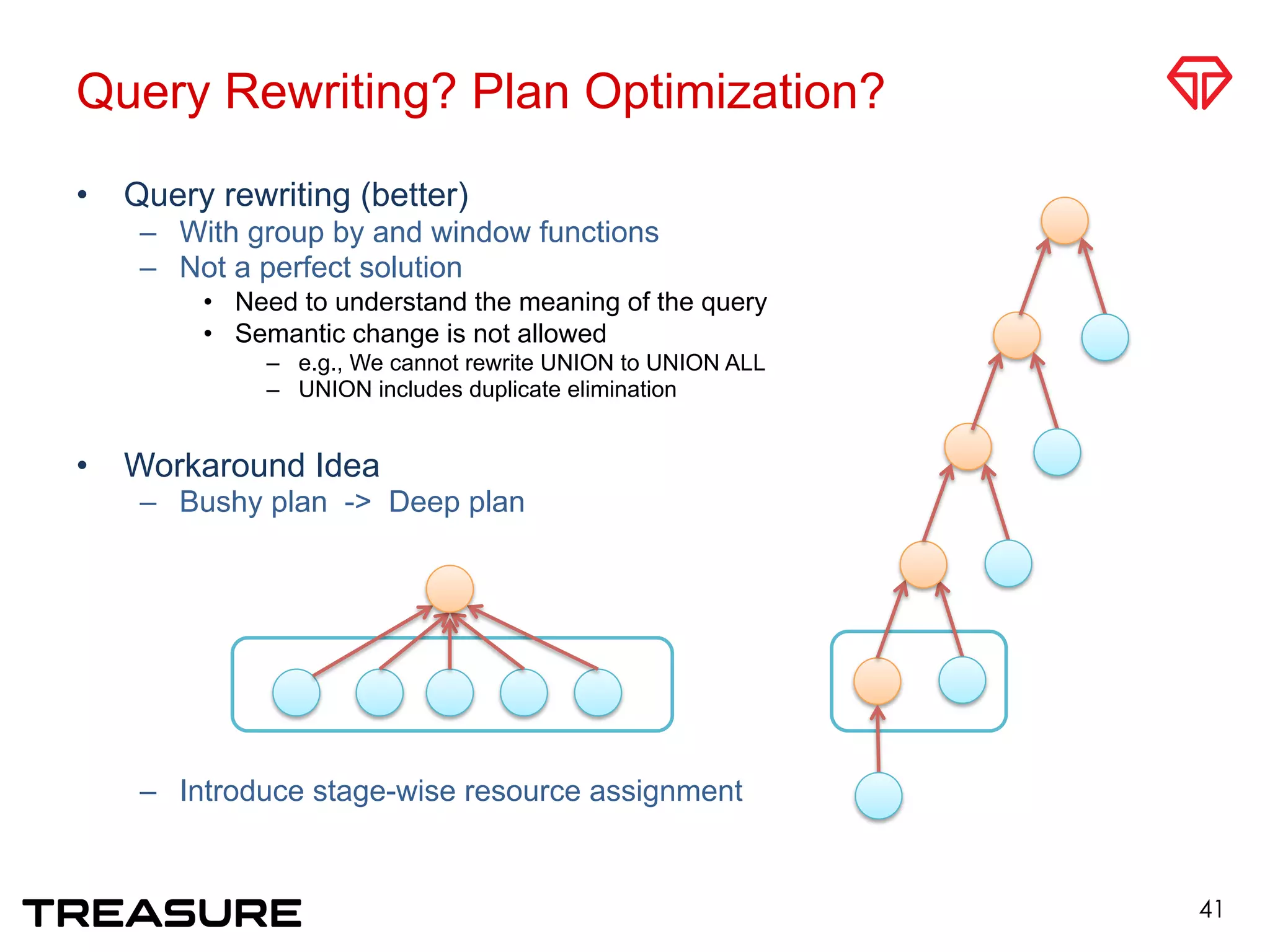
![Future Work
• Reducing Queuing/Response Time
– Introducing shared queue between customers
• For utilizing remaining cluster resources
– Fair-Scheduling: C. Gupata [EDBT2009]
– Self-tuning DBMS. S. Chaudhuri [VLDB2007]
• Adjusting Running Query Size (hard)
– Limiting driver resources as small as possible for hog queries
– Query plan based cost estimation
• Predicting Query Running Time
– J. Duggan [SIGMOD2011], A.C. Konig [VLDB2011]
42](https://image.slidesharecdn.com/2015-03-11-tdtechtalk-internalsofprestoservice-150315233656-conversion-gate01/75/Internals-of-Presto-Service-42-2048.jpg)

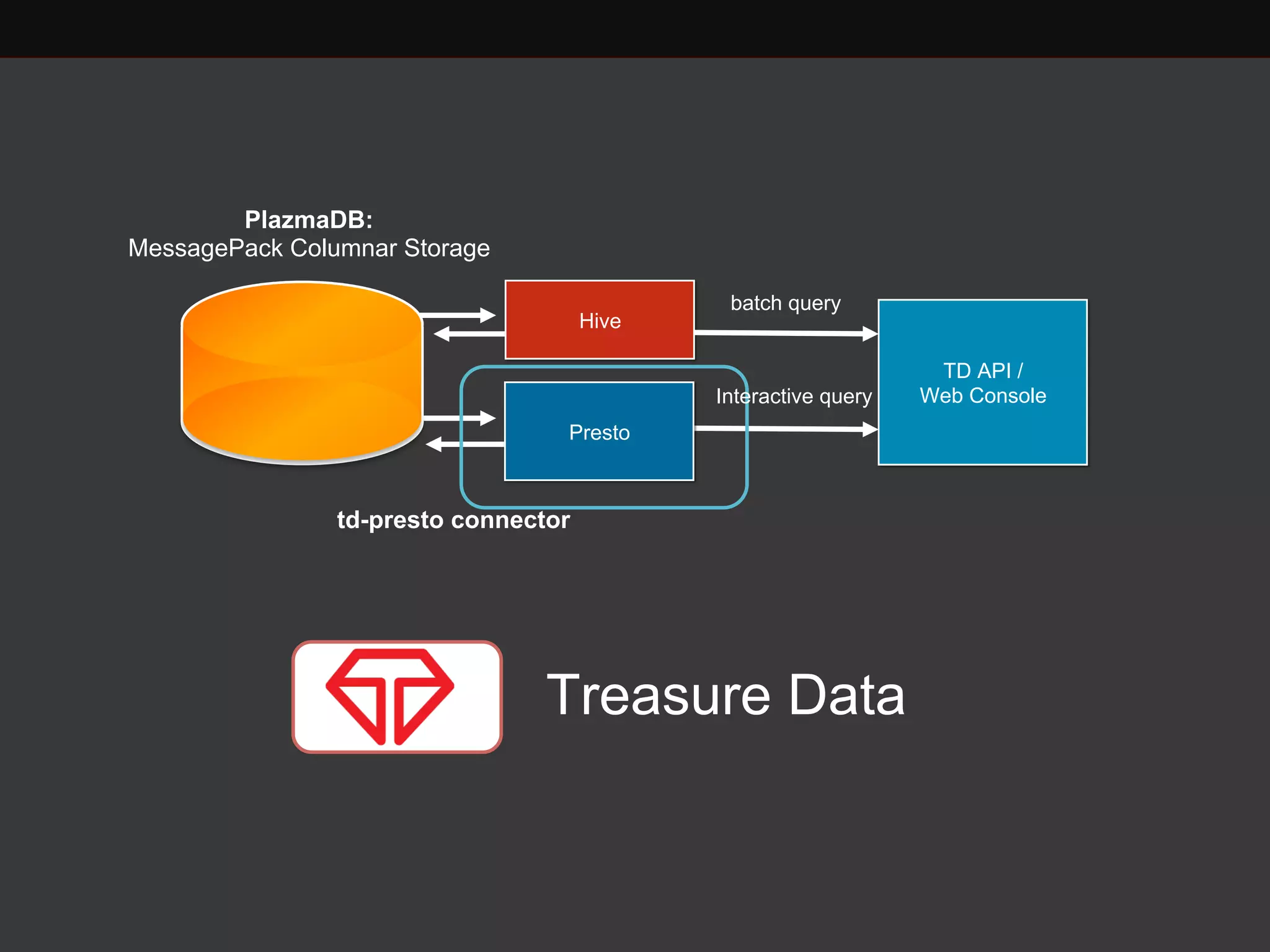
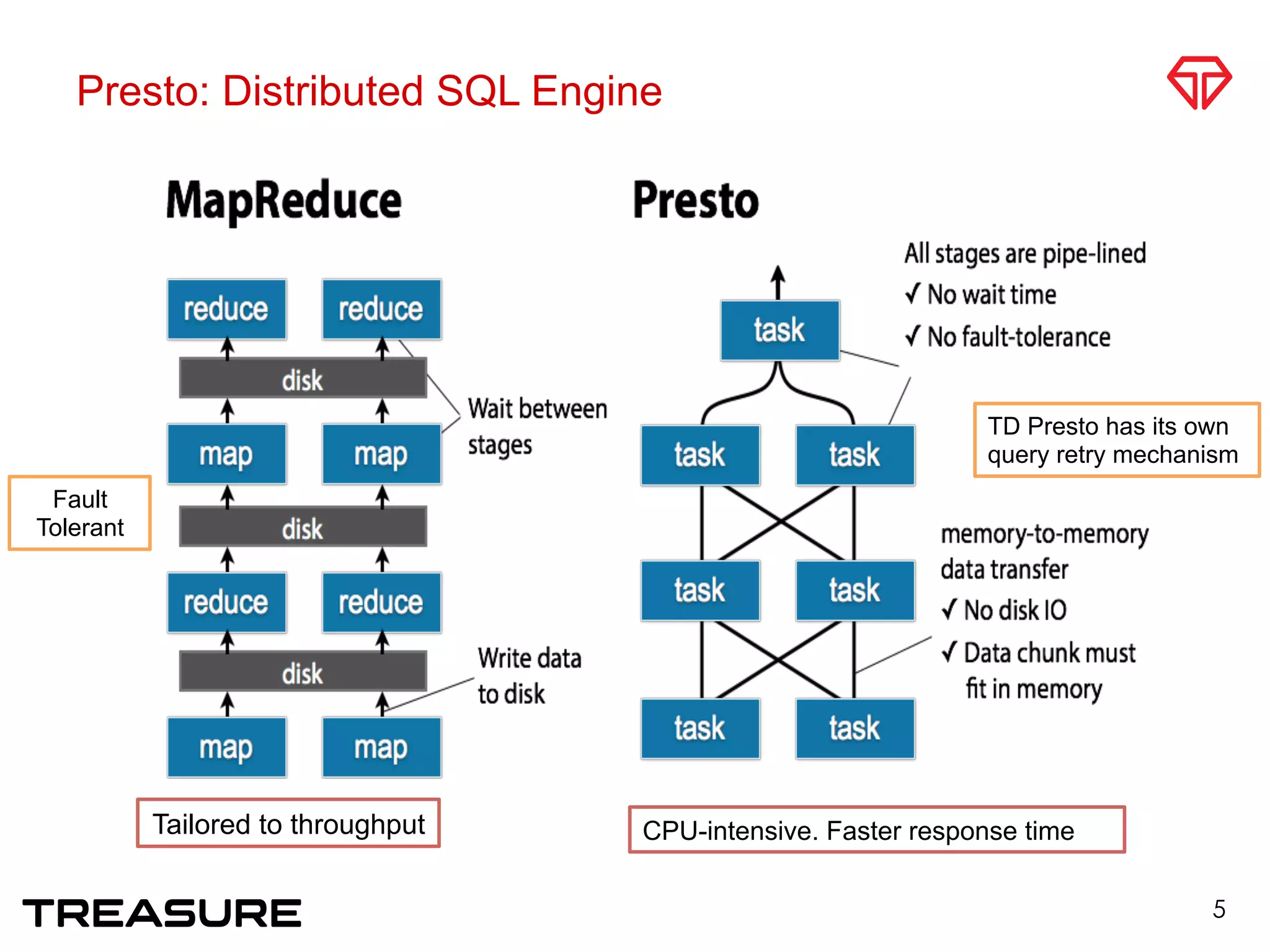
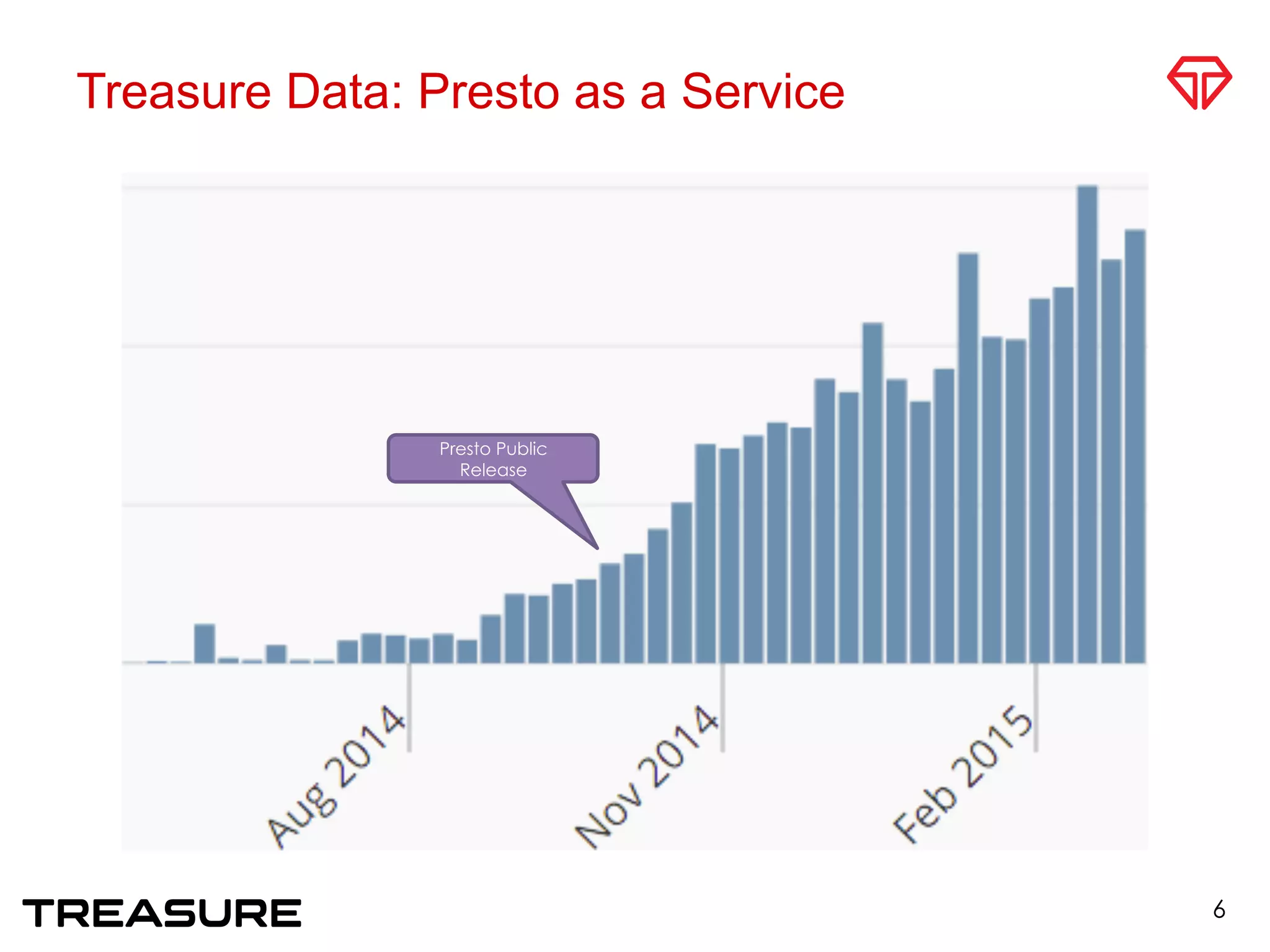
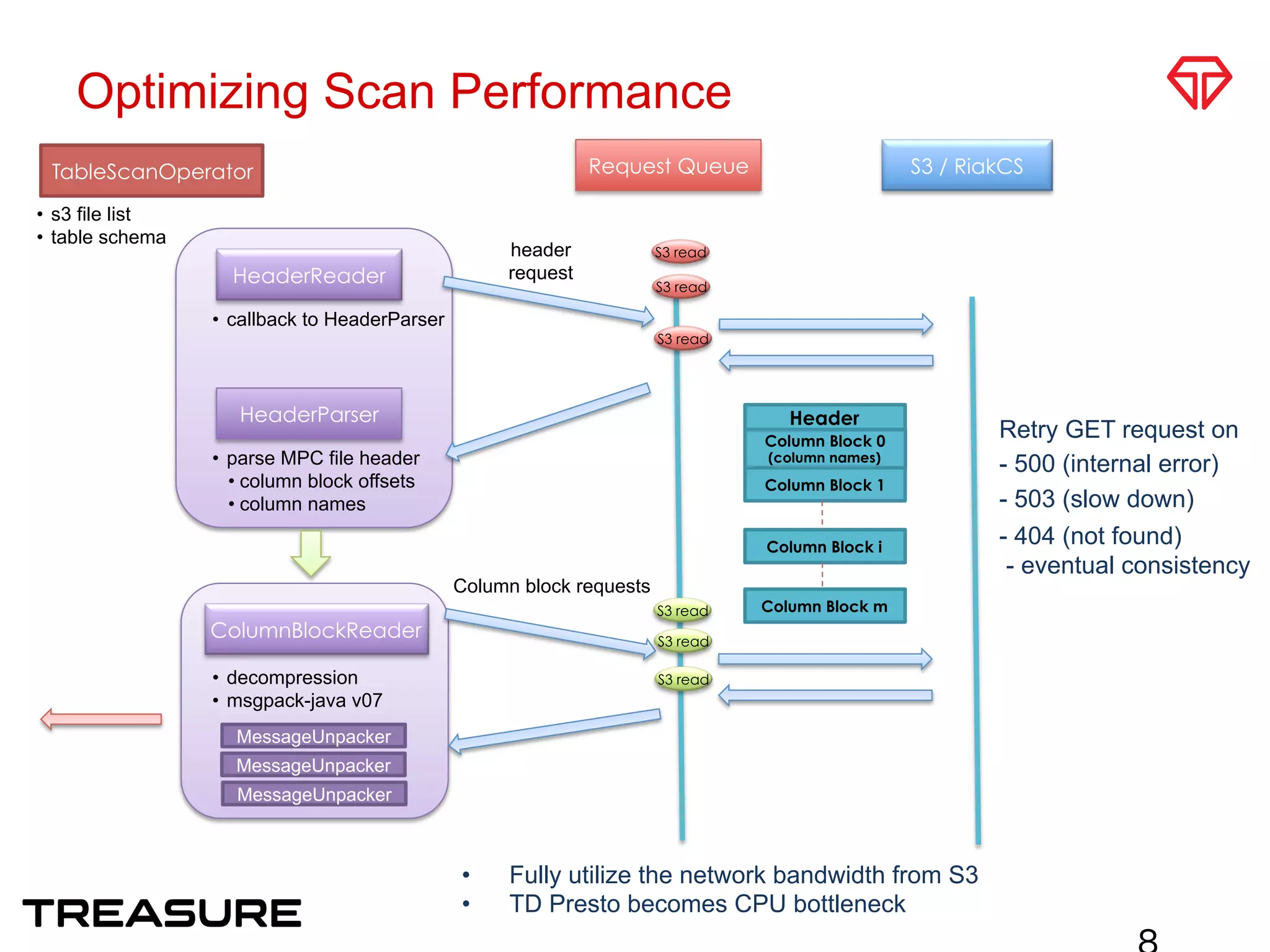
Presto is a distributed SQL query engine that Treasure Data provides as a service. Taro Saito discussed the internals of the Presto service at Treasure Data, including how the TD Presto connector optimizes scan performance from storage systems and how the service manages multi-tenancy and resource allocation for customers. Key challenges in providing a database as a service were also covered, such as balancing cost and performance.












![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)













![[JAWS DAYS 2019] Amazon DocumentDB(with MongoDB Compatibility)入門](https://cdn.slidesharecdn.com/ss_thumbnails/jawsdays-2019-190222234012-thumbnail.jpg?width=640&height=640&fit=bounds)















































































