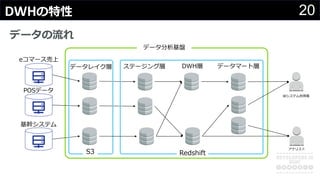
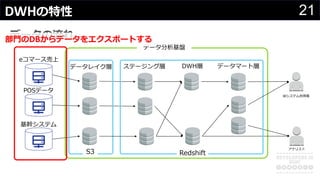
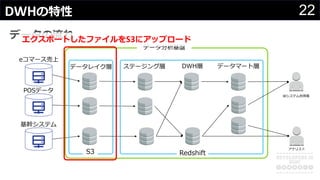
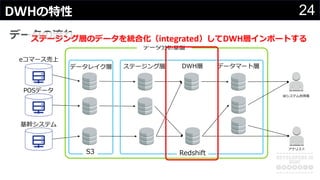
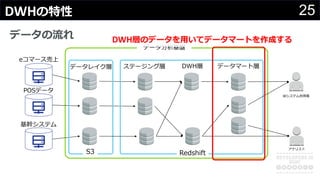
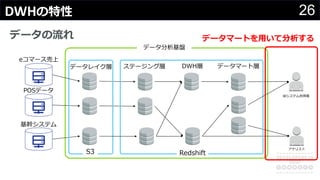
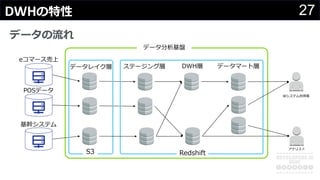
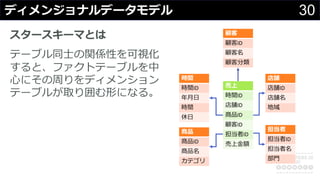
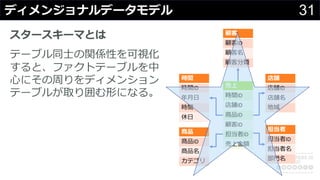
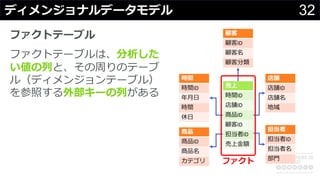
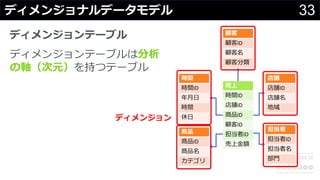
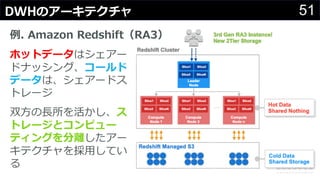
分かりそうで分からないDWH、何のために導入して、どのようにデータを管理・蓄積するのか、どうやって利用するのか、普通のDBと何が違って、アーキテクチャどうなっているかなど、コンサルの現場でよく尋ねられる疑問について解説します。