Download as PDF, PPTX


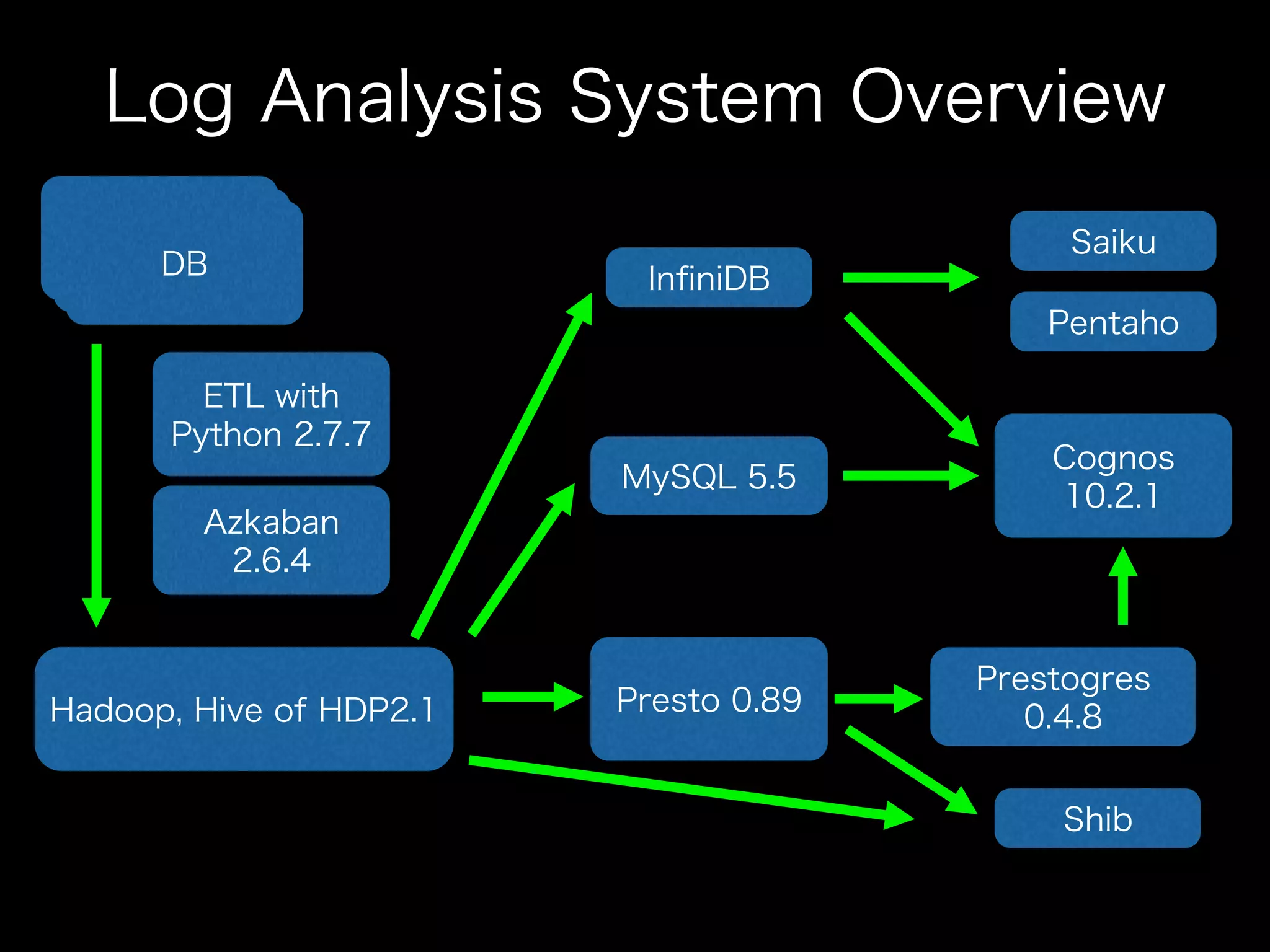



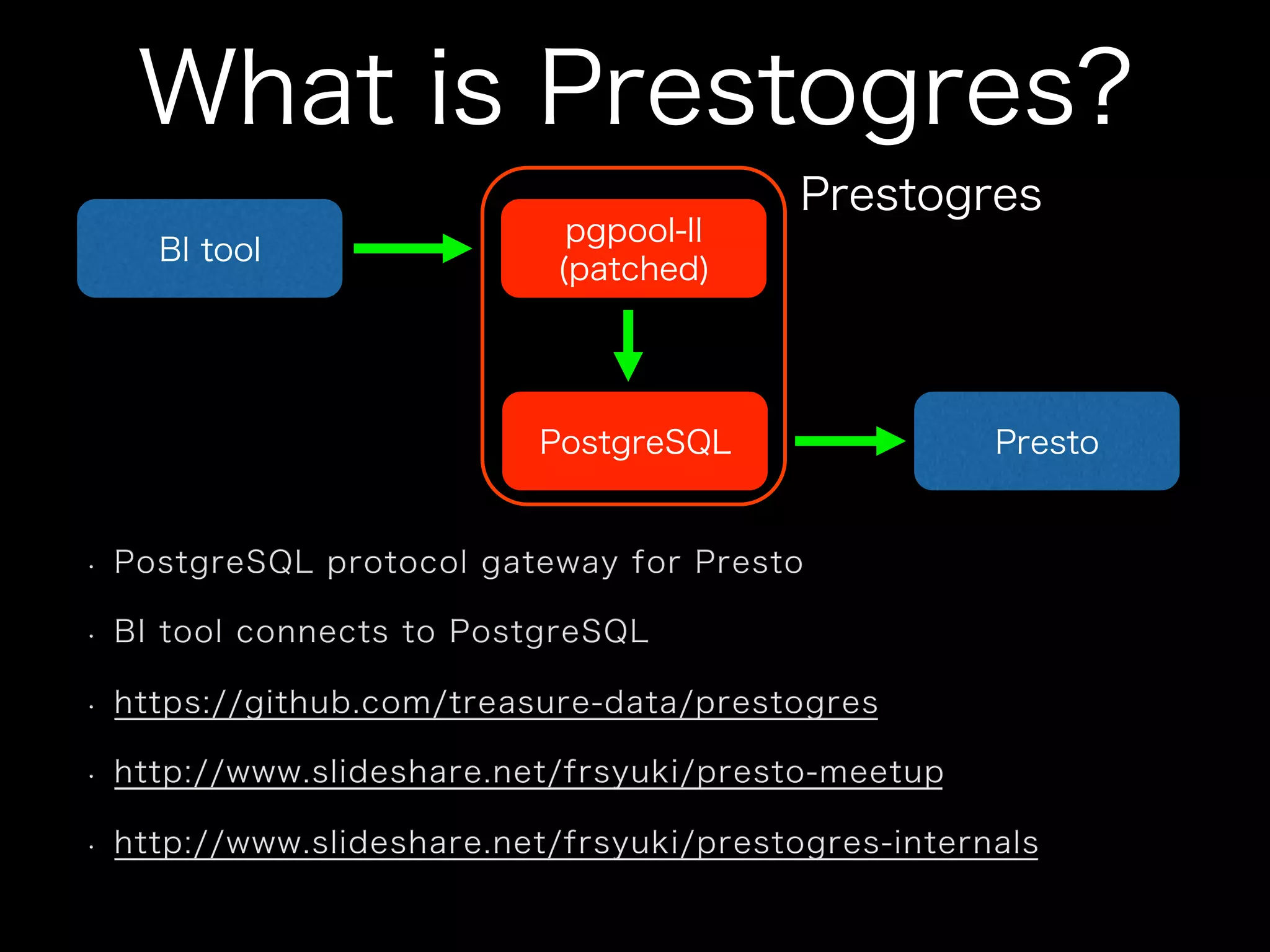






The document summarizes the speaker's use of Presto for log analysis. Key points include: - Presto was selected due to familiarity from others and ease of use compared to other options. - Presto is used for batch queries with Hive and interactive queries. Results are accessed through Cognos using Prestogres. - Managing Presto involves deployment with Ansible, configuration tuning, and monitoring with tools like GrowthForecast and jstat2gf. - While Presto has been stable overall, the speaker notes some version upgrade issues but sees leverage from its frequent updates.




























![[db analytics showcase Sapporo 2017] A15: Pythonでの分散処理再入門 by 株式会社HPCソリューションズ ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase-sapporo-2017-iisaka-170707075724-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















