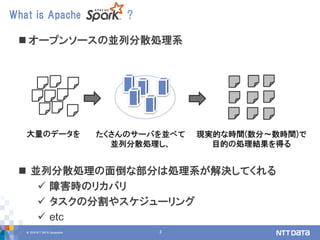
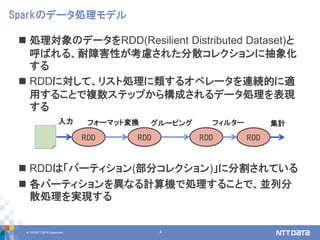
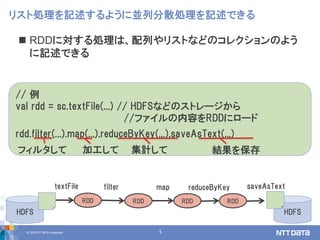
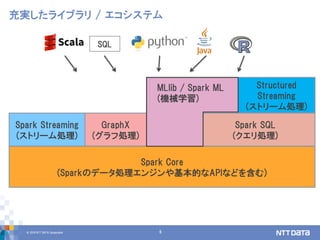
Apache spark 2.3 and beyond (2018/09/20, db tech showcase講演資料) 株式会社NTTデータ / NTT DATA 技術開発本部 先進基盤技術グループ 猿田 浩輔





































![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)
























