Download as PDF, PPTX





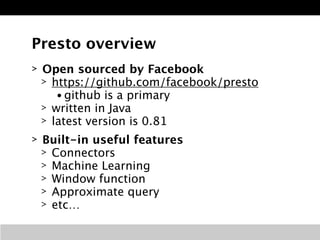





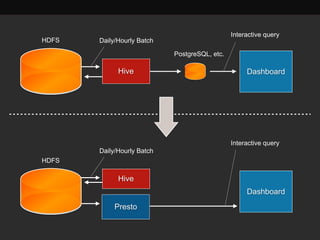




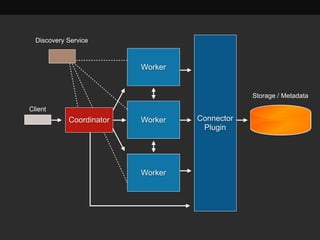

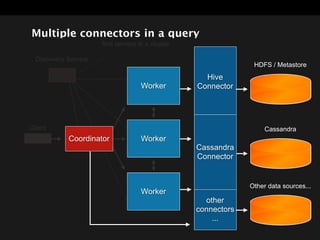


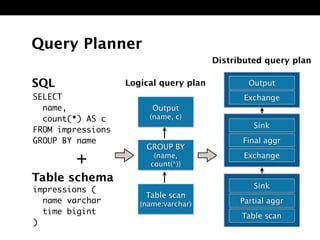
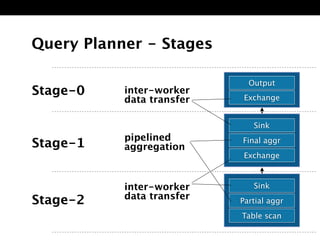
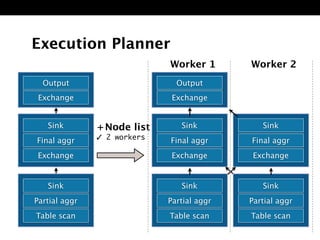
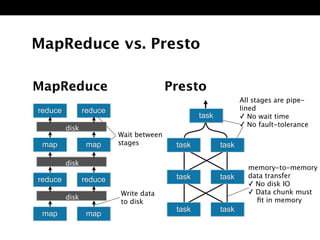




The document discusses Presto, an open source distributed SQL query engine for interactive analysis of large datasets. It provides summaries of Presto's capabilities, architecture, and how it addresses issues with other SQL engines on Hadoop like Hive being too slow. Key points include that Presto allows direct querying of data in HDFS without needing to copy it elsewhere, uses a distributed query execution model rather than MapReduce, and supports many connectors and a PostgreSQL gateway.


























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




