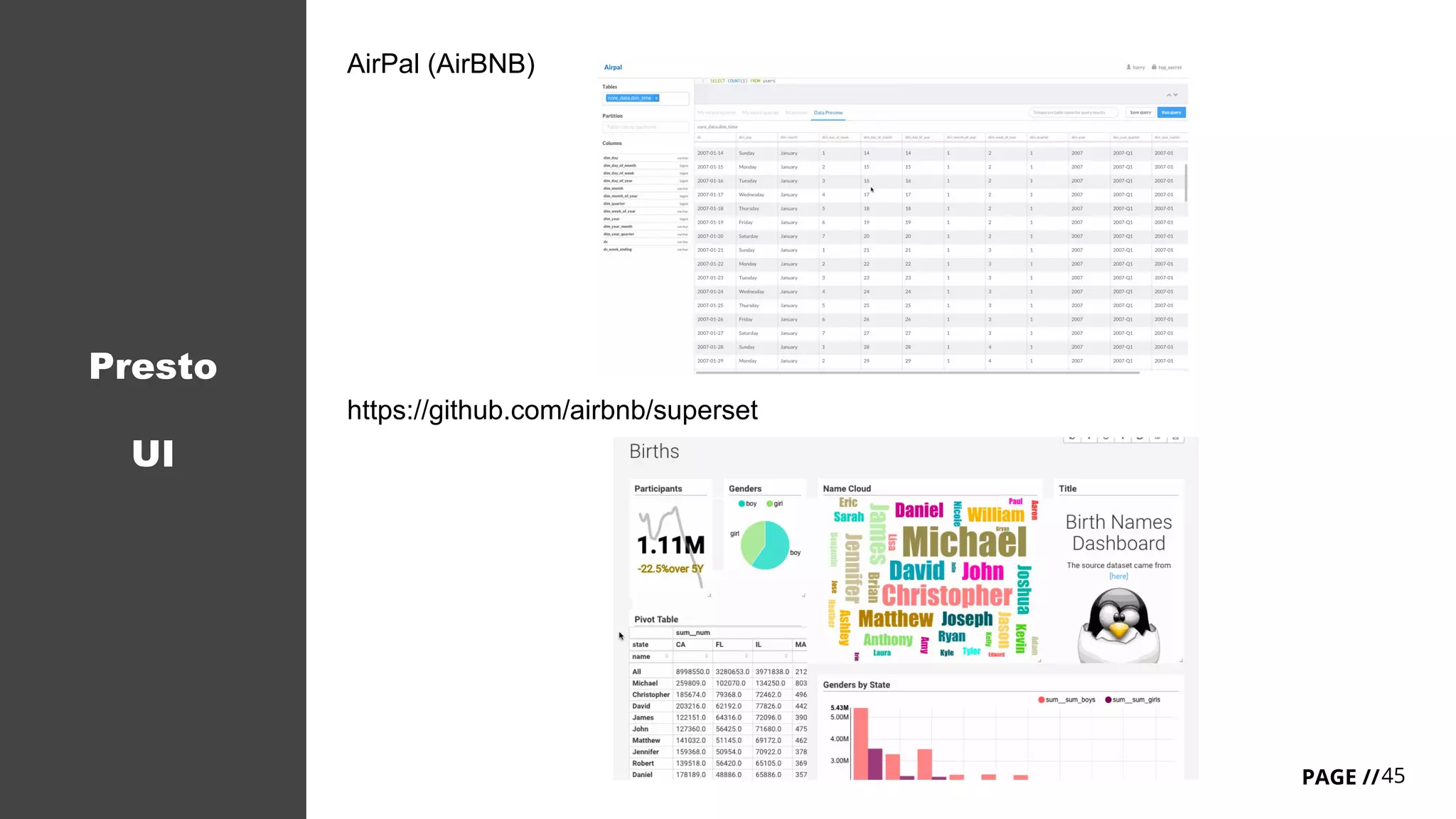
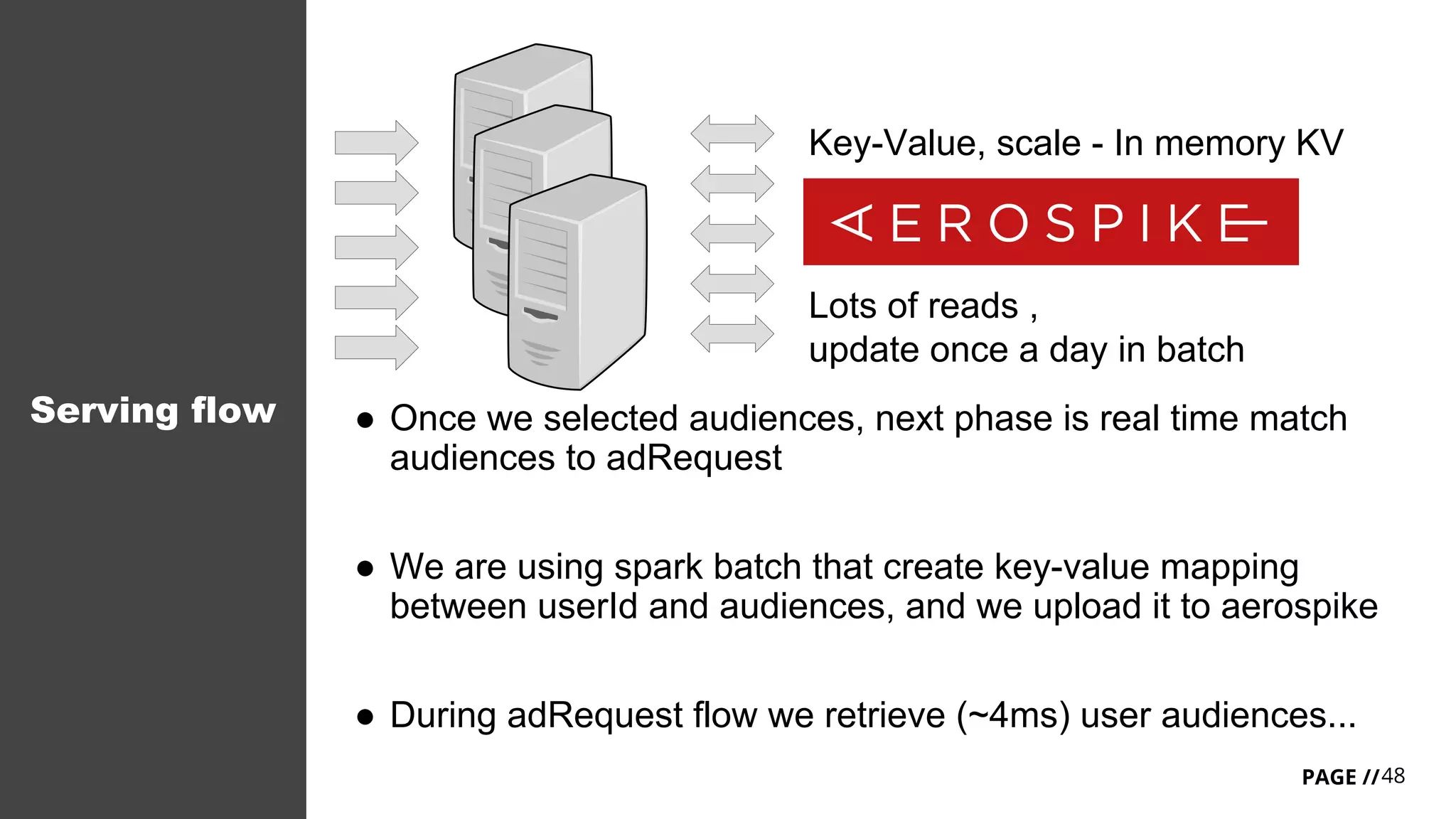
Download as PDF, PPTX




















![26PAGE //
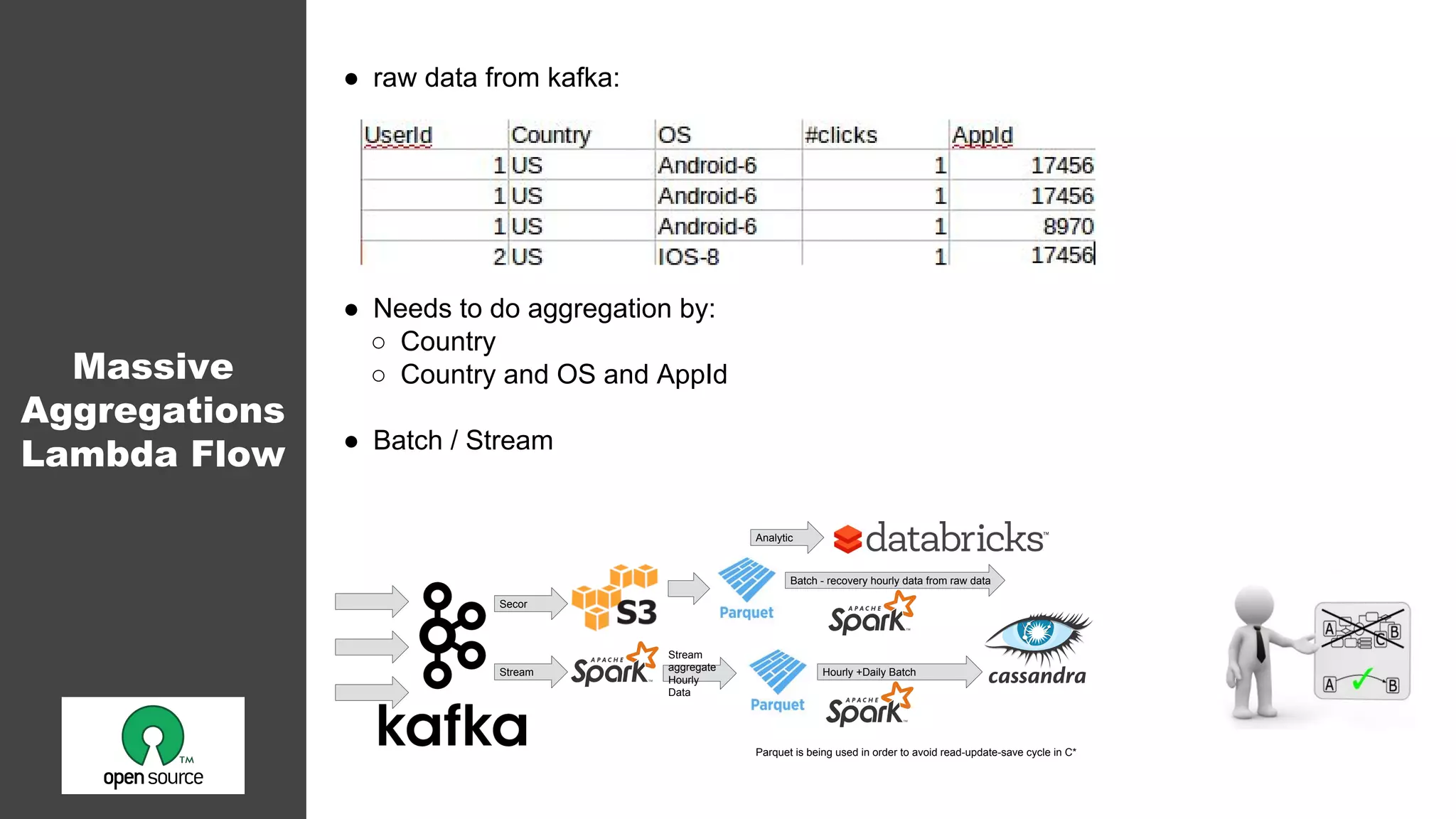
Raw Data
● 120 columns with:
○ Dimensions: Age, Gender, Country
○ Metrics: #Clicks, #Impressions, #Video
● 20 columns with MultiValue Dimensions:
○ Domains: [CNN.com, Ebay.com]
○ Interests: [Sport, Shopping, Cars]
● Checking if DB support advanced feature for future
requirements like Map:
{#number of clicks per domain}
in addition to total number of clicks that the user is doing
2](https://image.slidesharecdn.com/bigdata1-170321085519/75/Big-data-should-be-simple-26-2048.jpg)
















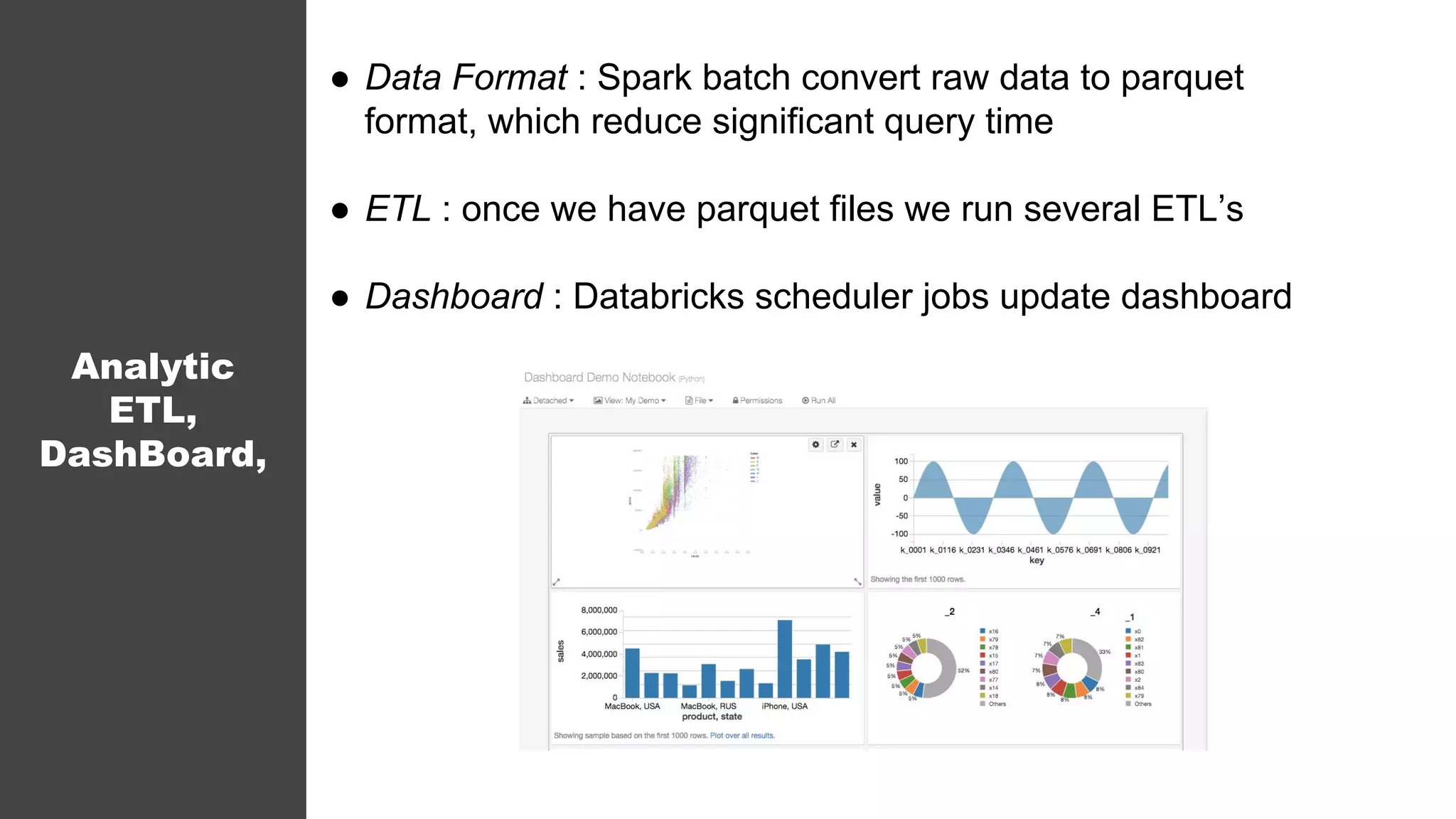
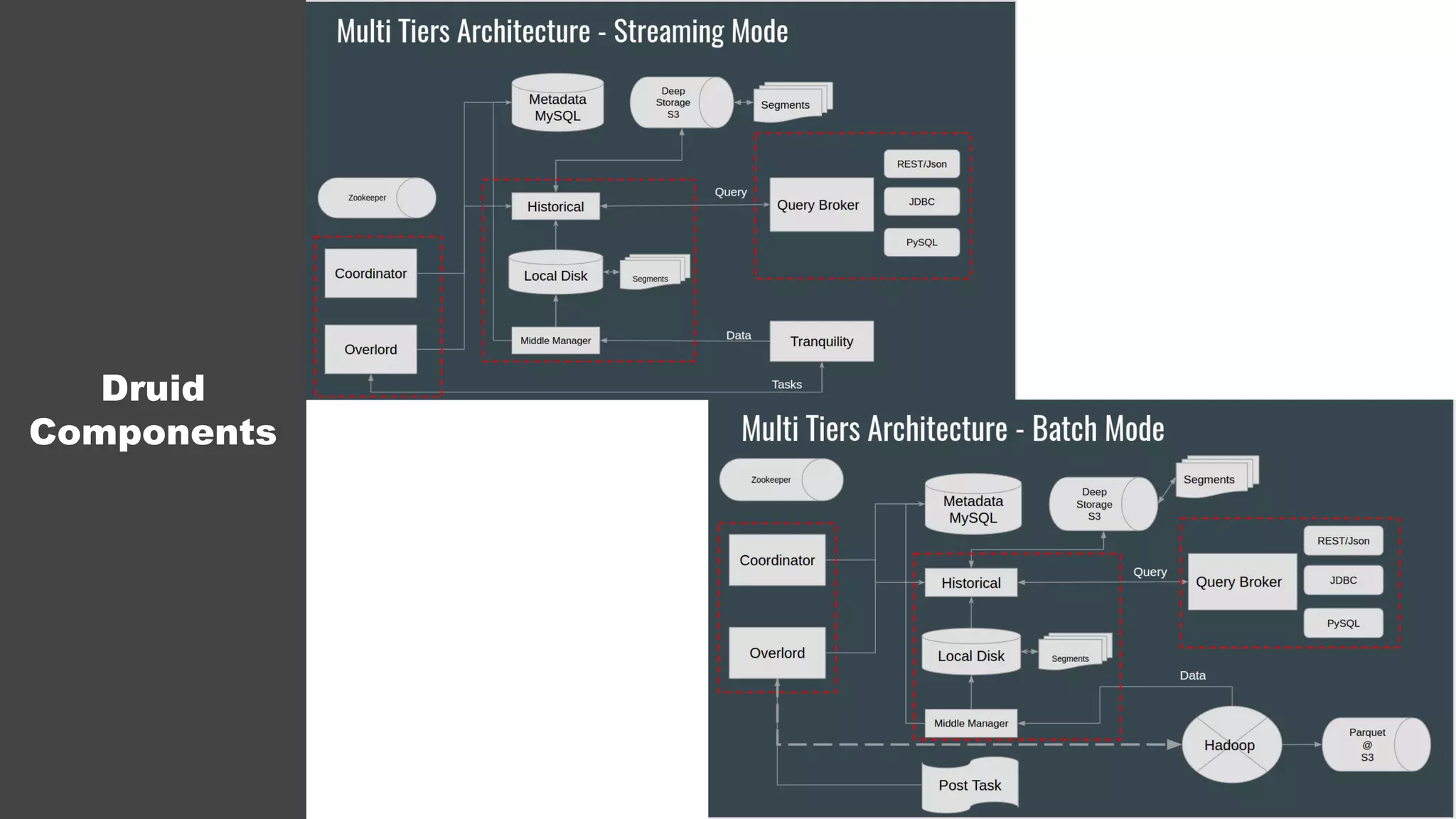
The document discusses the architecture and challenges faced by Inneractive in processing big data for ad requests, emphasizing the need for real-time analytics and audience targeting. It details the technical solutions implemented, such as using Spark for data processing, various data aggregation methods, and the selection of databases suited for large-scale, low-latency queries. The emphasis is on achieving efficiency and effective audience segmentation while addressing issues like data recovery and anomaly detection.






































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



