Download as PDF, PPTX





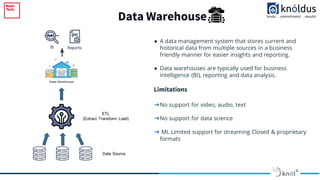
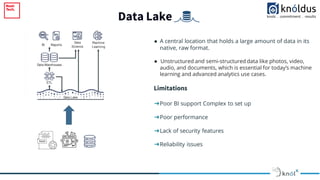
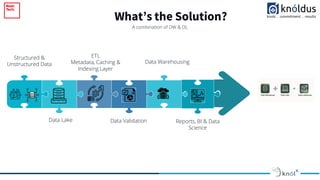
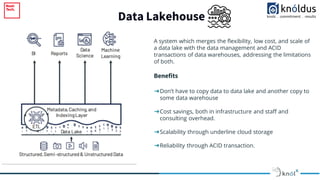
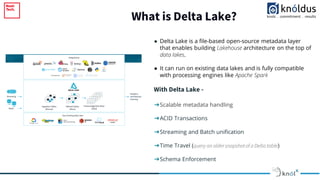
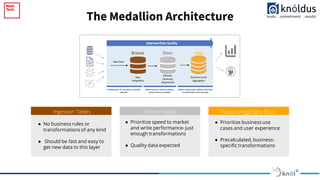


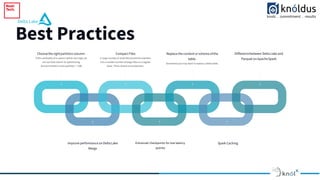


The document outlines an introduction to Delta Lake and its importance in modern data architecture, highlighting its role in combining the flexibility of data lakes with the reliability of data warehouses. It discusses the features of Delta Lake, such as ACID transactions, schema enforcement, and scalability, along with best practices for implementation. Additionally, it emphasizes the significance of etiquette during sessions, including punctuality and providing constructive feedback.








![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

