Download as PDF, PPTX


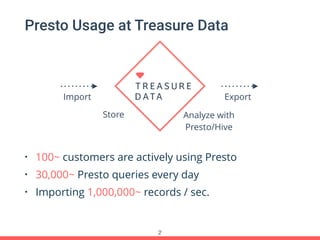
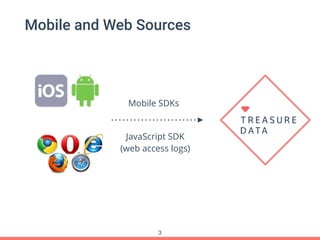
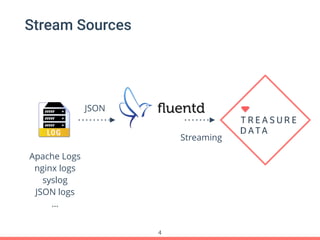
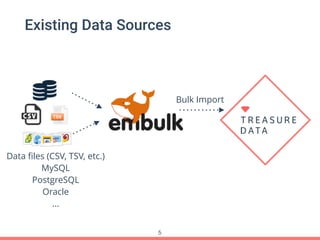
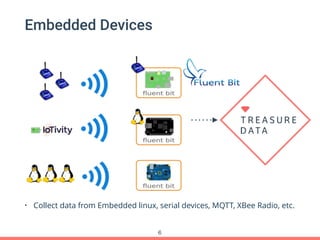

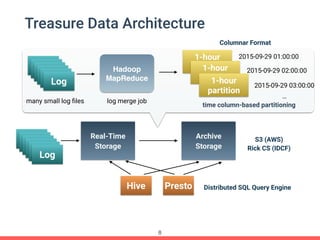


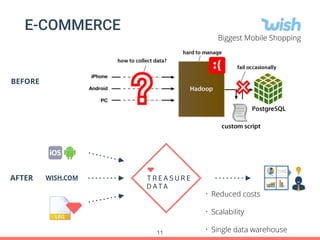
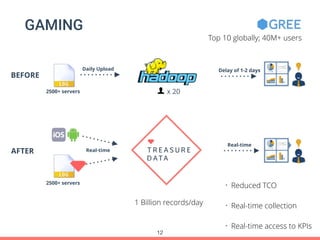
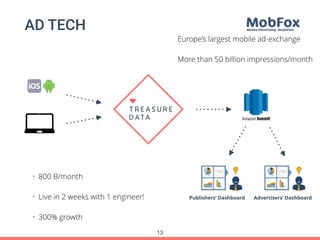
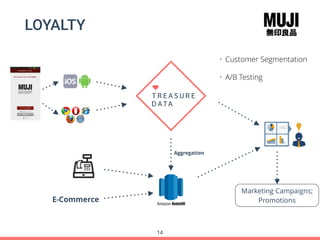

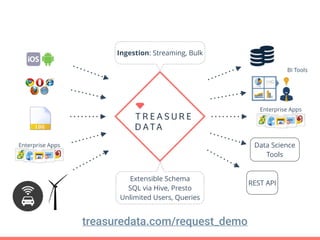

Treasure Data's Presto service is utilized by around 100 customers, processing approximately 30,000 queries daily and importing about 1 million records per second from various data sources. The document outlines its architecture, real-time capabilities, and use cases in e-commerce, gaming, and ad tech, highlighting successes such as reduced costs and improved scalability. Challenges include managing large query outputs and the need for enhanced query planning and resource management.























































































