Download as PDF, PPTX












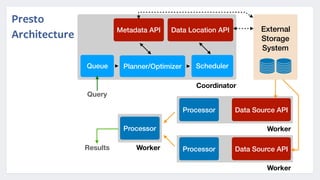


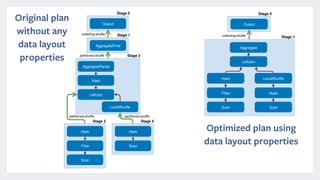


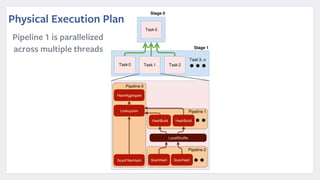



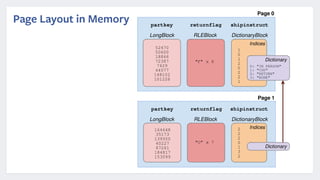


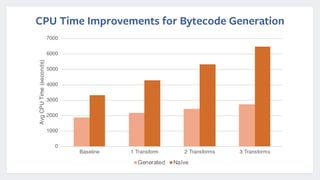



Presto is an open source distributed SQL query engine that was originally developed by Facebook. It allows for fast SQL queries on large datasets across multiple data sources. Presto uses various optimizations like code generation, predicate pushdown, and data layout awareness to improve query performance. It is used at Facebook and other companies for interactive analytics, batch ETL, A/B testing, and app analytics where low latency and high concurrency are important.



































































