Downloaded 15 times






























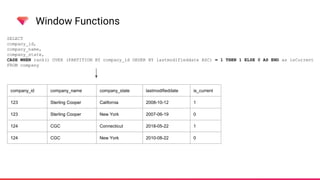


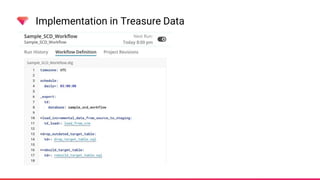

















The document discusses managing Slowly Changing Dimensions (SCDs) using Treasure Data's CDP and workflows. It outlines the types of SCDs, including Type 1, Type 2, Type 3, and Type 4, and explains the advantages of using Treasure Data workflows for data orchestration and error handling. Additionally, it provides practical implementations and examples of using window functions to effectively manage SCDs within the platform.









































































![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)



