Download to read offline














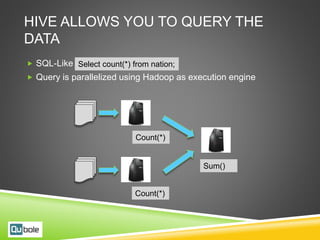
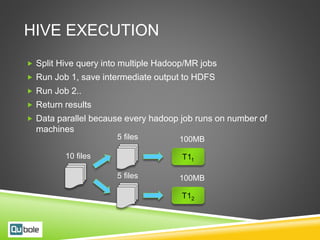
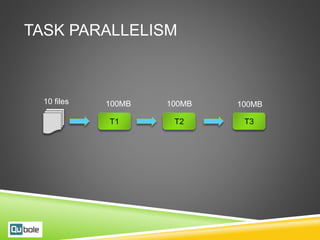
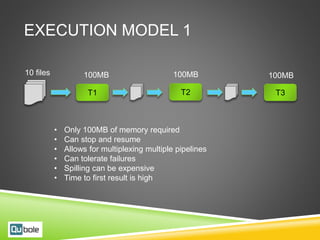
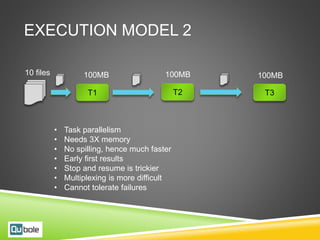


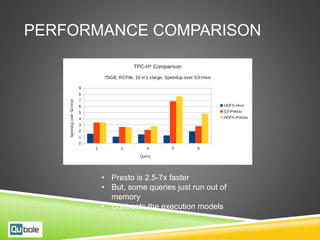

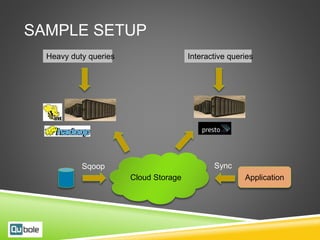



This document discusses Hive and Presto for big data analytics in the cloud. It provides an overview of how big data has evolved from traditional analytics on internal data to using new external data sources at larger scales. It describes how the public cloud has changed the economics and flexibility of big data projects by providing cheap storage, elastic compute, and open-source big data software like Hadoop, Hive, and Presto. It compares Hive, which uses Hadoop MapReduce for execution, to Presto, which uses an in-memory pipelined execution model, and shows how Presto can provide faster performance for interactive queries.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















