Download as PDF, PPTX




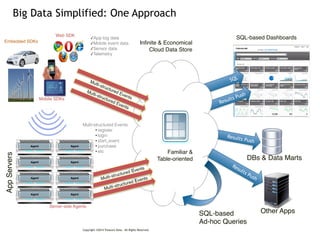


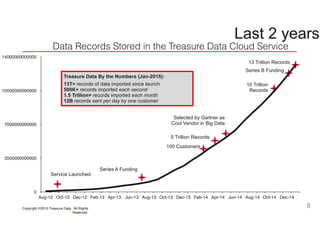




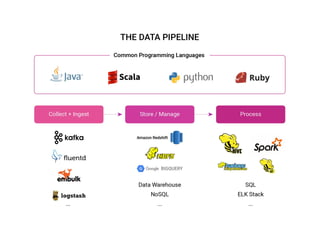


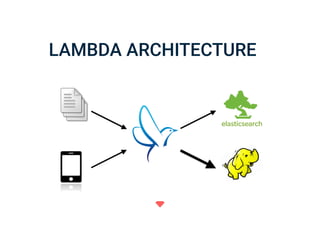
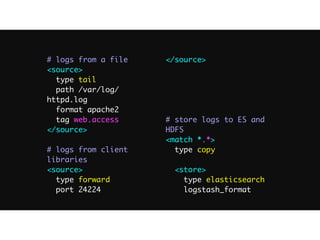

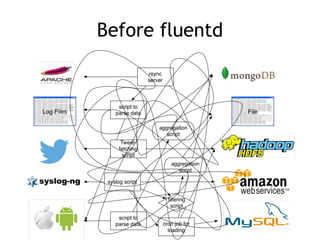

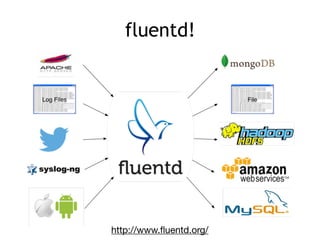


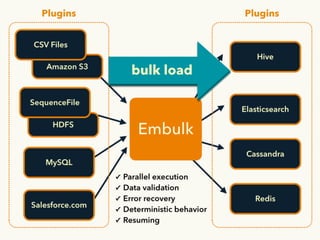
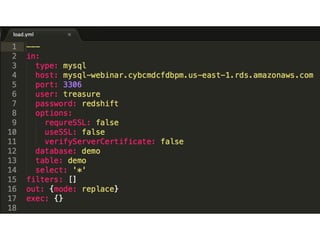

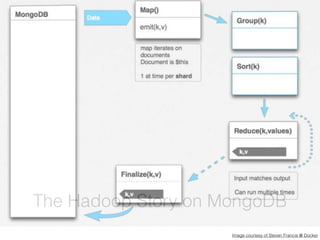


The document discusses the challenges and solutions associated with managing unstructured and semi-structured data, emphasizing the scalability of cloud data storage. It highlights the performance trade-offs involved in using open-source versus closed-source technologies for data management and processing. Additionally, it mentions various tools and libraries such as Fluentd and Hivemall that facilitate data transfer and machine learning integration.










































































































